This course was created with the intention of training you to become a Hadoop expert who handles big data. Rather than using a comprehensive on-premise distribution software application (OPD) like Cloudera, we will move you to the step of installing Hadoop from scratch, extracting, moving, and loading datasets. Hadoop, which started from version 1.x, has now become a very heavy platform with many features added up to version 3.3, but I hope that this course will be filled with the desire to train you to become a big data expert by handling many tools.
5.0
상냥한 날다람쥐
100% enrolled
Pros:
You can learn the basics of Hadoop MapReduce.
It seems to be the only Hadoop lecture in Korean.
Disappointing points:
I was disappointed that there was no content I was curious about, such as extracting with one common key using two mappers,
when using two keys,
how to set the comparator directly,
and so on.
Cons:
The instructor's Korean pronunciation is not clear, and the background music is loud, so I had to listen to what he was saying several times.
---------------------------------------
I will change the rating to 5 stars after seeing the teacher's answer.
5.0
김태경
59% enrolled
It's good for Hadoop beginners. It seems like a good idea to learn it first before reading the book.
What you will gain after the course
Encountering big data technology in everyday life
Handling Big Data with Hadoop
Learn distributed processing technology for handling big data with Hadoop
Handling Hadoop Big Data Using Java Language
Learn techniques to overcome the limitations of relational data processing with Hadoop
Learn about Hadoop's various projects and interfaces.
It's the era of big data! 👨💻 Become an expert with Hadoop.
The center of data science, Hadoop is the trend!
Many IT giants, social media services, and others are competing to use Hadoop (Apache Hadoop) for big data analysis and processing. Hadoop is a Java-based framework designed to process massive amounts of data at low cost, enabling distributed storage and processing of large data sets. But what if you could achieve the level of a big data expert through Hadoop?
Through data analysis, companies will be able to pioneer new markets, create unique value, and provide new consumers with the thrill of real-time access to essential information. Big data is also a crucial skill for small and medium-sized businesses, so this is welcome news for those seeking employment or a career change in big data .
BigData with Hadoop
Google, Yahoo, Facebook, IBM, Instagram, Twitter, etc. It is being used by many companies for data analysis. Through Hadoop, a representative big data solution Let's build a big data distributed system infrastructure .
This course begins with an understanding of big data terminology and then provides an indirect experience of handling big data using the open source software Hadoop . Through this course, students will simultaneously experience the world of big data technology and the Fourth Industrial Revolution.
What is Hadoop?
Hadoop is open source software that anyone can use for free. In this lecture, we will cover big data using Hadoop version 3.2.1 .
Understanding big data How to use Hadoop OK at once.
Big data About the term Essential Understanding
Hadoop 's In concept and use Introduction to Korea
Through Hadoop Big data processing Learning Tutorials
I recommend this to these people!
Of course, those who don't fit this category are also welcome. (Beginners are doubly welcome ✌)
Employment/Job Change Future IT in consideration Data science aspirants
Via Java/Python I want to deal with big data Those who do it
With interest and curiosity About big data Anyone who wants to experience it
Hadoop 3.x version Data environment, etc. Office worker who wants to experience
Before taking the class, please check your knowledge!
Prerequisite knowledge is the basics of the Java programming language, knowledge of big data and virtual machine/dataset related terminology , and a basic understanding of Linux Ubuntu .
The following content I'm learning.
1. Understanding virtualization technology challenges and guest operating systems
We will learn virtualization technology, which is advantageous for server consolidation, and how to isolate multiple servers with a single OS through OS-level virtualization. Anyone can take on the challenge of creating and operating a large number of servers using Ubuntu, an open-source solution that supports Linux virtualization. Furthermore, we will gain knowledge of guest operating systems and gain extensive technical experience in distributing big data across multiple servers. Using server virtualization, you can experience multiple operating systems running on a single physical server or operating system in a highly efficient virtual machine.
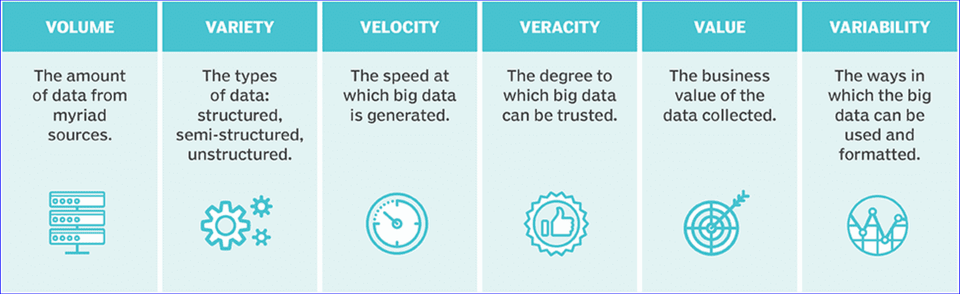
Learn about the definition of Big Data and its practical applications.
Let's understand the terminology related to Hadoop, the data processing software preferred by businesses.
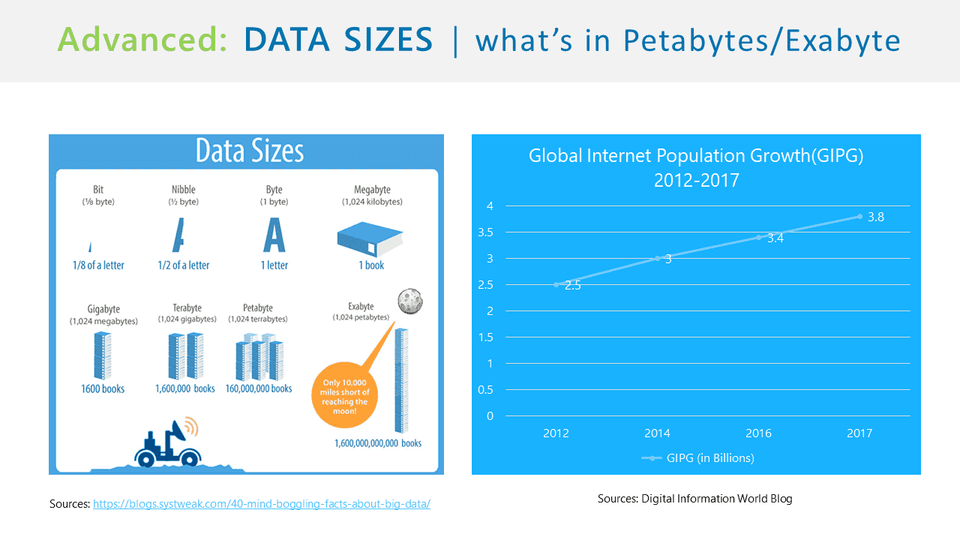
Data Sizes
The Landscape: Big Data
2. How to install Hadoop on Ubuntu 20.04 LTS and use commands
We'll cover the basics of using the Linux CLI (Command Line Interface) tools that front-end developers naturally encounter when developing web applications, and then seamlessly transition to the Linux terminal for Hadoop. Furthermore, we'll cover the basics of using Ubuntu in a non-Windows GUI environment, moving beyond a basic understanding of Linux systems like shell configuration files and moving towards an intermediate level.
Let's install and set up Linux (Ubuntu 20.04 LTS) as a virtual machine on a Windows 10-based laptop.
Install Hadoop version 3.2.1 on a Linux virtual machine.
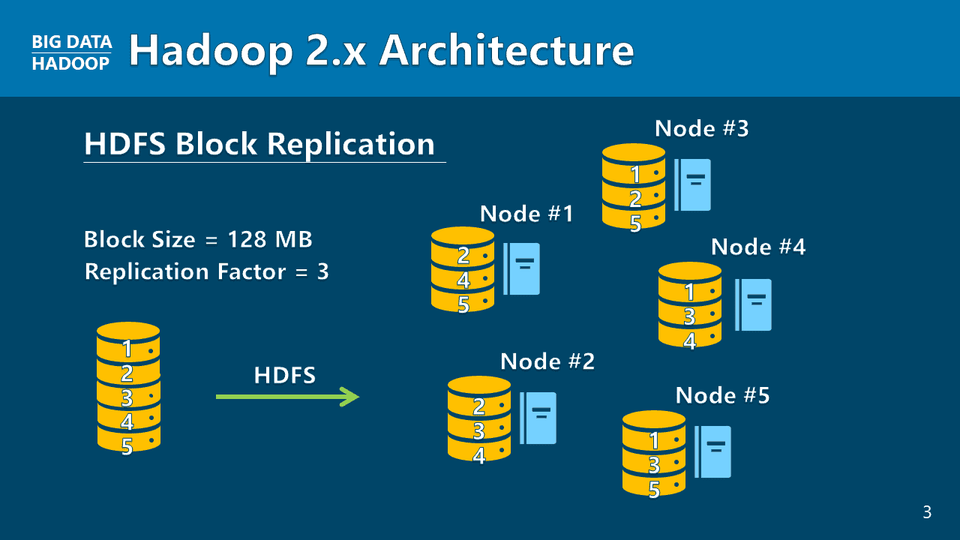
Hadoop 2.x Architecture
Hadoop 2.x vs. 3.x
3. Hadoop 3.2.1 Latest Direction Guide & Understanding the Core Architecture Structure
The starting point for big data processing for unstructured data is understanding the Hadoop Distributed File System (HDFS), a model of Google's file system, MapReduce, and YARN for cluster scaling and resource management. We will examine the architectural structures of Hadoop versions 1, 2, and 3 one by one, providing students with a visual representation of the history of Hadoop technology.
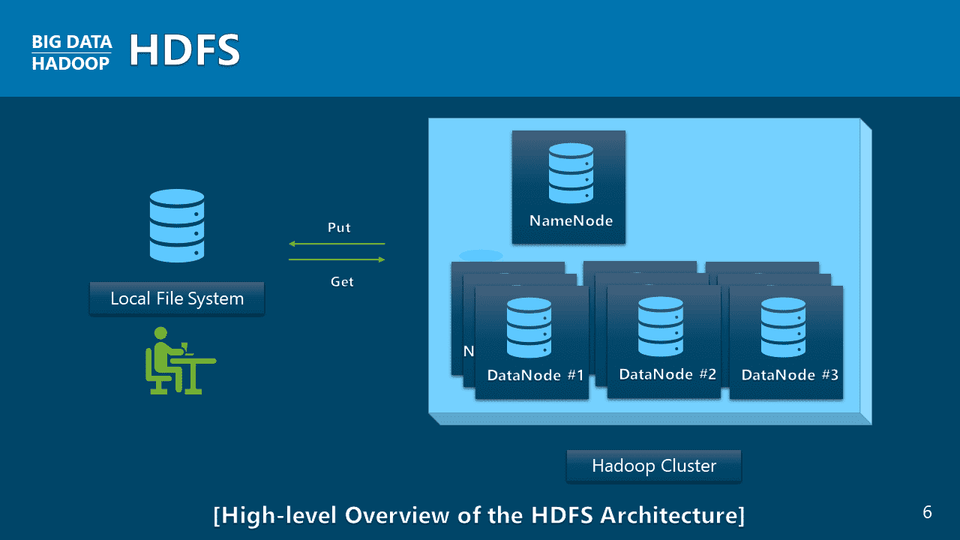
Understand and integrate with the Hadoop Distributed File System (HDFS).
Understand the principles of the Map/Reduce framework and analyze data based on it.
HDFS Architecture
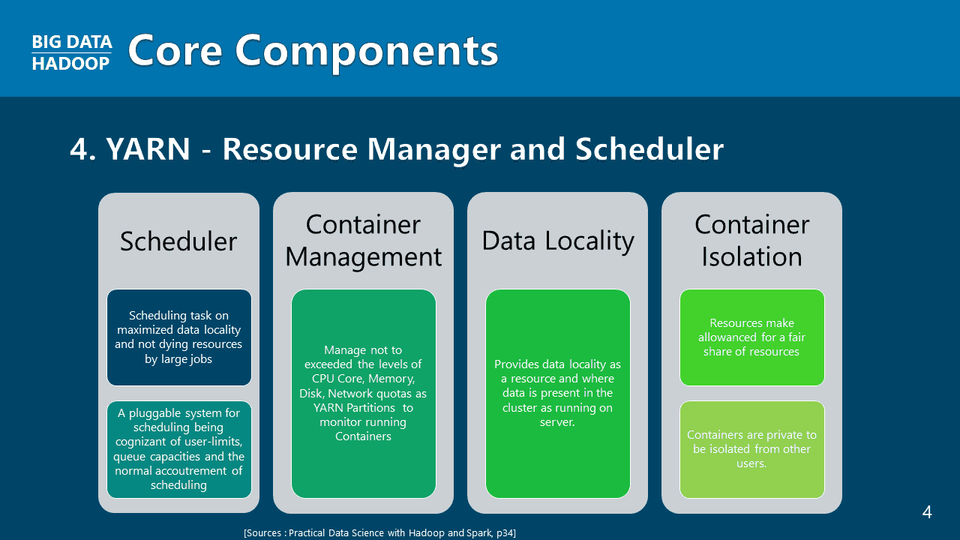
YARN Core Components
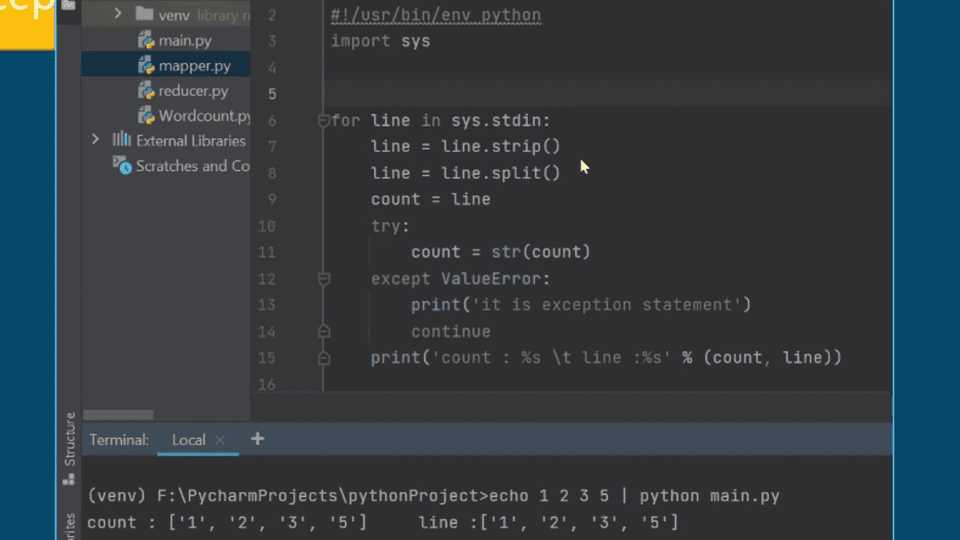
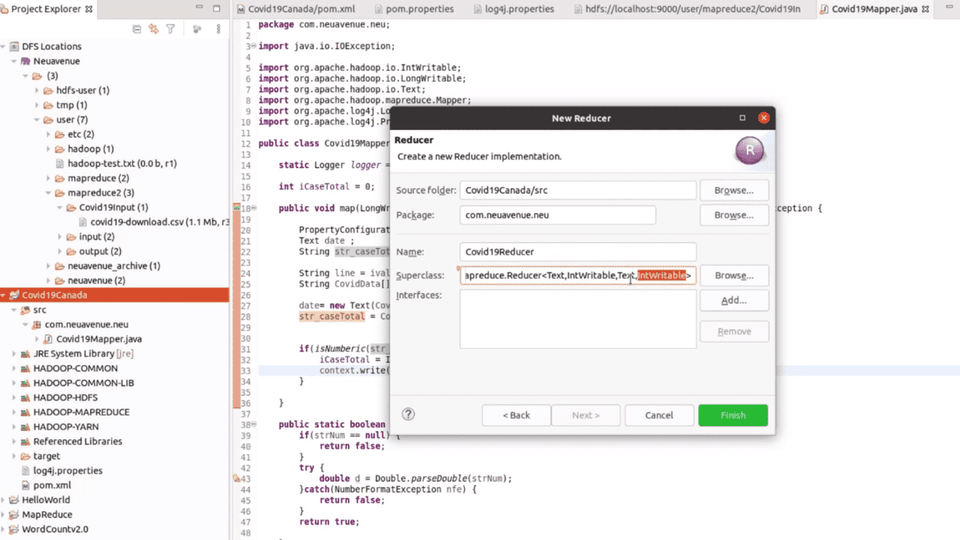
4. HDFS Shell Operation Guide and Building MapReduce Applications with Java/Python
While data manipulation techniques vary, the foundation of big data analysis lies in building MapReduce applications. From a basic wordcount MapReduce application in Python to a COVID-19 application built using Eclipse-based Java, building a variety of big data MapReduce applications is no longer an option; it's a necessary step forward.
Let's connect Hadoop with Java and implement an application.
Let's connect Hadoop with Python and implement an application.
Python Map/Reduce WordCount Application
Java Map/Reduce WordCount Application
Expected Questions Q&A!
Q. What is big data? Is its definition necessary when using Hadoop?
Yes, of course, when working with Hadoop, a brief definition and understanding of big data is required. Of course, this doesn't require a complete and in-depth understanding. However, it does require a level of understanding essential to working with Hadoop.
Big data involves handling extremely large datasets using Hadoop tools. These datasets serve as the foundation for analyzing numerous patterns and trends across numerous businesses. They are closely linked to human social behavior, patterns, and the value creation that occurs through interactions.
Q. What is Hadoop? What are its components? What is the Hadoop stack?
Data from large-scale social sites, ranging from terabytes to petabytes (Zettabytes)Hadoop is helping with this mission. The Hadoop Stack refers to an open-source framework for handling big data.
Simply put, "Hadoop" is called the "Hadoop stack." Hadoop and the Hadoop stack help you build clusters using inexpensive, common commodity hardware and handle large-scale processing within these massive clusters of servers. The Hadoop stack, also known as "simple batch processing," is a Java-based "distributed computing platform." It allows individuals to batch process as much data as they want, periodically, distributing the data in the desired format to produce results.
Q. Is programming knowledge required?
Even if you have no programming knowledge or coding experience, it's okay. I teach with a deep understanding of Java and Python, as if you were experiencing them for the first time. While the lecture documentation is in English, I'll teach in Korean to ensure you can follow along without any difficulties. While I occasionally provide explanations in English, I believe anyone with a high school level will be able to interpret them. (Just like I achieved my dream, even with my limited English skills.)
Q. How relevant is big data to Hadoop?
This course naturally covers Hadoop. Beyond simple RDMSs like Oracle, MSSQL, or MySQL, it aims to address essential business requirements, starting with large-scale processing, data processing speed, and cost-effectiveness. Specifically, Hadoop addresses not only structured data—the relational data handled by row- and column-based RDMSs—but also unstructured data, such as images, audio, and word processing files themselves.
When dealing with service structure data, we're talking about data related to communication and data integration with web servers, such as email, CSV, XML, and JSON. HTML, websites, and NoSQL databases are also included. Of course, the accumulation of datasets used to handle computer-to-computer transfers of business documents, known as EDI, also falls into this category.
This course will guide users through the installation of Hadoop 3.2.1 on Ubuntu 20.04 LTS. Even if you have no prior Unix or Linux experience, you'll naturally learn installation techniques and the Linux operating system. Beyond the basics of Hadoop's CLI and user language, this course will also help you become familiar with Google's proprietary DFS and MapReduce technologies. Your understanding of YARN will be limited to basic theory. We anticipate a more in-depth study of YARN as you install a cluster in the Hadoop 3.3.0 intermediate course.
Q. Is there a reason you are using Ubuntu 20.04 LTS as a practice environment?
Ubuntu is free to use, and its LTS (Long-Term Service) program targets companies seeking long-term service support. By installing Hadoop on Linux, you can naturally build the operating system and development environment your business needs. By supporting the use of Eclipse and Intelligent within the same environment, you can contribute to realizing the dream of data science, which involves big data, right now.
Ubuntu is a Windows operating system that allows installation and operation. Similar environment, i.e. GUI (Graphical User Interface) We are helping users through the environment.
Recommended for these people
Who is this course right for?
Enthusiastic students who want to learn the basics of big data from scratch
For those who are thirsty for big data principles and applications
For those who want to learn Hadoop to handle big data in their companies
After returning to Korea with my family in September 2022, I provided TA consulting for Hyundai Motor Company's Big Data project (from September to November 2022). I also served as a Project Manager (PMO), leading the Hadoop ecosystem, machine learning, and deep learning through Agile PM and the establishment of a Big Data C-ITS system. Subsequently, while working in the Innovation Data Platform team at AIA Life Insurance, I poured my passion into deep exploration as a data scientist, utilizing Azure Data Factory and Azure Databricks for data management technologies.
From 2012 to 2020, I was a dedicated student who graduated from Centennial College's Software Engineering Technician program, and in Korea, I am an IT professional with 9 years of experience, having worked on numerous projects in the financial sector (finance, banking projects, and big data).
In 1999, I spent a year as a P.T.S. network engineering volunteer in Dasmarinas, Philippines, gaining global IT experience and networking knowledge. After returning to Korea in 2000, I worked at K.M.C., where I developed Warehouse Inventory Control and Management systems using the Clarion 4GL language, as well as PIS Operational Test PCS using C/C++.
After completing the Java Specialist course at LG-SOFT SCHOOL in 2001, I spent about two years at CNMTechnologies focusing on e-CRM/e-SFA R&D and development, gaining experience through various projects including the Korea Development Bank, Daejeon Government Complex, and Youngjin Pharm.
From 2004 until I moved to Canada in 2012, I participated in, developed, and led numerous projects, including SKT/SK C&C (IMOS), SC First Bank (TBC), Prudential Life (PFMS), AXA Kyobo Life Insurance Account Management, and Kookmin Bank Financial Management Reconstruction NGM.
Since late 2012, while living in Canada, I have been working as a Scrum Master and a father of three, adopting Agile development methodologies to develop handyman apps, e-commerce apps, product development, and recipe apps.
Living in Canada since late 2012, I am a father of three and a Scrum Master with hands-on experience in the North American region, where I adopted Agile development methodologies to develop handyman apps, e-commerce apps, product development, and recipe apps.
I hope this lecture will be an opportunity to approach Hadoop in a more friendly way. I also hope that the Spark lecture will be delivered to you. I support you from Toronto to become a Hadoop expert.
Yes, thank you. MapR is a high-level data technology. I am glad that it is a good benefit. I hope that you will learn ecosystem technologies such as Apache Accumulo or HASE Spark separately and become an inspired big data platform operator. I am envious that you are facing the integration of Oozie, Flume, Pig, Zookeeper YARN while doing MapR..
I cheer for you to become a big data expert in Toronto.
Yes, thank you for your good review. It is not easy for beginners who are new to Hadoop to follow the books currently available on the market. In that sense, my lecture emphasized running Hadoop, HDFS, and YARN applications on a single node while learning before purchasing the book, as Taekyung Kim said in his review. If it is effective, thank you. I will see you again with a better lecture. I hope you will grow into a Hadoop expert.
Pros:
You can learn the basics of Hadoop MapReduce.
It seems to be the only Hadoop lecture in Korean.
Disappointing points:
I was disappointed that there was no content I was curious about, such as extracting with one common key using two mappers,
when using two keys,
how to set the comparator directly,
and so on.
Cons:
The instructor's Korean pronunciation is not clear, and the background music is loud, so I had to listen to what he was saying several times.
---------------------------------------
I will change the rating to 5 stars after seeing the teacher's answer.
Thank you for your kind and detailed evaluation. The theory of Hadoop is so vast that I can say that I can't cover everything. It's even harder to understand the entire Hadoop by listening to my lecture. I removed the background music and re-recorded it with a clear voice, so I would appreciate it if you could take the lecture again. There are also updated lectures, so I hope you will listen to them in quiet times and become a Hadoop expert.
This course was created with the intention of training you to become a Hadoop expert who handles big data. Rather than using a comprehensive on-premise distribution software application (OPD) like Cloudera, we will move you to the step of installing Hadoop from scratch, extracting, moving, and loading datasets. Hadoop, which started from version 1.x, has now become a very heavy platform with many features added up to version 3.3, but I hope that this course will be filled with the desire to train you to become a big data expert by handling many tools.






















![[Data Preprocessing] Don't worry! Pandas is here.Course Thumbnail](https://cdn.inflearn.com/public/files/courses/336824/cover/01k5849rtc0vfa7df3revd2tpb?w=420)




![[Renewed] MongoDB and NoSQL (Big Data) Database Bootcamp for Beginners [From Introduction to Application] (Updated)Course Thumbnail](https://cdn.inflearn.com/public/courses/324183/cover/fbe9f0cc-4c42-4435-b855-f283f6932415/324183.png?w=420)
![[D-PEC UP_PASS] National Technical Qualification: Management Information Visualization Ability (Written Exam)Course Thumbnail](https://cdn.inflearn.com/public/files/courses/336327/cover/01jytyqa2egrzn52a7m57fntzk?w=420)

![[Marketing Archive] Big Data-Driven Marketing StrategyCourse Thumbnail](https://cdn.inflearn.com/public/files/courses/339225/cover/01k7e89h4d1fkmcr1bwfh1j33h?w=420)






![[Renewal] First-time SQL and Database (MySQL) Bootcamp [From Beginner to Application]Course Thumbnail](https://cdn.inflearn.com/public/courses/324208/cover/85872a8e-d2bb-4c43-82fc-d55fa067746e/324208.png?w=420)


