





![[DevOneYoung] Apache Kafka for beginnersCourse Thumbnail](https://cdn.inflearn.com/public/courses/326507/cover/aa474be0-c000-4b61-afbb-cb78ed0fb843?w=420)
[DevOneYoung] Apache Kafka for beginners
dvwy
What is Apache Kafka? How does Apache Kafka work? What are the concepts of Apache Kafka? If you are curious, choose this course😎
Basic
Kafka, Data Engineering

Learn properly with DevOneYoung!
The A to Z of Apache Kafka 🚀
![]()
Data Engineer Event Driven
Stream Processing Data Pipeline
Basic concepts + various functions for commercial environment application
The essence of Kafka is thoroughly captured in one lecture 😊
Hello, this is DevOneYoung! Apache Kafka, an event streaming platform designed to handle large-scale, high-volume stream data, is beloved by many developers both domestically and internationally. To utilize the powerful open-source features of Apache Kafka, you must have a solid understanding of the surrounding ecosystem, including basic Kafka concepts.
This course provides the knowledge necessary to effectively develop Apache Kafka applications . It covers not only the fundamental concepts of Apache Kafka but also the features officially provided by open-source Apache Kafka, including producers, consumers, streams, and connects.
This course is designed to fully convey the knowledge and expertise I've gained over many years of developing and operating Apache Kafka applications. Beyond simply explaining the technology, this course also explains how each feature and option applies in a commercial environment . We hope this course will serve as a stepping stone for you to become an Apache Kafka application development expert.
When first learning Apache Kafka, the most challenging question is "How much should I learn?" It's a platform with a long history, and it covers so many technologies. The Kafka consumer, which you'll commonly use, has over 90 options. Do you really need to know them all to develop?
To answer this question, I created this course. This course doesn't list all of Kafka's features and technologies. Instead, it focuses on the options and features you'll immediately need when developing production Kafka applications. I'll also share the configuration values I set while developing and operating the application.
By taking this course, you will be able to develop and operate Apache Kafka applications more efficiently and with less trial and error.

Apache Kafka
(Apache Kafka)
I want to know the basic concepts
new developer
Become a data engineer
data pipeline
I want to build
backend developer
Processing stream data
Kafka-based architecture
I want to study
data engineer
This course covers the various knowledge required to develop applications that integrate with Kafka . By learning the precise vocabulary, expressions, and tools used in open-source Apache Kafka, this course will prepare new developers who need to work with Kafka immediately.
It also provides detailed explanations of frequently used options and features when developing applications, making it useful for backend developers who need to integrate Kafka. Finally, it provides insights for data engineers who have already adopted and operated Kafka, through explanations of the surrounding ecosystem (Connect, Streams) and architecture.
Apache Kafka covers a wide range of terms. Terms like rebalancing, message keys, partitioners, accumulators, and tasks can be unfamiliar to developers unfamiliar with Kafka. Without a clear understanding of the concepts behind each term, understanding and developing Kafka can be quite challenging. This lecture will explain the precise concepts behind key terms used in Kafka.
Apache Kafka, a distributed event streaming platform, not only supports general messaging queuing functionality but also enables real-time stream processing of events. As a data platform, it's ideal for repeatedly creating and operating data pipelines. However, to utilize and leverage these capabilities, a solid understanding of the surrounding ecosystem is essential. This lecture covers producers, consumers, Kafka Streams, and Kafka Connect, providing application developers with insight into stream data processing.
When developing Kafka applications, you don't need to learn and master every feature from the beginning. While the consumer already provides over 90 options, you don't necessarily use them all. This lecture will cover the options you should configure and apply immediately when developing your application, as well as the option values I used during development. These guidelines will help you reduce trial and error and deploy Kafka applications to production environments more quickly.
Kafka's features and options alone are limited in handling streaming data. Depending on the technology and method used, Kafka's usability varies significantly. This lecture will not only provide a technical explanation, but also provide guidelines on how to apply Kafka-based architectures in practice through the types and history of Kafka-based architectures and case studies.
I have experience operating over 100 Kafka-based data pipelines and developing various stream processing applications. I've pondered how to effectively handle large-scale stream data and strived to develop applications that are safer, faster, and more efficient. I've incorporated what I've learned from simultaneous development and operations into my lectures. This practical expertise is invaluable knowledge not easily acquired through technical documentation.
As you study Kafka, you'll likely encounter a number of questions. You might want to ask your colleagues or developers, but without practical application experience, it's difficult to find answers. Drawing on years of experience developing producer, consumer, Streams, and Connect applications, I aim to provide answers to students. Beyond simply providing lectures, I'll engage with you through Q&A sessions and the community to address the challenges and questions you face in developing Kafka applications.
CCDAK (Conflunet Certified Developer for Apache Kafka) is a Confluent certification that validates Kafka application development expertise. Based on CCDAK preparation and experience, the course provides quizzes that address questions likely to appear on the certification exam. Students can study each section and take the quizzes. They can also review the answers and explanations in video format. The knowledge gained through this process will be beneficial in preparing for future interview questions.
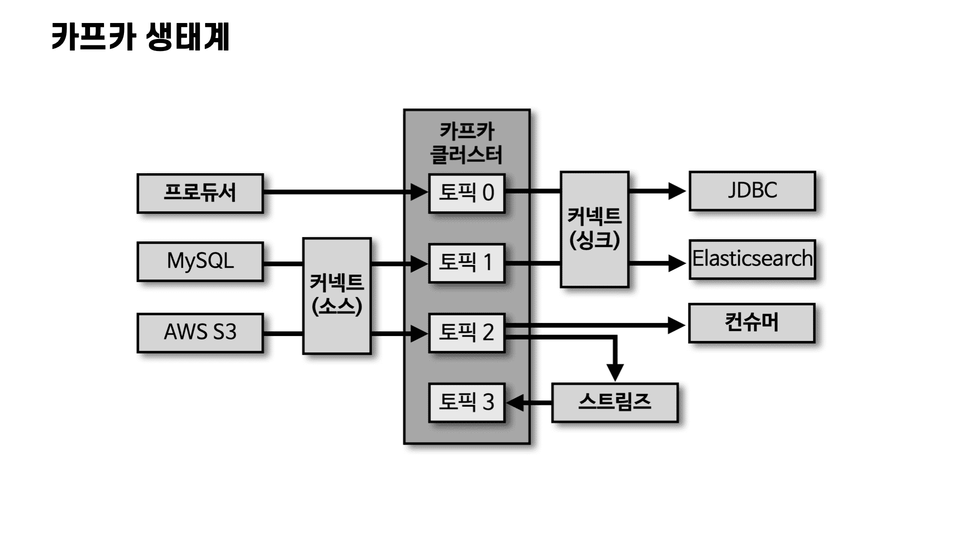
1. Explanation of basic Kafka concepts
Clearly explains the concepts and terms used in Kafka.

2. Operating a Kafka Cluster
Learn about the types and methods of operating a Kafka cluster.

3. Apache Kafka CLI Operation
Learn and practice the most commonly used scripts for developing Kafka applications.
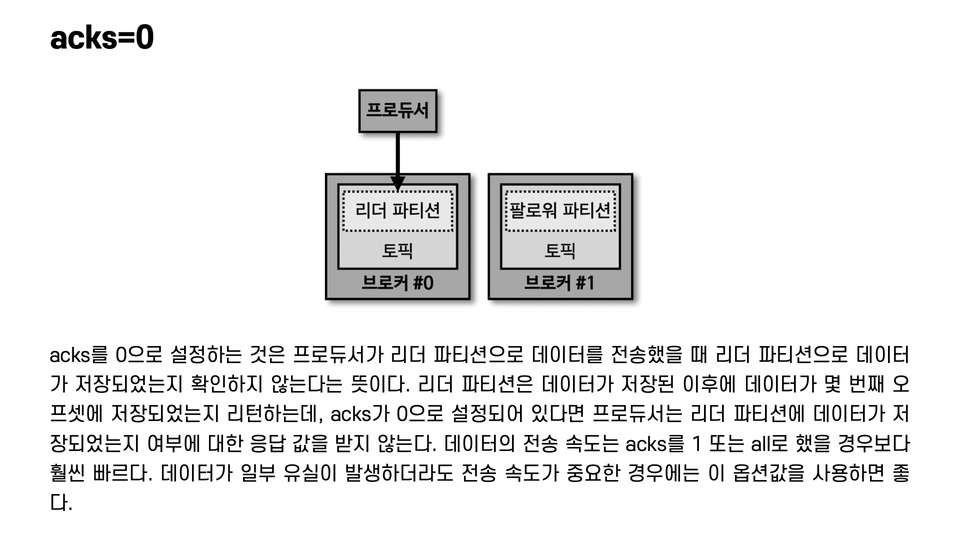
4. Developing a Kafka Producer Application
We'll examine the internal structure, key options, and code of the producer. We'll also examine its behavior with respect to partitioners and the reliability of data transmission for each option.
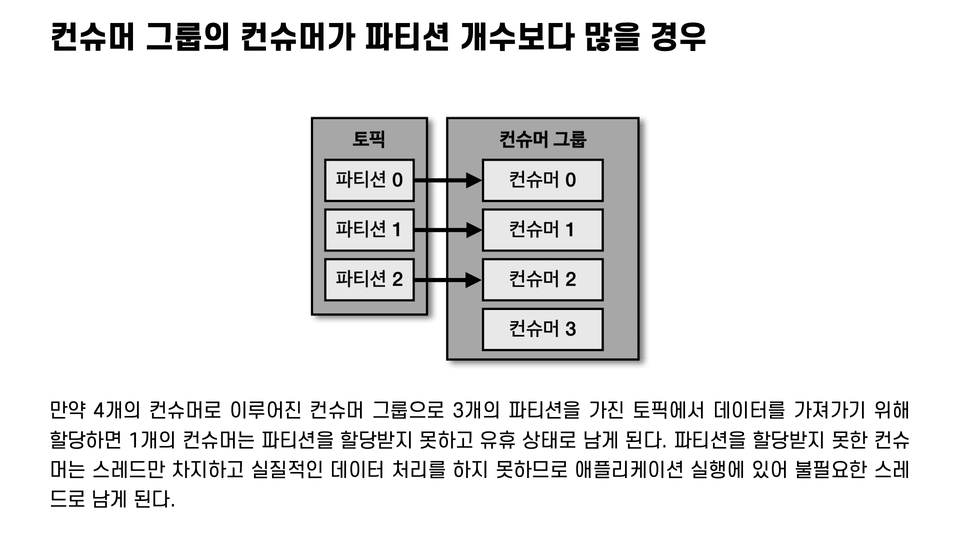
5. Developing a Kafka Consumer Application
We'll examine the internal structure, key options, and code of the consumer. Starting with the consumer group, we'll also cover in detail the consumer rack, the most essential component for consumer operation.
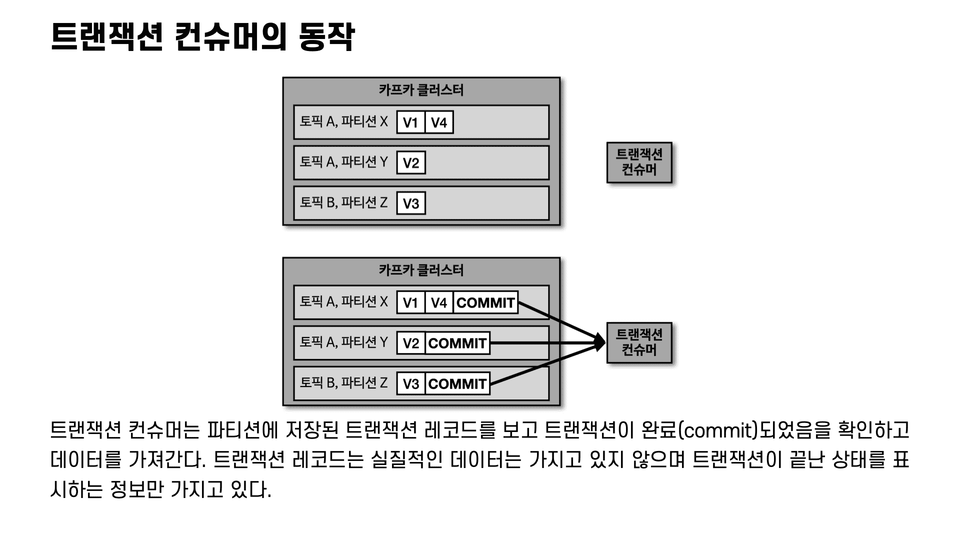
6. Idempotent producers, transactional producers, and consumers
Learn how to use idempotent, transactional producers/consumers, rather than the default producer/consumer, and learn how to use them.
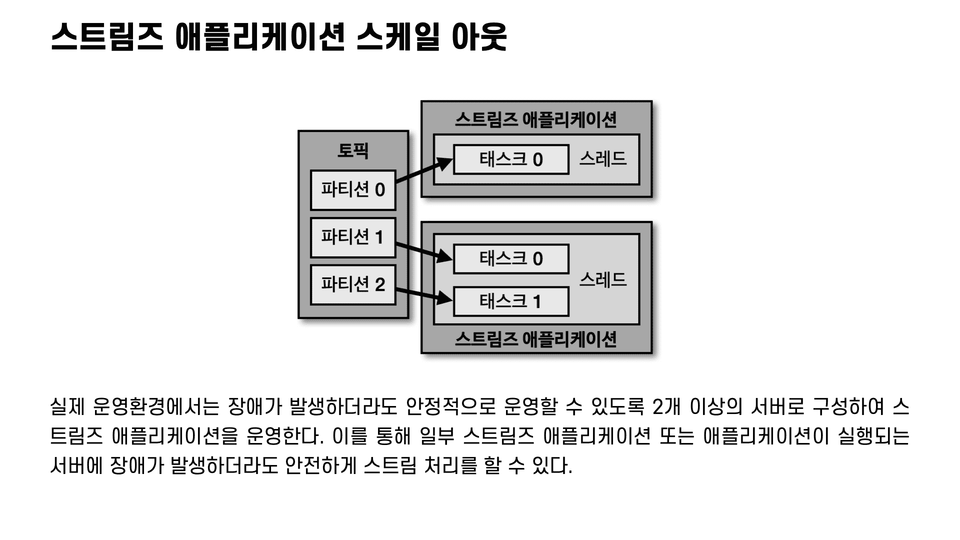
7. Kafka Streams
We'll explore the concepts, key options, and code for Streams applications, which provide powerful stream processing capabilities.
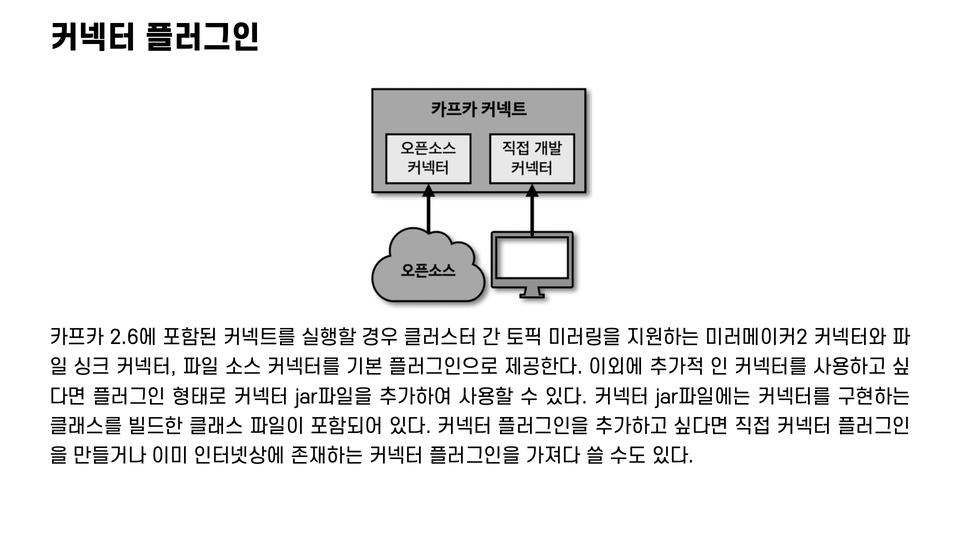
8. Kafka Connect
We'll explore the concepts of connect, along with code, used to develop and operate iterative data pipelines.


Q. Do I have to purchase the book [Apache Kafka Application Programming with Java] to take this course?
The techniques and code covered here are based on "Apache Kafka Application Programming with Java." However, since all the material covered in this course is provided in PDF format, you don't necessarily need to purchase the book. If you'd like to learn and review additional content (MirrorMaker2, AWS MSK, etc.), purchasing this book is a great option.
Q. Can non-majors also take the course?
This course faithfully explains the fundamental concepts of Apache Kafka and delves into the features and options required for real-world development environments. Furthermore, the course is structured so that even those unfamiliar with other software or big data platforms can easily learn the concepts, making it ideal for non-majors seeking a career as a data engineer.
Q. Why learn using Java? Can I still learn without knowing Java?
The official libraries provided and supported by the open-source Apache Kafka are Java. Furthermore, developing Kafka Connect and Kafka Streams requires the official Java libraries as dependencies. Therefore, to truly appreciate the value of open-source Apache Kafka, you must develop Java-based applications (producers, consumers, Streams, and Connect). Third-party libraries (in other languages) don't provide the same functionality and cannot guarantee perfect compatibility, so this course is written in Java.
Don't worry if you're not familiar with Java. The code is explained line by line, so you'll be able to follow along without difficulty.
Q. Do I need a MacBook to do the training?
No, you can practice on operating systems other than MacBooks. While the lecture and practical environment are based on a MacBook, the scripts are designed to run on Windows or Linux, as long as the JVM is running. Therefore, don't worry even if you don't have a MacBook.
Students on Windows may need to set up a WSL development environment to run shell scripts. For detailed instructions, please refer to Setting Up a WSL Development Environment (link) .
Q. What PC specifications are required for the training?
To run ZooKeeper and the Kafka broker locally and conduct the exercises, you need a laptop or desktop with at least 8GB of memory. An i3 (3GHz) or higher CPU is recommended. Finally, you need at least 1GB of free space on an SSD or hard drive for storage.
I am a job seeker preparing for the data engineer field. I wanted to study Kafka, but I was at a loss because there were no famous lectures or suitable materials. It is really great that there are high-quality lectures in Korean! Thank you for the great lecture!
great!
It wasn't easy to learn the basics of Kafka, but I think it's good.
I needed to learn Kafka in a hurry, so I almost finished the course in 3 days. I liked that it was easy to understand and there was no unnecessary content. Personally, I really liked the part where the case studies of the utilization architecture and the curriculum review were organized again. I listened to a good lecture.
This time, I had to work on something related to Kafka, and fortunately, I found out about this lecture, which helped me a lot. Thank you!





![[Renewed] MongoDB and NoSQL (Big Data) Database Bootcamp for Beginners [From Introduction to Application] (Updated)Course Thumbnail](https://cdn.inflearn.com/public/courses/324183/cover/fbe9f0cc-4c42-4435-b855-f283f6932415/324183.png?w=420)


![Learning Docker and CI Environments by Following Along [Updated 2023.11]Course Thumbnail](https://cdn.inflearn.com/public/course-325821-cover/e5a56b04-463b-410c-9b3a-d769cd192add?w=420)






![[Data Preprocessing] Don't worry! Pandas is here.Course Thumbnail](https://cdn.inflearn.com/public/files/courses/336824/cover/01k5849rtc0vfa7df3revd2tpb?w=420)




