



















빅데이터 파이프라인 마스터; 성공을 위한 도구와 기술
J.PHIL
₩99,000
초급 / 빅데이터, Elasticsearch, Apache Spark, Kibana, Hadoop, Logstash, s3-bucket
5.0
(21)
300+
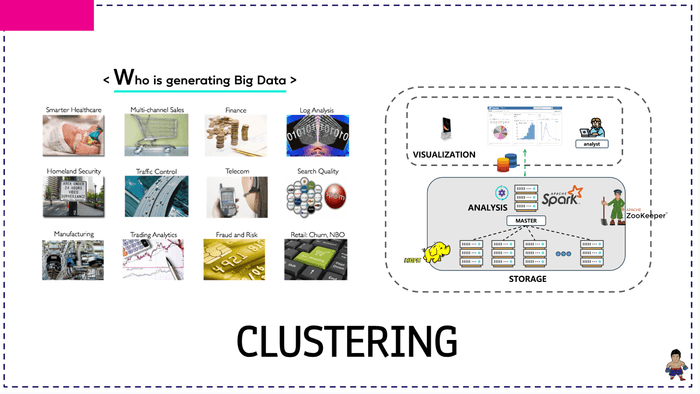
여러분들은 빅데이터 프로세싱의 4단계에 해당하는 [데이터 수집 ▶ 데이터 저장 ▶ 데이터 분석 ▶ 표현] 에 대한 내용을 이론 30% + 실습 70%으로 이루어진 코드랩 방식으로 보다 재밌고 체계적으로 학습합니다 🧑🏻🏫
초급
빅데이터, Elasticsearch, Apache Spark



![[관리코스 #3] DE, DBA (SSIS, SSAS, MachineLearning, BI, ETL)강의 썸네일](https://cdn.inflearn.com/public/courses/329784/cover/c5e6543b-72c3-4471-b43f-15b9002e65ed/329784-eng.png?w=420)


![[데이터 전처리] 걱정하지마! Pandas가 있으니까.강의 썸네일](https://cdn.inflearn.com/public/files/courses/336824/cover/01k5849rtc0vfa7df3revd2tpb?w=420)

![[리뉴얼] 처음하는 MongoDB(몽고DB) 와 NoSQL(빅데이터) 데이터베이스 부트캠프 [입문부터 활용까지] (업데이트)강의 썸네일](https://cdn.inflearn.com/public/courses/324183/cover/fbe9f0cc-4c42-4435-b855-f283f6932415/324183.png?w=420)



![[2026] SQLD 문제가 어려운 당신을 위한 노랭이 176 문제 풀이강의 썸네일](https://cdn.inflearn.com/public/files/courses/336270/cover/01kfq647gtwqrwbjwbrn9rhn1t?w=420)






![따라하며 배우는 도커와 CI환경 [2023.11 업데이트]강의 썸네일](https://cdn.inflearn.com/public/course-325821-cover/e5a56b04-463b-410c-9b3a-d769cd192add?w=420)