




'KNeighborsClassifier'만 nan으로 나오는 이유를 모르겠습니다...
553
작성한 질문수 2
knn_model = KNeighborsClassifier()
logreg_model = LogisticRegression()
svc_model = SVC()
decision_model = DecisionTreeClassifier()
random_model = RandomForestClassifier()
extra_model = ExtraTreesClassifier()
gbm_model = GradientBoostingClassifier()
nb_model = GaussianNB()
xgb_model = XGBClassifier(eval_metric='logloss')
lgbm_model = LGBMClassifier()
models = [
knn_model,
logreg_model,
svc_model,
decision_model,
random_model,
extra_model,
gbm_model,
nb_model,
xgb_model,
lgbm_model
]
k_fold = KFold(n_splits=10, shuffle=True, random_state=0) # K-Fold 사용
results = dict()
for alg in models:
alg.fit(X_train, y_train)
score = cross_val_score(alg, X_train, y_train.values.ravel(), cv=k_fold, scoring='accuracy')
results[alg.__class__.__name__] = np.mean(score)*100
위 코드를 실행한 후 results를 출력해보면 아래처럼 KNeighborsClassifier 모델만 nan값이 나오는데 그 이유를 모르겠습니다..
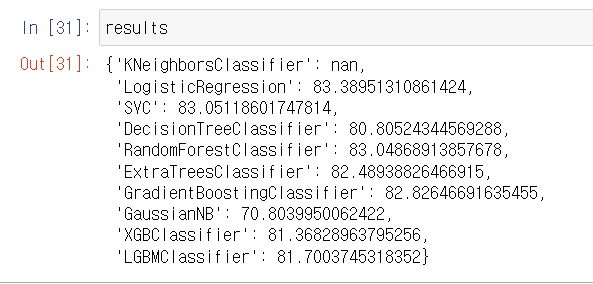
혹시 몰라 아래 코드처럼
neighbor 수를 지정해서 돌려봐도 nan 결과가 뜨는데 이유가 있을까요...??
다른 모델들도 다 안되면 데이터 문제인가 싶을텐데, knn 모델만 그래서 원인이 감이 잡히지 않습니다ㅜ
knn_model = KNeighborsClassifier(n_neighbors = 3)답변 2
1
안녕하세요. 답변 도우미입니다.
코드가 여러 라인이고, 데이터까지 연결되어 있어서, 딱 어떤 부분이 문제이다 라고 정확히 이야기드리기는 어렵긴 한데요. 다음 정도의 내용을 참고해보시면 좋을 것 같습니다.
cross_val_score에서 nan 값이 반환되는 것은 보통 데이터셋에 문제가 있거나, 모델이 특정 설정으로 학습할 수 없는 상황에서 발생합니다. KNeighborsClassifier와 관련하여 다음과 같은 이유들이 있을 수 있습니다:
1. 데이터 이슈:
- 결측치가 포함되어 있을 경우 KNN은 결측치가 있는 데이터와 거리를 계산할 수 없기 때문에 문제가 발생할 수 있습니다.
- X_train 또는 y_train에 NaN값이 있는지 확인해 보세요.
2. 데이터 스케일링:
- KNN은 거리 기반 알고리즘이므로 특성 간의 스케일 차이에 매우 민감합니다. 모든 특성이 동일한 스케일을 가지고 있지 않으면 문제가 발생할 수 있습니다. 일반적으로 KNN을 사용하기 전에 데이터를 스케일링하는 것이 좋습니다. 예를 들어, StandardScaler 또는 MinMaxScaler를 사용하여 특성을 스케일링해 볼 수 있습니다.
3. 메모리 부족:
- 매우 큰 데이터셋의 경우 KNN은 메모리 부족으로 실패할 수 있습니다. 이는 KNN이 모든 데이터 포인트 간의 거리를 계산해야 하기 때문입니다.
4. 다른 설정 문제:
- KNeighborsClassifier의 기본 설정 외에 다른 설정이 필요한 경우가 있을 수 있습니다. 예를 들면, n_neighbors의 값을 변경해 볼 수 있습니다.
문제 해결을 위해 다음과 같은 점검 사항을 거쳐 보세요:
1. 데이터 확인:
print(X_train.isnull().sum())
print(y_train.isnull().sum())위 코드로 NaN값이 있는지 확인합니다.
2. 데이터 스케일링:
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train)
스케일링을 진행한 후 다시 KNN 모델에 학습 및 교차 검증을 시도합니다.
3. 만약 위의 점검 사항으로도 문제가 해결되지 않는다면, KNN 학습 및 교차 검증 과정에서 발생하는 에러 메시지를 확인하여 문제의 원인을 파악하는 것이 좋습니다.
감사합니다.
0
친절한 답변 감사합니다!
데이터에 Nan값은 없었는데 데이터스케일링을 하니 문제가 해결되었습니다!
덕분에 데이터스케일링에 대해 또 하나 배워갑니다ㅠ 감사합니다!
자료 공유 질문
0
84
2
Ascii 에러 관련하여 질문드립니다
0
111
1
고차원 데이터 질문
0
97
1
test / train 데이터 나누기
0
130
1
세션4 범주형 데이터 분석 패턴 강의 질문
0
229
2
pandas 2.2.2, xgboost 2.1.3 에러 해결 방법
0
259
1
sklearn v1.5.1
0
179
1
머신러닝 적용을 위한 Feature Engineering 작업1
0
196
2
missingno 대체
0
185
1
scikit-learn 1.5.1 matplotlib 3.9.2
0
138
1
환불문의
0
284
1
자료공유를 받으려고 하는데 에러가 납니다.
0
183
1
iplot에서 항상 에러나는 분 안계신가용?
0
245
1
사망 여부 영향 가능성
0
158
1
섹션4_인코딩 이해하고 적용해보기(원핫인코딩) 질문
0
205
1
df.corr(numeric_only=True).iplot() 에러 해결 어떻게 해야되나요?
0
292
1
주피터 노트북 201_REGRESSION_BIKE_SHARING_MODELS 중 질문
0
261
1
3강 강의 자료 코드 관련 질문입니다
1
354
1
맥 사용자 mkdir .kaggle 했는데 파일이 안만들어집니다.
0
443
1
Bayesian Optimization에서 optimizer.maximize()함수를 더이상 지원 안한다고 합니다.
0
903
2
Bayesian Optimization LightGBM 적용
0
477
2
하이퍼 파라미터 튜닝 기법 적용하기 실행값이 미묘하게 달라요.
1
357
1
중복된 코드 수정 요청 - 자전거 공유 문제 이해와 EDA3
0
224
1
강의 중 에러 질문
0
770
1