




raccoon 이미지 디텍션 트레이닝 결과가 너무 안좋은데 GPU성능 차가 있나요??
330
작성한 질문수 2
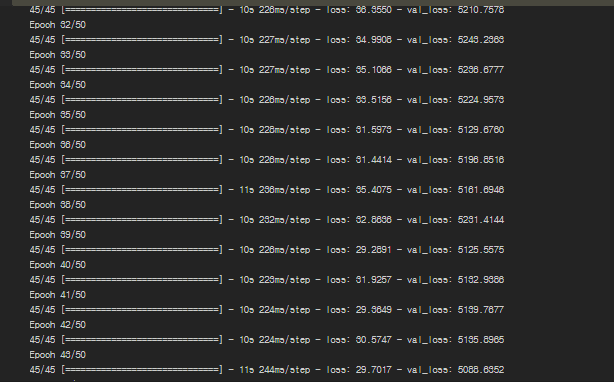
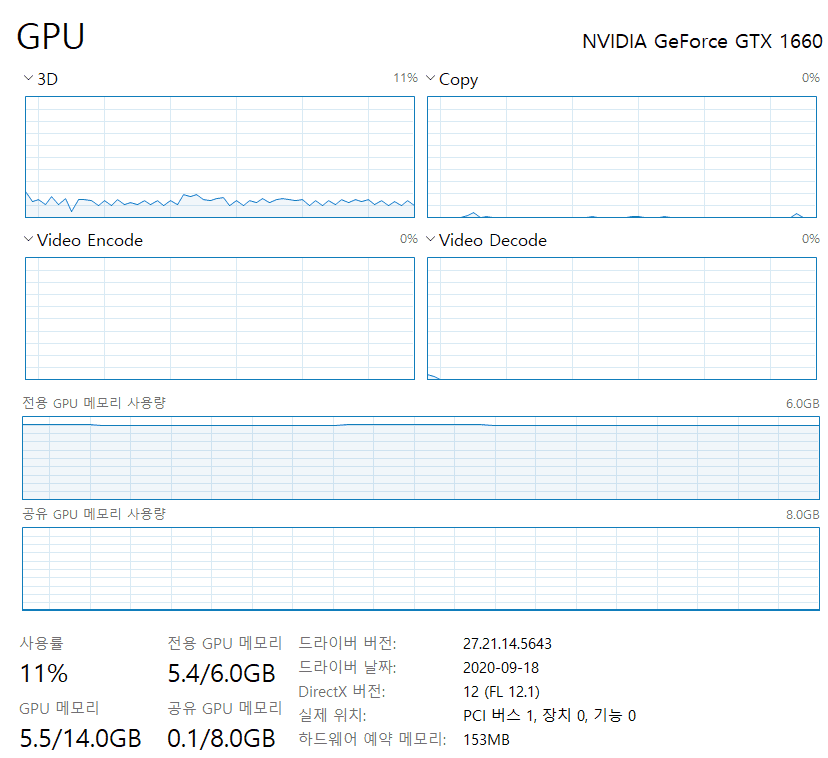
Val_loss값이 강의와 다르게 너무 크게나오고 줄지를 않습니다. (4000~6000)



실행 - 결과파일 모두 정상적으로 나왔는데 디텍션 결과가 너무 좋지않네요
디텍션 정확도가 0.3~5 정도로 1/3 정도만 디텍션 됩니다 ..
env : [conda] conda 4.8.5 [cudatoolkit] 10.0.130 [cudnn] 7.6.0 [python] Python 3.7.6 [tensorflow-gpu] 1.13.1
[keras] 2.2.4
C:\Users\admin\anaconda3\lib\site-packages\keras\engine\saving.py:1140: UserWarning: Skipping loading of weights for layer conv2d_1 due to mismatch in shape ((3, 3, 3, 32) vs (64, 32, 3, 3)).
weight_values[i].shape))
C:\Users\admin\anaconda3\lib\site-packages\keras\engine\saving.py:1140: UserWarning: Skipping loading of weights for layer batch_normalization_1 due to mismatch in shape ((32,) vs (64,)).
weight_values[i].shape))
C:\Users\admin\anaconda3\lib\site-packages\keras\engine\saving.py:1140: UserWarning: Skipping loading of weights for layer conv2d_2 due to mismatch in shape ((3, 3, 32, 64) vs (32, 64, 1, 1)).
weight_values[i].shape))
C:\Users\admin\anaconda3\lib\site-packages\keras\engine\saving.py:1140: UserWarning: Skipping loading of weights for layer batch_normalization_2 due to mismatch in shape ((64,) vs (32,)).
weight_values[i].shape))
C:\Users\admin\anaconda3\lib\site-packages\keras\engine\saving.py:1140: UserWarning: Skipping loading of weights for layer conv2d_3 due to mismatch in shape ((1, 1, 64, 32) vs (64, 32, 3, 3)).
weight_values[i].shape))
C:\Users\admin\anaconda3\lib\site-packages\keras\engine\saving.py:1140: UserWarning: Skipping loading of weights for layer batch_normalization_3 due to mismatch in shape ((32,) vs (64,)).
weight_values[i].shape))
C:\Users\admin\anaconda3\lib\site-packages\keras\engine\saving.py:1140: UserWarning: Skipping loading of weights for layer conv2d_4 due to mismatch in shape ((3, 3, 32, 64) vs (128, 64, 3, 3)).
weight_values[i].shape))
Load weights \Users\admin\Desktop\DLCV\Detection\yolo\keras-yolo3\model_data\yolo.h5.
Freeze the first 249 layers of total 252 layers.
Train on 180 samples, val on 20 samples, with batch size 4.
Epoch 1/50
45/45 [==============================] - 14s 303ms/step - loss: 3209.1600 - val_loss: 6300.4242
Epoch 2/50
45/45 [==============================] - 9s 202ms/step - loss: 707.9817 - val_loss: 5987.8038
Epoch 3/50
45/45 [==============================] - 10s 222ms/step - loss: 404.0721 - val_loss: 5872.5174
Epoch 4/50
45/45 [==============================] - 8s 187ms/step - loss: 300.0009 - val_loss: 5676.1661
Epoch 5/50
45/45 [==============================] - 10s 223ms/step - loss: 197.5603 - val_loss: 5666.7763
Epoch 6/50
45/45 [==============================] - 10s 222ms/step - loss: 172.6001 - val_loss: 5630.2007
Epoch 7/50
45/45 [==============================] - 10s 219ms/step - loss: 134.5537 - val_loss: 5487.8045
Epoch 8/50
45/45 [==============================] - 10s 221ms/step - loss: 116.2651 - val_loss: 5530.3334
Epoch 9/50
45/45 [==============================] - 10s 223ms/step - loss: 99.5342 - val_loss: 5492.4720
Epoch 10/50
45/45 [==============================] - 10s 220ms/step - loss: 87.7493 - val_loss: 5519.4808
Epoch 11/50
45/45 [==============================] - 10s 221ms/step - loss: 76.5280 - val_loss: 5482.3372
Epoch 12/50
45/45 [==============================] - 10s 221ms/step - loss: 71.2550 - val_loss: 5427.8594
Epoch 13/50
45/45 [==============================] - 10s 219ms/step - loss: 62.9793 - val_loss: 5439.6515
Epoch 14/50
45/45 [==============================] - 10s 221ms/step - loss: 59.4915 - val_loss: 5349.3237
Epoch 15/50
45/45 [==============================] - 10s 222ms/step - loss: 63.2302 - val_loss: 5422.8351
Epoch 16/50
45/45 [==============================] - 10s 218ms/step - loss: 58.4533 - val_loss: 5349.4282
.
.
.
.
Epoch 00080: ReduceLROnPlateau reducing learning rate to 1.0000000116860975e-08.
Epoch 81/100
45/45 [==============================] - 24s 540ms/step - loss: 18.5613 - val_loss: 18.1559
Epoch 82/100
45/45 [==============================] - 24s 540ms/step - loss: 18.7043 - val_loss: 18.2448
Epoch 83/100
45/45 [==============================] - 24s 540ms/step - loss: 19.6548 - val_loss: 18.2508
Epoch 00083: ReduceLROnPlateau reducing learning rate to 9.999999939225292e-10.
Epoch 84/100
45/45 [==============================] - 24s 541ms/step - loss: 18.9384 - val_loss: 18.8026
Epoch 85/100
45/45 [==============================] - 25s 547ms/step - loss: 18.6985 - val_loss: 17.7818
Epoch 86/100
45/45 [==============================] - 25s 566ms/step - loss: 18.9661 - val_loss: 19.2374
Epoch 00086: ReduceLROnPlateau reducing learning rate to 9.999999717180686e-11.
Epoch 87/100
45/45 [==============================] - 25s 547ms/step - loss: 18.8628 - val_loss: 18.9642
Epoch 00087: early stopping
답변 2
0
답변 감사드립니다.
디렉토리만 변경해서 실습하고 있습니다.
C:\Users\admin\anaconda3\lib\site-packages\keras\engine\saving.py:1140: UserWarning: Skipping loading of weights for layer conv2d_1 due to mismatch in shape ((3, 3, 3, 32) vs (64, 32, 3, 3)).weight_values[i].shape))
이 error는 해결했는데 val_loss값이 엄청 크게나오는 것은 알수가없네요 ㅠ 일단 강의먼저 다들어보고 차차해결하겠습니다~
0
안녕하십니까,
validation loss가 정말 크게 나오는 군요. GPU 하드웨어에 따라서 예측 성능이 저하되는 경우는 일어나지 않을 것이지만, cuda나 cudnn 버전이 안맞아서 문제가 있을 수는 있습니다. 하지만 현재 [cudatoolkit] 10.0.130 [cudnn] 7.6.0 사용하고 계시는 것 같으며 cudnn 7.6에서 큰 문제는 없어 보입니다.
윈도우 환경에 맞게 디렉토리 관련해서 소스 코드만 변경하신 건가요? 소스 코드를 알수 없으니 제가 도와드리는 게 한계가 있을 것 같습니다.
윈도우 환경 때문에 실습이 영향을 받으신다면 제 github에서 colab용 소스코드를 다운로드 받으신 후 코랩에서 실습 코드를 수행해 보시는 것은 어떠신지요?
아래에서 다운 받으실 수 있습니다.
https://github.com/chulminkw/DLCV/blob/master/DLCV_Colab_SrcCode_20200905.zip
MMDetection 버전 이슈
0
85
2
강의 환경설정 질문
0
84
2
Custom Dataset에서의 polygon 정보 관련
0
129
3
cvat.ai 보안 수준이 궁금합니다
0
119
2
캐클 nucleus 챌린지 runpod 실습 코드 에러 질문드립니다.
0
136
3
추론 결과의 Precision(또는 mAP) 평가 방법
0
116
2
mmdetection mask rcnn inferenct 실습 시 runpod 템플릿 관해서 질문드립니다.
0
83
2
runpod에서 google drive 연결 시 오류 발생
0
140
2
로드맵 선택
0
88
1
mmcv
0
80
2
Anchor box의 Positive 처리 위치
0
84
2
해당 강의 runpod 적용 후 에러 제보드립니다
0
123
2
run pod credit 관련 제보
0
155
2
mmdetection 2.x과 3.x 호환 관련 표기
0
105
2
mm_faster_rcnn_train_kitti.ipynb 실행 오류
0
134
3
질문 드립니다.
0
108
3
mm_faster_rcnn_train_coco_bccd 실행 오류 질문드립니다.
0
108
1
강사님께 수정을 제안드리고 싶은 것이 있습니다.
0
115
1
google automl efficientdet 다운로드 및 설치 오류
0
100
1
이상 탐지에 사용할 비전 기술 조언 부탁드립니다.
0
132
2
OpenCV 관련 질문드립니다.
0
97
2
mmcv 설치관련해서 문의드려요
0
394
3
강의 구성 관련해서 질문이 있습니다
1
154
2
모델 변환 성능 질문드립니다.
0
134
1