




train_test_split 함수에 대해 질문이 있습니다.
425
작성한 질문수 6
수업을 듣고 mmedetection을 이용해 custom dataset을 train 시키려는 작업을 계획 중인데, 걸리는 부분이 있어 질문 드립니다.
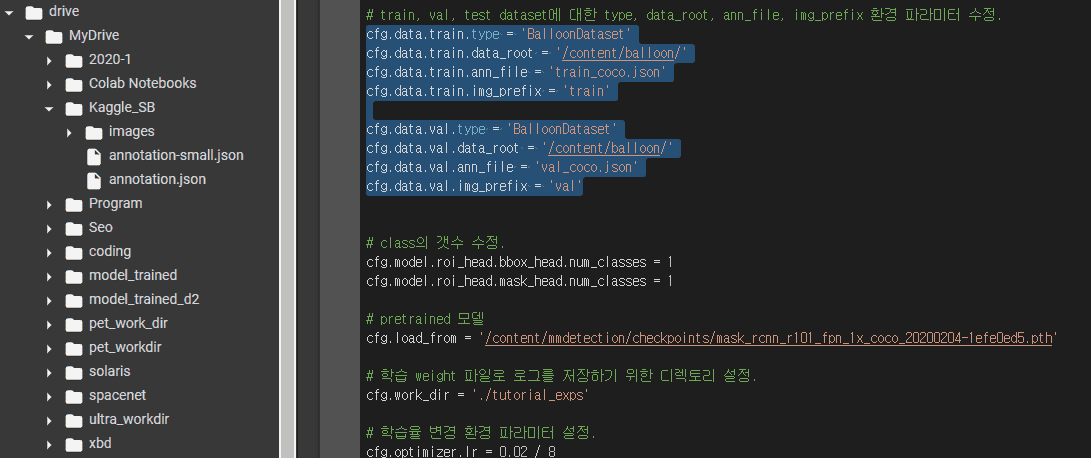
mmdetection에서 mask-rcnn을 수행하기 위해 kaggle에서 coco format에 맞는 dataset을 받고, json 파일의 형식이 coco format에 맞는지 확인 했습니다.
그런데 이 dataset의 이미지와 json가 train밖에 없어서 train, val로 나누기 위해 train_test_split 을 써야 하는데, 이 함수의 첫 번째 변수로 어떤 것을 넣어야 하는지(mask rcnn nucell실습에서는 meta_df) 잘 이해가 되지 않습니다.
찾아보니 array 형태로 넣어야한다고는 하는데, 단순히 train 이미지가 있는 경로를 np.array로 넣는 것은 아닌 거 같고, 제 파이썬 실력은 많이 부족해 답이 나오지 않아 질문 남깁니다.
Dataset의 형태는 사진으로 첨부합니다. json은 약 28만 장에 대한 내용이 coco format으로 나와있습니다.

답변 1
0
안녕하십니까,
nucleus는 coco 포맷으로 개별 mask정보가 되어 있지 않아서 coco 포맷으로 변환을 한 것이라 이미 coco 포맷으로 annotation이 되어 있다면 굳이 이를 따를 필요는 없을 것 같습니다.
하나의 큰 coco 포맷 파일이 있는데, 이를 train용, valid용으로 나누지 못하신다는 의미 이신지요?
현재 그런 작업이 어렵다면 일단 valid와 train을 모두 동일한 coco 포맷으로 작업하시면 어떨지요?
0
Train과 vaild를 동일한 coco 포맷으로 작업한다는 게 정확히 이해가 가지 않습니다!
현재 막히는 부분은 images 안에 있는 이미지들을 config에 맞게 train 폴더와 val 폴더에 나눠서 넣고, 하나로 있는 annotation.json 파일도 나뉜 이미지 목록에 맞게 나누는 작업입니다.
혹시 나누지 않고 작업을 하란 말씀이 저 config 설정에 train과 val 모두 동일한 images 경로, annotation.json 경로로 지정하라는 말씀이신가요?
MMDetection 버전 이슈
0
53
2
강의 환경설정 질문
0
63
2
Custom Dataset에서의 polygon 정보 관련
0
114
3
cvat.ai 보안 수준이 궁금합니다
0
99
2
캐클 nucleus 챌린지 runpod 실습 코드 에러 질문드립니다.
0
120
3
추론 결과의 Precision(또는 mAP) 평가 방법
0
96
2
mmdetection mask rcnn inferenct 실습 시 runpod 템플릿 관해서 질문드립니다.
0
69
2
runpod에서 google drive 연결 시 오류 발생
0
128
2
로드맵 선택
0
74
1
mmcv
0
66
2
Anchor box의 Positive 처리 위치
0
71
2
해당 강의 runpod 적용 후 에러 제보드립니다
0
97
2
run pod credit 관련 제보
0
127
2
mmdetection 2.x과 3.x 호환 관련 표기
0
89
2
mm_faster_rcnn_train_kitti.ipynb 실행 오류
0
114
3
질문 드립니다.
0
89
3
mm_faster_rcnn_train_coco_bccd 실행 오류 질문드립니다.
0
89
1
강사님께 수정을 제안드리고 싶은 것이 있습니다.
0
103
1
google automl efficientdet 다운로드 및 설치 오류
0
87
1
이상 탐지에 사용할 비전 기술 조언 부탁드립니다.
0
111
2
OpenCV 관련 질문드립니다.
0
87
2
mmcv 설치관련해서 문의드려요
0
357
3
강의 구성 관련해서 질문이 있습니다
1
141
2
모델 변환 성능 질문드립니다.
0
126
1