




산탄데르 데이터의 precision과 recall
196
작성한 질문수 2
안녕하세요 강사님
산탄데르 데이터와 신용카드 데이터를 실습해보며 질문이 생겼습니다
신용카드 데이터는 precision과 recall이 나쁘지 않게 나오는데 산탄데르 데이터에 대한 precision과 recall은 아래의 결과와 같이 굉장히 안좋습니다
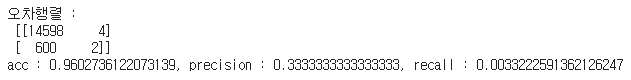
원인이 무엇인가요??
개선할 수 있는 방법이 있나요?
답변 1
0
안녕하십니까,
일단 해당 실습 모델은 최적화된 모델이 아닙니다. 그리고 GridSearchCV도 ROC-AUC를 기준으로 수립된것입니다(이 역시 많은 하이퍼 파라미터 튜닝을 한것이 아닙니다)
고객 불만이 데이터가 전체의 4% 정도로 낮은데, 이 낮은 개수의 고객 불만데이터의 Positive 값 예측이 잘 안되서 그렇습니다.
Precision은 조금 튜닝하면 더 나아집니다. 그런데 Recall이 낮습니다.
precision은 tp/(fp + tp) 인데, confusion matrix를 보시면 tp가 2, fp가 4여서 0.33이 나옵니다.
보시면 fn이 600이나 됩니다. recall은 tp/(fn+tp) 그래서 2/602 가 나오게 됩니다. 여기서 fn을 줄여서 tp로 어떻게든 유도해야 하는데, 이럴려면 좀 더 다양한 성능 기법을 적용해 보아야 합니다.
해당 실습은 성능 튜닝을 목표로 한것 보다는 xgboost, lightgbm의 사용에 익숙해지기 위한 실습 코드입니다.
recall을 높이려면 모델 튜닝을 저도 수행해 봐야 합니다. 해당 건은 Q&A로는 답변 드리기가 어려 울 것 같습니다. 나중에 개정판 계획할 때 Recall 모델 튜닝도 같이 해보도록 하겠습니다.
감사합니다.
모델 서빙과 관련된 강좌가 출시되는지 질문드립니다.
0
52
2
안녕하세요 열심히 수강중인 학생입니다
0
90
2
정수 인덱싱
0
86
2
넘파이 오류
0
109
2
11강 numpy의 axis 축 질문 드립니다.
0
107
2
Kaggle 에서 Santander customer satisfaction data 를 다운로드 되지가 않습니다.
0
94
2
Feature importances 를 보여주는 barplot 이 그래프로 안보여져요.
0
77
2
타이타닉 csv 파일이 주피터 화면에 보이지 않습니다.
0
83
2
타이타닉 csv 파일이 주피터 화면에 보이지 않습니다.
0
73
2
5강 강의 오류가 있어요.
0
90
1
실무에서 LTV 관련 모델 선택 질문입니다!
0
81
2
14강 강의 듣는중에 궁금한게 있어서 질문합니다~
0
76
3
파이썬 다운그레이 후 사이킷런 재설치
0
129
2
좋은 강의 감사합니다.
0
80
2
scoring 함수 음수값
0
72
2
6번 강의에 사이킷런, 파이썬, 아나콘다 각각 버전 일치 안 시키고 진행해도 강의 따라가 지나요?
0
108
2
분류 평가 정확도 예측
0
87
2
안녕하세요. 강의 들으면서 업무에 적용하고 싶은 수강생입니다.
0
114
1
카카오톡 채널 있나요
0
118
1
혹시 강의에서 사용하시는 ppt 받을 수 있는건가요
0
193
2
pca 스케일링 관련하여 질문드립니다.
0
109
2
주피터 대신 구글 코랩
0
184
2
강의에서 사용하는 pdf or ppt자료는 따로 없는 건가요?
0
156
2
실루엣 스코어..
0
91
2