




이 경우에는 어떻게 하는것이 좋을까요..
1281
작성한 질문수 6
안녕하세요 선생님.
강의를 통하여 많이 배우고 제 프로젝트에 적용해 보는 과정에서 문제가 있어서, 여러 방법으로 해결하려고 노력하는 중이지만 차도가 없어 여쭤보고자 질문 글을 남깁니다..
제가 하고자 하는 테스크는 건축가 별로 건물 이미지를 모아서 classification하는 CNN모델입니다. 건축가 수는 40명 정도가 되며 각 건축가마다 최소300 최대 1200개 정도의 이미지를 가지고 있으며 보통 400~600개의 이미지를 각각의 클래스가 가지고 있으며 토탈 이미지의 합은 3만개 정도입니다.
이미지의 크기와 비율이 다 제각각으로 달라서 제가 선택한 pre-processing방법은 albumentations을 이용했는데요. 먼저 타겟 크기를 정하고 (512로 예를 들겠습니다) SmallestMaxSize로 작은 축을 기준으로 512에 맞춥니다. (1000,600) 사이즈의 인풋이 들어온다면 작은축인 600이 512로 바뀌고 비율에 맞춰서 1000도 (512/600)*1000으로 사이즈를 바꿔준다음 CenterCrop으로 512*512사이즈를 맞춰줬습니다. 이 방법을 통하여 전혀 다른 사이즈와 비율의 이미지들을 어느정도 일괄적으로 제가 원하는 타겟에 맞게 설정하였고 데이터셋의 특성상 흑백으로 된 사진들이 종종 있어서 ToGray로 20%만 흑백으로 바뀌도록, HoriozntalFlip은 30%정도로 설정해주었습니다.
트레이닝셋은 위의 augmentation을 진행해주었고, 검증셋은 위에서 horizontal flip만 뺴고 적용해주었습니다. (사실 여기엔... 큰 문제가 있을 것 같진 않아 보이는데.. )
원본 크기는 다양하고 데이터셋의 특성상 1024x1024정도의 사이즈로 해보고 싶었지만 gtx1080을 쓰고 있는 이상 256정도로 타협하고 테스트를 진행했습니다. 다음 강좌에서 쓰였던 CNN코드를 거의 그대로 사용하여서 학습을 진행하였고, resnet, xception, efficientnetb0, b3정도를 써서 학습을 진행해보았는데 공통적으로 val_acc가 특정기준 이상으로 올라가지 않습니다. (공통적인 특징으로는 트레이닝은 계속 되지만 val_acc가 40~50중반 쯤에서 멈추고 val_loss가 좋아지지는 않는데 val_acc는 50정도까지는 올라가는 현상을 보입니다.. 이걸 일반화를 못시키고 있다고 볼 수도 있을것 같고.. val_acc가 올라가는걸 봐선 정답을 맞추긴 하는데 val_loss가 안올라가는걸봐선 정답을 맞추는데 특정이미지들은 계속 틀려서 loss가 안올라가는 것 같네요...)
이 상황에서 해상도가 문제일 수도 있을 것 같아서 512로 변경을 하였는데 시간이 너무 오래 걸려서 데이터셋에서 5천개의 표본을 랜덤셔플로 추출하여 트레이닝을 다시 진행해보았는데, 비슷한 결과가 계속 나오네요.. (아래 첨부 이미지는 부분표분으로 512사이즈의 결과입니다. )
이 경우 선생님께서 보시기에는 어떤 문제점이 있다고 느끼시는지 궁금합니다...
제 생각에는 이미지셋 자체에 문제가 있는 것 같은데, 첫번째로 다양한 스케일의 사진들이 있습니다. 멀리서 찍은 사진과 가까이서 찍은 사진들이 있어서 그런 부분을 잘 인지를 못하고 있는 것이 아닐까..하는 생각이 들고, 두번째는 (제 생각에는 이게 가능성이 높아보이네요..) 외부 건물 사진과 인테리어 사진이 데이터셋에 함께 들어가 있는데 (아무래도 외부 사진이 많습니다. )여기서 내부 사진을 제대로 못 걸러내고 있다거나...라는 생각이 듭니다. 그런데 val_loss의 개선이 크지 않는걸로 봐선 이것도 아닌것 같고.......
(아래 이미지는 3만개 이미지중 5천개만 랜덤추출하여 512사이즈로 진행해본것입니다. efficient3를 사용하였는데, 3만개에 256사이즈로 진행해도 비슷한 트렌드의 결과가 나오네요...)
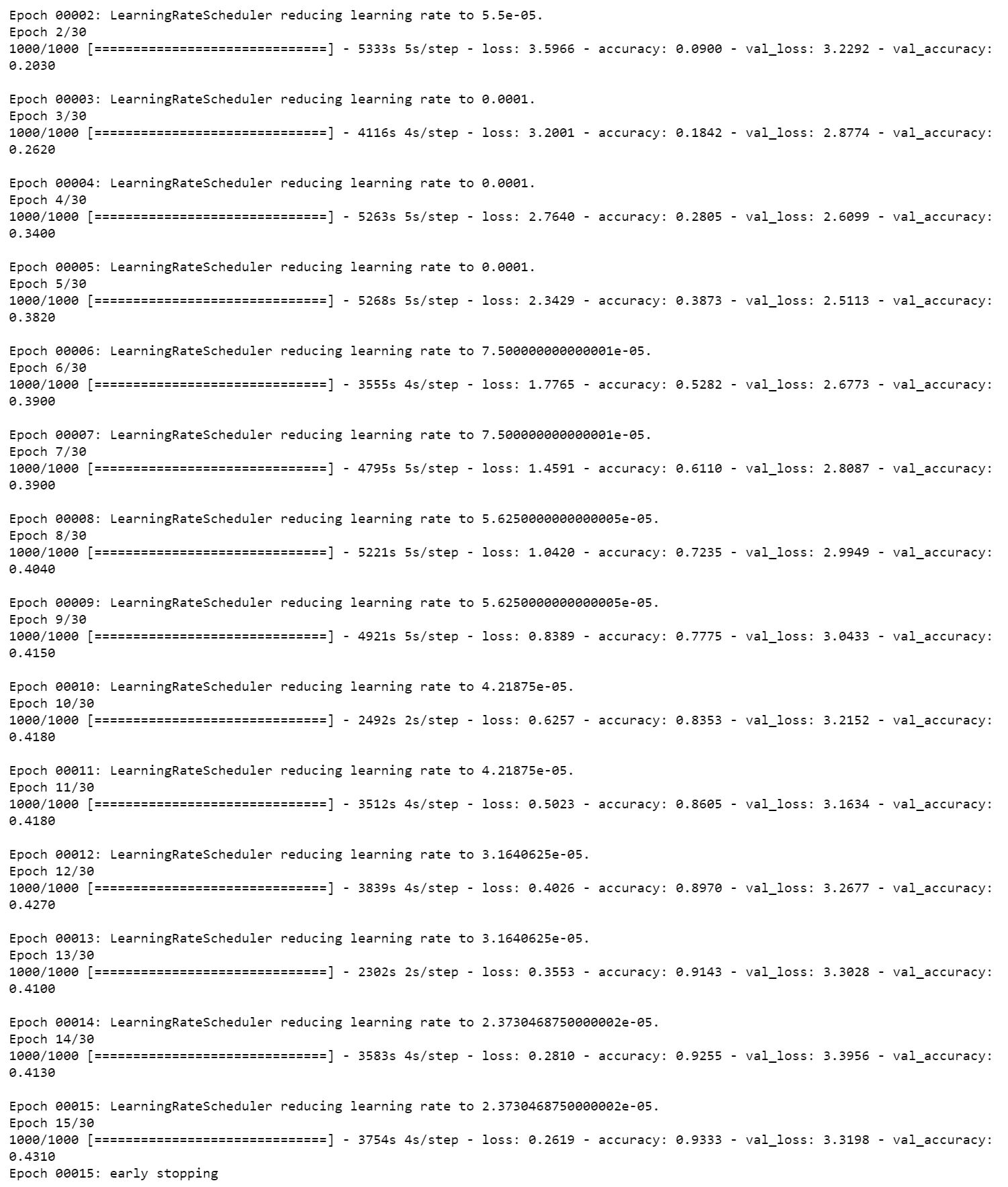
이것은 풀데이터셋으로 256사이즈에서 진행해본것입니다. 위의 트레이닝은 배치사이즈4였는데 이건 16인가 8인가로... 조금 더 큰 배치사이즈를 사용했습니다.

답변 3
0
제 생각은 먼저 약한 augmentation 부터 좀 더 강한 augmentation을 적용하면서 어떤 부분에서 성능향상을 이뤄내는지를 보는게 좋을 것 같아서 제언 드린 방식입니다.
요약 드리자면 resize는 정사각형 형태로 512x512로 구성하고, validation 세트는 resize외에는 augmentation을 적용하지 않는 것입니다.
학습데이터에도 너무 많은 augmentation을 적용하지 마시고, 일단 기본적인 augmentation을 적용했을 때에 검증 데이터 세트에서 성능이 많이 떨어지는 클래스에 해당하는 이미지들에 대한 분석을 먼저 해보는게 좋을 것 같습니다. 말씀드린 대로 crop은 일단 augmentation에서는 제외해보시지요. 저보다 더 건축물 이미지의 전문가시기 때문에 crop으로 조정하는게 더 이미지 보정에 낫다고 생각되시겠지만 일단은 제외하고 나중에 추가적으로 crop을 적용해 보시는게 좋을 것 같습니다.
전반적으로 건축물 이미지가 건축가의 특성을 명확하게 드러내는 이미지 형태는 아닌것으로 보입니다. 말씀하신 대로 전반적인 성능 수치 자체는 높지 않습니다. 그리고 제가 건축을 잘 모르지만, 건축물만 보고 건축가를 맞추기는 전문가들도 많이 헷갈릴것 같습니다. 개와 고양이 같이 특정 형태가 명확히 구분되기는 어려워 보입니다.
하지만 학습과 검증 데이터 간의 성능 갭이 너무 크기 때문에 분명히 성능을 개선할 요소는 있습니다. 그리고 클래스들간 성능 편차도 어느정도 있어 보입니다.
그래서 점진적으로 augmentation을 적용하되, 낮은 성능을 보이는 클래스들의 문제점을 좀 더 집중하는 게 좋을 것 같습니다. 가령 클래스 24가 성능이 잘 안나온다면, 클래스 24가 클래스 3으로 잘못 예측을 한것인지등을 판단해보면 좋습니다. 예를 들어 클래스 24여야 하는데, 3으로 10% 잘못 예측, 21로 20% 잘못 예측과 같이 지표를 뽑아내 본 후에 왜 그렇게 되었는지 이미지를 좀 더 분석해 보는게 좋을 것 같습니다.
가령 24와 3이 너무 비슷한 이미지들이라던가, 아님 crop을 적용하면 더 좋을 것 같다던가,,,,
그런 다음에 거기에 맞는 augmentation을 적용하되 만일 crop 이 문제라면 전체 이미지에 crop을 적용하지 않고 해당하는 이미지들만 crop을 적용해서 새로운 이미지를 만들고 이 새로운 이미지로 학습을 하는 것입니다.
0
그동안 여러가지를 많이 테스트 해보셨군요.
먼저 EfficientNet은 일반적으로 이미지 크기(Resolution)이 클 수록 좋습니다. validation 성능이 64% 정도 나온건 이미지 크기의 영향이 가장 큰것 같습니다. 그리고 이미지 갯수를 늘린것도 어느정도 도움이 된것도 같습니다.
validation 세트의 class 별 정확도를 보면 어느 정도 편차는 있는 걸로 보입니다. 성능이 떨어지는 특정 하위 클래스값들은 이미지의 특징을 함 조사해 보실 필요가 있을 것 같습니다.
다음으로 augmentation을 좀 약한것 부터해서 차례로 적용해볼 필요가 있을 것 같습니다.
1. 먼저 validation 데이터 세트의 augmentation은 적용하지 마십시요.
2. train 데이터 세트는
Horizontal Flip, ShiftScaleRotation, RandomBrightContrast, ColorJitter를 약한 probability 정도로 적용해 주십시요.
이후에 좀 더 강한 probability나 ColorJitter, Blur, CutOut 등을 추가로 적용해 보십시요.
3. 제 생각에는 이미지셋 자체에 문제가 있는 것 같은데, 첫번째로 다양한 스케일의 사진들이 있습니다. 멀리서 찍은 사진과 가까이서 찍은 사진들이 있어서 그런 부분을 잘 인지를 못하고 있는 것이 아닐까..하는 생각이 들고, 두번째는 (제 생각에는 이게 가능성이 높아보이네요..) 외부 건물 사진과 인테리어 사진이 데이터셋에 함께 들어가 있는데 (아무래도 외부 사진이 많습니다. )여기서 내부 사진을 제대로 못 걸러내고 있다거나...라는 생각이 듭니다. 그런데 val_loss의 개선이 크지 않는걸로 봐선 이것도 아닌것 같고.......
라고 말씀하셨는데 해당 이미지 세트 이슈때문에 CenterCrop을 적용하셨다면, (만일 이러한 이미지 갯수가 많다면) 대상 이미지들만 추려내어서 CenterCrop을 적용해 주셔서 별도의 image 파일로 만들고 이를 사용해 주십시요. albumentations로 대상 이미지들을 centercrop 변환 후 cv2.imwrite(이미지 파일명, centercrop된 numpy array) 로 파일을 만들고 이들 파일로 이미지를 대체해 주십시요.
4. 데이터량이 많고 전체 학습 시간이 오래 걸리므로 accuracy 성능이 저조한 class에 해당하는 이미지들만 별도로 뽑아서 이들만 다양한 augmentation을 적용해 보면서 최적 방법을 도출하는 방식도 시도해 보시면 좋을 것 같습니다.
위 사항들 함 시도해 보시면, 결과 update 올려주시면 좋을 것 같습니다.
0
선생님 답변 감사합니다. pretrained모델의 freeze된 weight를 fine tuning으로 추가 학습해보기도 하고, 처음부터 unfreeze를 하고도 학습을 해보았는데 val_acc에 별 변화가 없는걸로 봐서는... weight나 모델을 변경해서 쓰는것 보다 augmentation으로 접근해보는게 저도 맞는 생각인것 같습니다..
간단하게 추가로 질문 드리고 싶은게 있는데, 모든 dataset이 임의의 비율과 해상도를 가지고 있는터라 이를 일률화 시켜주기 위하여 짧은 변을 기준으로 정사각형 모양의 random_crop이나 center_crop을 적용시켜주고 있습니다. 이를 training set과 validation set모두에게 적용시켜주고 있는데 이렇게 해주는게 맞는방법일까요? 제 생각에는 validation set에도 임의의 비율과 해상도의 이미지들이라 이 부분은 augmentation이라기 보다는 데이터 일률화(?)의 단계로 실행은 albumentations에서 되지만 train, val 모두에게 적용되는게 맞다고 생각했기 때문입니다.
그렇다면, 선생님께서 추천해주신 실질적인 이미지 augmentation(Horizontal Frlip, ShiftScaleRotation 등등)은 일률화 단계로 진행했던 augmentation 후에 추가로 붙여주면 되는것이고 이것은 training set에만 적용되어지고 validation set는 이부분 필요없이 일률화단계로 생각했던 crop과 resize만 적용하면 되는 것이 맞을까요?
좋은 강의와 답변 해주셔서 항상 감사드립니다.
0
안녕하십니까,
음, 제 생각엔 validation 데이터 세트에 판별하기 어려운 image가 상대적으로 많은 것 같습니다.
1. 먼저 class 별로 학습과 검증 데이터 세트가 균일하게 만들어 졌는지 확인해 보십시요. meta dataframe등을 만들어서 value_counts() 등으로 class 별 건수가 어떻게 되는지 확인해 보시면 됩니다.
2. 학습된 모델로 검증데이터에 predict()를 수행해서 어떤 클래스가 주로 틀리는지 확인해 보십시요.
위 사항 수행해보시고, 결과 update 부탁 드립니다. 이후에 다시 논의해 보시지요. 그리고 한번 돌릴때 마다 꽤 많은 시간이 소모 되는 것 같습니다. colab이나 kaggle 커널을 이용해 보시는건 어떠 신지요? 아님 256 사이즈에서 mobilenet v2 등으로 학습을 해보시는것도 좋을 것 같습니다. 일반적으로 efficientnet은 이미지 사이즈가 커야 성능이 제대로 나오는 것 같은데, 이러면 시간이 너무 오래 걸립니다.
0
안녕하세요 선생님
틈틈히 하다보니 시간이 오래 걸렸네요...ㅠㅠ 처음 시작할 때에 이미지 개수를 늘리면 조금 도움이 되지 않을까 싶어서 2만8천장 정도의 이미지를 4만2천장 가량까지 증가시켰습니다.
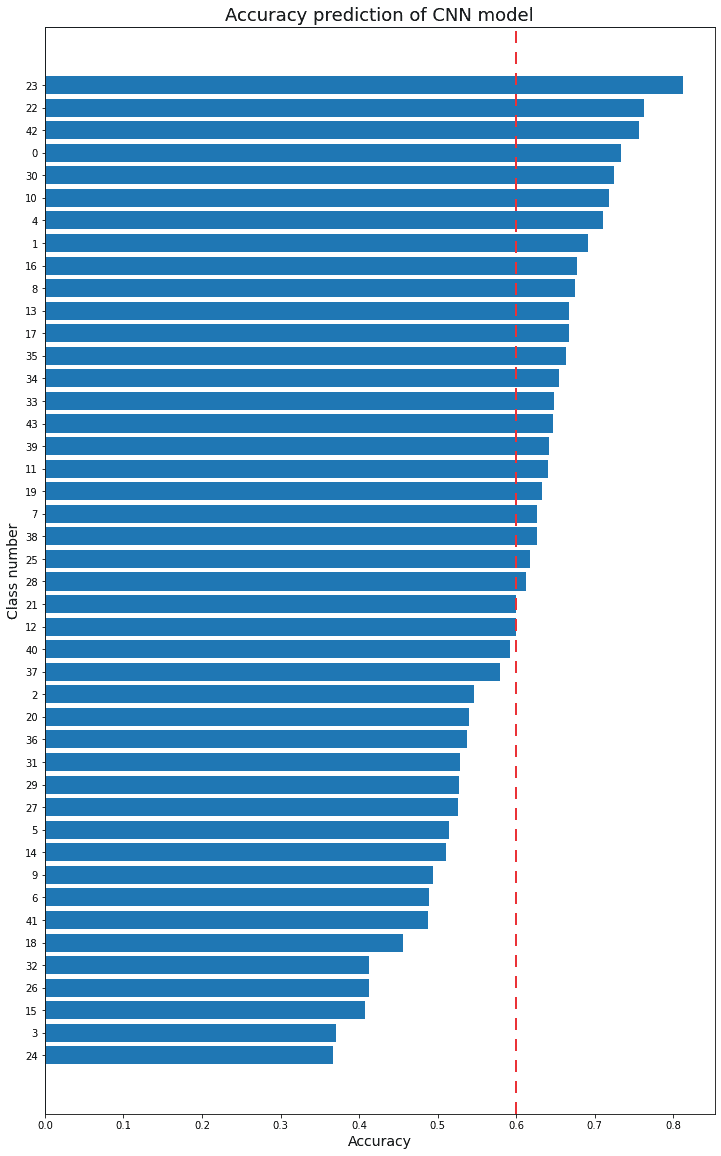
일단 데이터는 train, validation 모두 비슷한 비율로 분포되어 있었습니다. 아래 그림을 보시면 비율에는 큰 차이가 없고, 개수가 많은 세트들이 있긴 하지만 전체에 영향을 심각하게 줄 정도라고는 생각되지 않습니다..

그리고 클래스마다 정확도를 분석해 보았는데 특별히 몇개만 잘맞추고 못맞추고 하기보단 전체적으로 어느정도 학습을 하고 있는데, 전반적인 성능이 잘 안되는거 같이 보입니다. validation set에 class별 정확도 그래프 입니다.
시간이 오래 걸려서 256 사이즈로 주로 진행 했었는데, 이미지들의 원본 사이즈들은 1000,1000아래로 분포하고 있지만 큰 이미지들도 꽤 있어서 해상도를 높이면 더 학습에 도움이 되지 않을까하고
efficientnetB4 모델로 512,512 이미지 사이즈, 배치8로 학습을 진행해보았습니다.
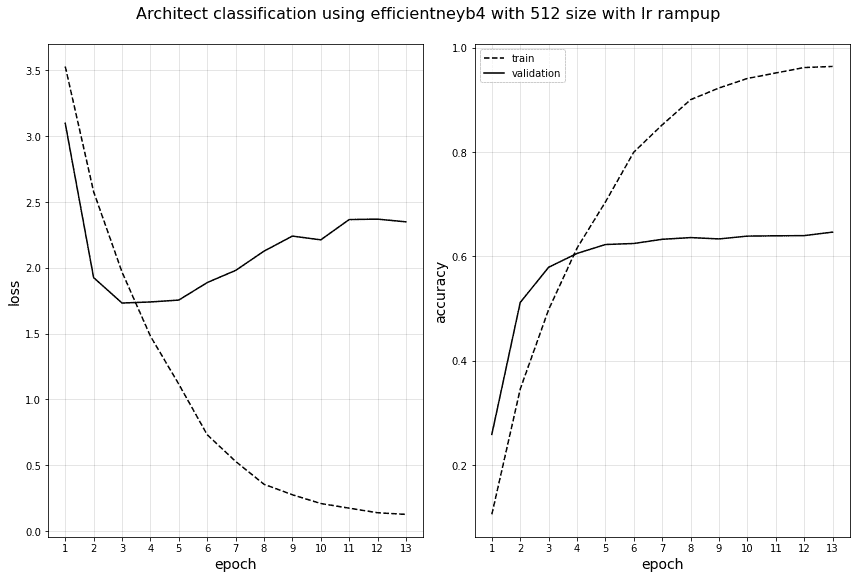
이게 지금까지 했던 것 중에서 성능이 가장 높기는 한데... 64% 근처까지 올라가더라구요. 256사이즈로 진행할때에는 거의 60이 마지노선이었는데, 초반까지 올라간걸 봐서는 512사이즈로 키운게 조금 도움이 된 것인지, 이미지 개수를 늘린것이 도움이 된것인지, 운이 좋았던건지 추측하기가 힘드네요...
보시면 5정도까지는 학습하는것처럼 보이다가 오버피팅이나고, 재밌는건 val_acc는 비슷한데 loss가 상승한다는 점이네요.. 아마, 틀린 답에 대해서 더 확신을 가지고 (틀린걸 더 틀리고) 있어서 그런것이 아닌가 싶습니다. 이 부분이 train set과 val set이 다른유형의 이미지들이 많음을 말해주고 있지 않나 싶습니다...
제가 하는 것과 매우 유사한 연구를 한 논문이 있는데
https://arxiv.org/ftp/arxiv/papers/1812/1812.01714.pdf
여기에서도 test acc가 73%인 것을 보고 저도 70초반 정도만 나와도 성공적일거라고 생각하고 있습니다. 사실 논문에 나온 건축가들은 제가 선택한 건축가들보다 특징이 더 뚜렷해서 건축가들을 그런 사람들로 바꾸면 비슷한 성능까지는 나올 수 있을 것 같은데.... 이건 최후의 보루로 생각해보고자 합니다 ㅠㅠ
validation set에서 틀린 이미지들을 라벨과 함께 찍어보았는데, 보면 또 틀릴만 한 것 같아서.. 이 task자체의 한계인것인가 하는 생각도 듭니다...
선생님 고견 부탁드립니다...ㅠㅠ
0
아, 그리고 lr 때문인건가 해서 똑같은 512사이즈 efficientnetB4모델로 테스트를 2개 해보았는데...
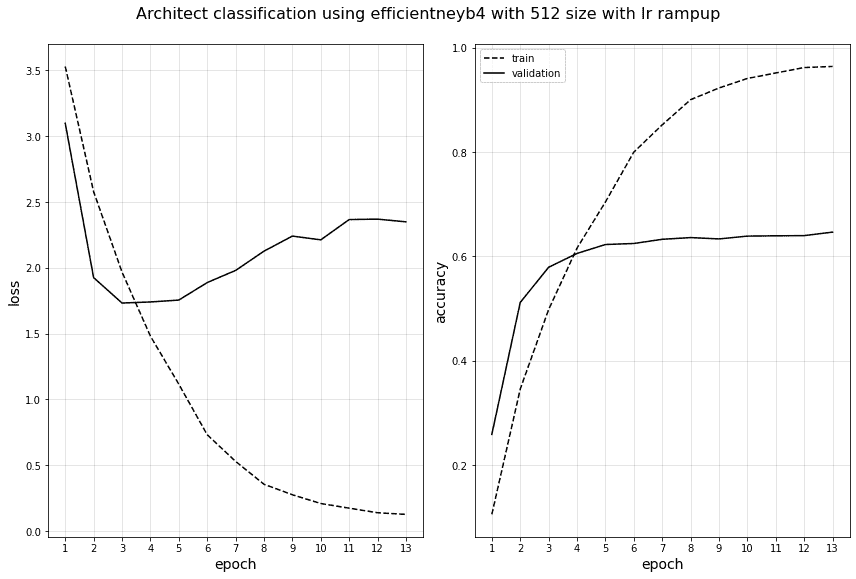
위에 올린 그림은 기존에 수업에서 가르쳐주셨던 램프업 방식으로 1e-5에서 시작하고 1e-4맥스로 갔다가 1개씩 sustain하고 decay하는 것을 사용했습니다. 트레이닝도 그렇고 굉장히 빠르게 수렴하는걸 볼 수 있는데


이건 0.001부터 시작해서 천천히 decreasing하는 모델인데 수렴하는 속도도 굉장히 느리고, val_acc도 local minimum에 갇혔는지 40쯤에서 움직이지가 않네요..
이부분도 보여드리면 좋을 것 같아서 추가로 올렸습니다. :)
resize 질문
0
60
1
20251212 Kaggle 런타임에 scikit-learn 설치 실패 트러블 슈팅
0
86
1
Loss와 매트릭 관계
0
77
2
Boston 코랩 실습
0
171
2
배치 정규화의 이해와 적용 2 강의 질문
0
144
2
Augmentation원본에 적용해서 데이터 갯수 자체를 늘리는 행위는 의미가있나요?
0
151
2
Conv함수 안에 activation 을 넣지 않는 이유가 뭔지 궁금합니다.
0
213
2
소프트맥스 관련 질문입니다
0
215
1
강의 관련 질문입니다
0
161
2
residual block과 identity block의 차이
0
200
2
옵티마이저와 경사하강법의 차이가 궁금합니다.
1
251
1
실습 환경
0
171
2
입력 이미지 크기
0
256
2
데이터 증강
0
203
2
albumentations ShiftScaleRotate
0
211
1
Model Input Size 관련
0
294
1
마지막에 bird -> frog 말고도 deer -> frog 도 잘못된것 아닌가요??
0
206
1
일반적인 질문 (kaggle notebook사용)
0
276
2
실무에서 Augmentation 적용 시
0
347
2
안녕하세요 교수님
0
235
1
가중치 초기화(Weight Initialization) 질문입니다.
0
332
1
테스트 데이터셋 predict의 'NoneType' object has no attribute 'shape' 오류
0
412
1
학습이 이상하게 됩니다.
2
1041
2
boston import가 안됩니다
0
230
1