




연습문제 lock을 써서 해봤는데 결과가 안나오는데 한번 봐주시면 감사하겠습니다.
349
작성한 질문수 21
저는 core개수를 미리 파악하는것은 생각못하고 그냥 쓰레드를 20개 만들어서 20개의 쓰레드들이 5만번씩 소수를 구하는 식으로 하려고 했었는데 prime배열과 최종답인 p_cnt는 쓰레드들이 공유하므로 atomic으로 설정해주었고 이 데이터들에 대해 spinlock을 써서 접근하도록 하였습니다.
전체 코드는
//소수 구하기
class SpinLock {
public:
void lock() {
bool expected = false;
bool desired = true;
while (!_locked.compare_exchange_strong(expected, desired)) {
expected = false;
}
}
void unlock() {
_locked.store(false);
}
private:
atomic<bool> _locked = false;
};
SpinLock spinLock;
atomic<int32> p_cnt = 0;
atomic<int32> Prime[1000001];
const int32 MAX_NUMBER = 1000'000;
void GetPrime(int first) {
int n = first + 50000;
for (int i = first; i*i < n; i++) {
for (int j = i * i; j < n; j += i) {
{
lock_guard<SpinLock> lock(spinLock);
if (Prime[j] == 1) continue;
Prime[j] = 1;
}
}
}
for (int i = first; i < first + 50000; i++) {
if (i <= 1) continue;
{
lock_guard<SpinLock> lock(spinLock);
if (Prime[i] == 0) {
p_cnt++;
}
}
}
}
int main()
{
vector<thread> v;
int start = 0;
for (int i = 0; i < 20; i++) {
v.push_back(thread(GetPrime, start));
start += 50000;
}
for (int i = 0; i < 20; i++) {
v[i].join();
}
cout << p_cnt;//소수의 개수
return 0;
}
입니당
답변 5
1
lock_guard<SpinLock> lock(spinLock);
cnt++;
이 부분에서 cnt가 애당초 atomic이기 때문에
굳이 위와 같이 락을 잡을 이유가 없습니다.
그리고 경합이 많아질 수록 당연히 성능도 떨어질 수밖에 없습니다.
각자 count 계산을 다 하고, 최종 결과만을 cnt에다 더해주면
경합없이 동작시킬 수 있는데 굳이 1을 더할 때마다 경합을 할 필욘 없겠죠.
0
class SpinLock {
public:
void lock() {
bool expected = false;
bool desired = true;
while (!_locked.compare_exchange_strong(expected, desired)) {
expected = false;
}
}
void unlock() {
_locked.store(false);
}
private:
atomic<bool> _locked = false;
};
SpinLock spinLock;
atomic<int> cnt = 0;
bool IsPrime(int n) {
for (int i = 2; i <= n; i++) {
if (n % i == 0) return false;
}
return true;
}
void PrimeCnt(int first, int last) {
for (int i = first; i < last; i++) {
if (i < 2) continue;
if (IsPrime(i)) {
lock_guard<SpinLock> lock(spinLock);
cnt++;
}
}
}
int main()
{
int result = 0;
vector<thread> v;
int first = 0;
int last = 50000;
for (int i = 0; i < 20; i++) {
//cout << first << ' ' << last << '\n';
v.push_back(thread(PrimeCnt, first, last));
first += 50000;
last += 50000;
}
for (int i = 0; i < 20; i++) {
v[i].join();
}
cout << cnt;
return 0;
}
이런식으로 백만을 구간을 20개로 쪼개서 쓰레드 20개를 생성해서 각 쓰레드가 주어진 구간을 계산하는데
이때 계산하는 방식을 전역변수에 lock을 쥐고 접근하는식으로 하니깐 시간이 너무 오래걸려 나오질 않네요
저는 동시에 20개의 쓰레드가 한 쓰레드당 5만번의 연산만 하면 되니까 될줄 알았는데 안되네용 애초에
이 문제는 소수의 개수를 전역으로 선언해서 쓰레드들끼리 lock으로 접근하게 하면 안되는 문제인가요..?
0
살짝 봤는데 일단 소수 판별 코드가 잘 이해가 안 갑니다.
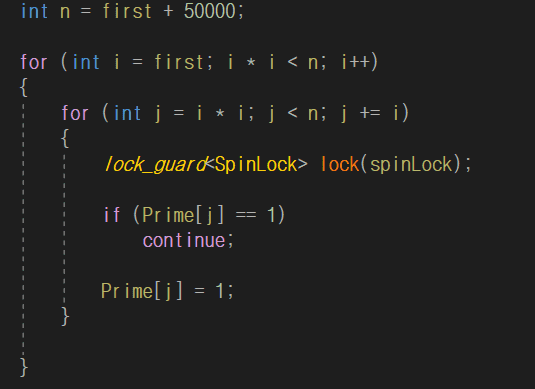
여기서 j = i*i를 하셨는데 i가 100만 까지 가는 상황이라 필연적으로 overflow가 일어납니다.
실제로 제 환경에서는 크래시가 나네요.
CS 기초 지식이 필요없는 세상이 오지 않을까요?
0
27
2
DeadLock 탐지에서 재귀 Lock 상황에 대해 궁금합니다.
0
46
2
LockFreeStack #2에서 ABA 문제
0
50
1
RefCounting 강의 질문있습니다.
0
70
2
writeLock을 잡을때 꼭 empty 상태여야하는 이유?
0
94
2
Memory Pool에서 오버플로우 질문입니다.
0
112
2
포토폴리오 및 진로 관련하여 고민입니다.
0
209
1
포토폴리오 관련 고민입니다.
0
117
1
실무에서도 alloc, 스마트포인터 등을 구현해서 쓰는지 궁금합니다.
0
126
2
성능 테스트 결과
0
129
2
게임 서버 Stateful, Stateless 진로 고민
0
167
1
WaitOnAddress와 Sleep의 차이 질문
0
120
1
궁금한거 있습니다.
0
105
2
JobTimer 구동 스레드
0
135
2
TryPop() 동작 관련 질문
0
99
1
로드맵 C#서버 C++서버 방향성 질문
0
189
2
스레드 id를 출력할떄 메인스레드 id도 출력되나요?
0
94
1
생명주기를 위한 의도적 복사
0
112
2
락프리의 실무에서 사용 질문
0
175
2
32bit threadID와 16비트 상위 WriteFlag에 대해
0
123
2
mutex와 sleep 차이점
0
148
1
실무에서는 어떠한 코드 스타일을 사용하는지 궁금합니다
0
182
2
Stomp Allocator의 Release함수에 대한 질문입니다.
0
115
1
공부법 관련해서
0
202
2