




랜덤포레스트 배깅방식으로 데이터 샘플링 예제에서
352
작성한 질문수 104
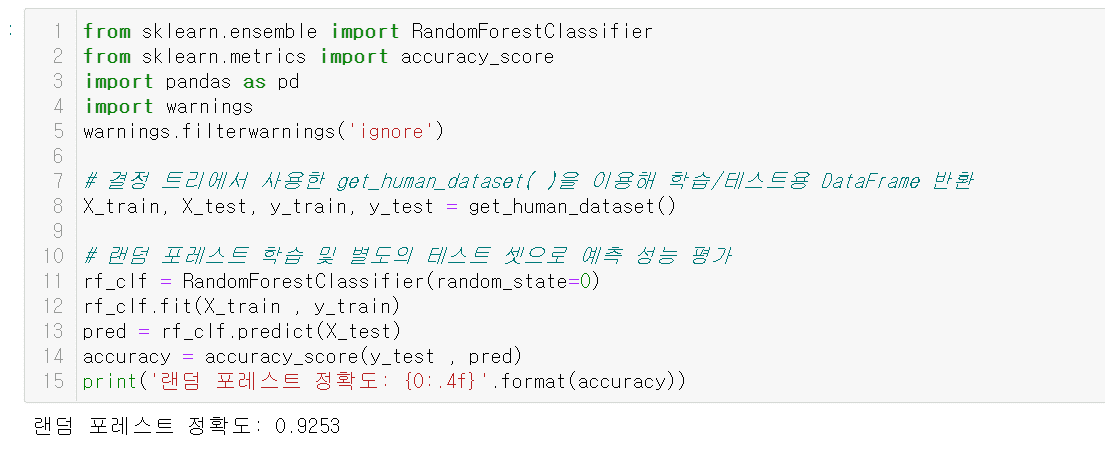
선생님~
랜덤포레스트에서 배깅방식으로 데이터샘플링을 하는 부분을 확인할 수 없어서 질문합니다.
궁금한 점이 X_train 데이터는 총 7352개 행이 있는데(shape(7352, 561))
랜덤포레스트의 n_esitmator의 기본값이 100이므로,
7326개의 데이터를 랜덤하게 샘플링을 하여
각각 다른 샘플링 데이터(중첩되기도하는) 들을 100개의 분류기에 학습을 시킬텐데..
100개 분류기마다 들어가는 각 샘플링 데이터의 수가 가변적이겠지만
대략 평균적으로 몇 개정도 들어가는지는 알 수 없는건가요~?
각 분류기에 들어가는 데이터 수를 지정하는 파라미터로 max_samples라고 알고 있는데,
이게 None으로 기본값이 되어있을 때는 어떻게 랜덤샘플링 데이터 수가 지정이 되는지 궁금합니다.
답변 1
모델 서빙과 관련된 강좌가 출시되는지 질문드립니다.
0
55
2
안녕하세요 열심히 수강중인 학생입니다
0
91
2
정수 인덱싱
0
86
2
넘파이 오류
0
112
2
11강 numpy의 axis 축 질문 드립니다.
0
107
2
Kaggle 에서 Santander customer satisfaction data 를 다운로드 되지가 않습니다.
0
96
2
Feature importances 를 보여주는 barplot 이 그래프로 안보여져요.
0
79
2
타이타닉 csv 파일이 주피터 화면에 보이지 않습니다.
0
83
2
타이타닉 csv 파일이 주피터 화면에 보이지 않습니다.
0
74
2
5강 강의 오류가 있어요.
0
90
1
실무에서 LTV 관련 모델 선택 질문입니다!
0
81
2
14강 강의 듣는중에 궁금한게 있어서 질문합니다~
0
78
3
파이썬 다운그레이 후 사이킷런 재설치
0
131
2
좋은 강의 감사합니다.
0
80
2
scoring 함수 음수값
0
72
2
6번 강의에 사이킷런, 파이썬, 아나콘다 각각 버전 일치 안 시키고 진행해도 강의 따라가 지나요?
0
108
2
분류 평가 정확도 예측
0
89
2
안녕하세요. 강의 들으면서 업무에 적용하고 싶은 수강생입니다.
0
114
1
카카오톡 채널 있나요
0
119
1
혹시 강의에서 사용하시는 ppt 받을 수 있는건가요
0
193
2
pca 스케일링 관련하여 질문드립니다.
0
109
2
주피터 대신 구글 코랩
0
184
2
강의에서 사용하는 pdf or ppt자료는 따로 없는 건가요?
0
156
2
실루엣 스코어..
0
93
2