




세션 종료
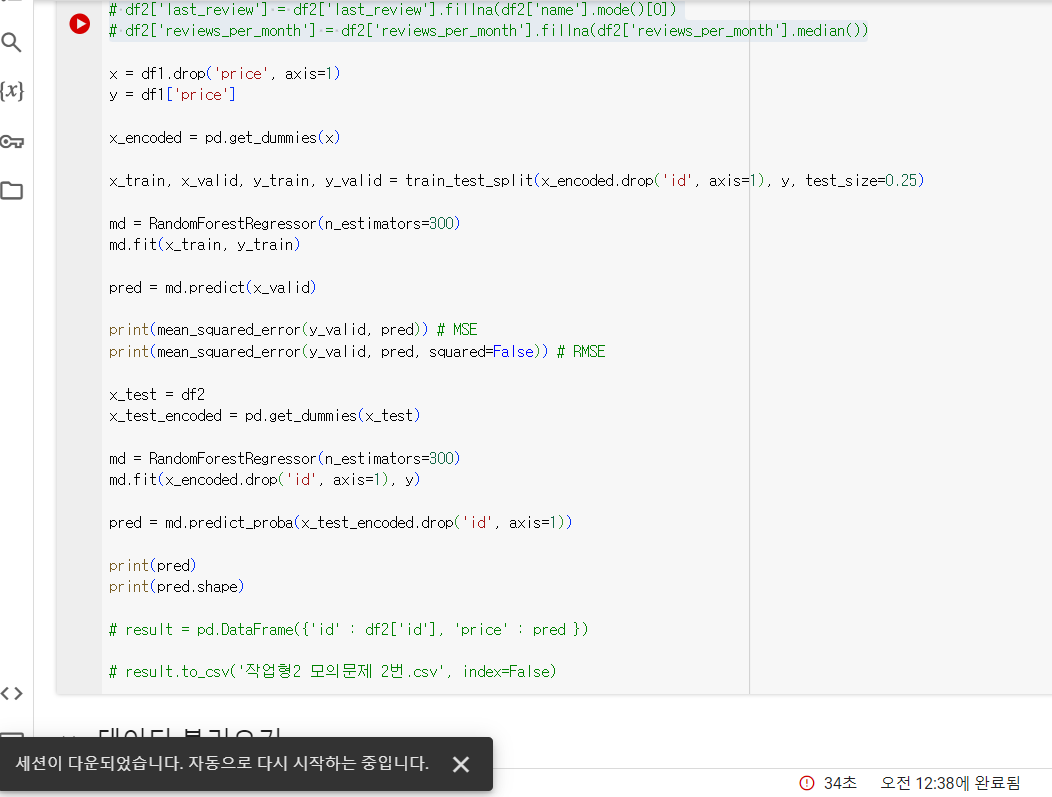
코드 작성하고 실행 시켰는데 세션이 다운됐어요. 왜 이런걸까요??
코랩 자체에서 무료 제공하는 리소스를 모두 소진한 줄 알았는데, 다른 문제들에 대해서는 아직 잘 돌아갑니다.
제가 작성한 코드도 같이 올려둘게요!
import pandas as pd
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
df1 = pd.read_csv('/content/drive/MyDrive/bigdata(빅분기 놀이터)/작업형2 모의문제/모의문제 2번/train.csv')
# print(df1.head())
# print(df1.info())
# print(df1.shape)
df2 = pd.read_csv('/content/drive/MyDrive/bigdata(빅분기 놀이터)/작업형2 모의문제/모의문제 2번/test.csv')
# print(df2.head())
# print(df2.info())
# print(df2.shape)
df1['name'] = df1['name'].fillna(df1['name'].mode()[0])
df1['host_name'] = df1['host_name'].fillna(df1['name'].mode()[0])
df1['last_review'] = df1['last_review'].fillna(df1['name'].mode()[0])
df1['reviews_per_month'] = df1['reviews_per_month'].fillna(df1['reviews_per_month'].median())
df2['name'] = df2['name'].fillna(df2['name'].mode()[0])
df2['host_name'] = df2['host_name'].fillna(df2['name'].mode()[0])
df2['last_review'] = df2['last_review'].fillna(df2['name'].mode()[0])
df2['reviews_per_month'] = df2['reviews_per_month'].fillna(df2['reviews_per_month'].median())
x = df1.drop('price', axis=1)
y = df1['price']
x_encoded = pd.get_dummies(x)
x_train, x_valid, y_train, y_valid = train_test_split(x_encoded.drop('id', axis=1), y, test_size=0.25)
md = RandomForestRegressor(n_estimators=300)
md.fit(x_train, y_train)
pred = md.predict(x_valid)
print(mean_squared_error(y_valid, pred)) # MSE
print(mean_squared_error(y_valid, pred, squared=False)) # RMSE
x_test = df2
x_test_encoded = pd.get_dummies(x_test)
md = RandomForestRegressor(n_estimators=300)
md.fit(x_encoded.drop('id', axis=1), y)
pred = md.predict_proba(x_test_encoded.drop('id', axis=1))
print(pred)
print(pred.shape)
result = pd.DataFrame({'id' : df2['id'], 'price' : pred })
result.to_csv('작업형2 모의문제 2번.csv', index=False)
답변 1
로지스틱회귀, 회귀
0
25
2
회귀 문제를 풀때 질문입니다.
0
31
1
불균형 처리 후 성능이 더 낮아졌다면,
0
43
2
실기 체험 제2유형 에러 문의
0
34
1
LIGHTGBM 으로 하면 pred값이 소수점 6자리까지 나오는게 맞나요
0
33
2
3번문제 등분산 가정
0
34
2
작업형3 target 형 변환 질문
0
29
2
[작업형1] 연습문제 섹션1 ~ 10 의 section4
0
23
3
원핫인코딩과 레이블 인코딩에서 concat
0
42
2
제2유형 질문입니다.
0
39
2
C()
0
36
2
작업형 2에서 strafity 적용 유무
0
43
2
수강 기간 연장 가능 여부 문의드립니다.
0
45
1
ols
0
36
2
2유형 작성관련 질문(일반 심화)
0
29
2
2유형 작성관련 질문
0
26
2
2유형 object컬럼 개수 다르면
0
36
2
코딩팡질문이요ㅠㅠ
0
36
2
관찰값과 기대값의 개념이 헷갈립니다.
0
19
2
작업형2 ID 컬럼 삭제 질문
0
38
2
2유형 작성관련 질문
0
27
2
memoryerror 질문
0
20
2
작업형 유형2 이렇게 고정 템플릿으로 가져가도 될까요?
0
37
1
ID 삭제 필수 인가요?
0
33
3