




원핫 인코딩
229
작성한 질문수 5
학습 관련 질문을 남겨주세요. 상세히 작성하면 더 좋아요!
질문과 관련된 영상 위치를 알려주면 더 빠르게 답변할 수 있어요
먼저 유사한 질문이 있었는지 검색해보세요
안녕하세요.
섹션4 작업형2에서 원핫 인코딩을 배울 때는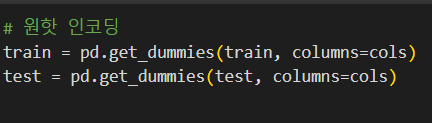 이렇게 배웠었는데 기출문제를 풀 때는
이렇게 배웠었는데 기출문제를 풀 때는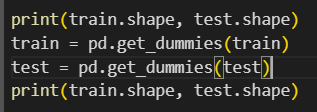
이렇게 해서 똑같이 원핫 인코딩을 해주는데
두개의 방식의 결과는 차이가 없는거죠?
그러면 기출문제 풀이가 더 간단하니까
아래 방식대로 하는게 나은거 겠죠?
train=pd.get_dummies(train)
test=pd.get_dummies(test)
답변 2
0
기출 3회 2유형 한가지방법으로 풀기 질문있습니다.
1) 데이터불러오기 생성 질문
import pandas as pd
train = pd.read_csv("https://raw.githubusercontent.com/lovedlim/inf/refs/heads/main/p4/3_2/train.csv")
test = pd.read_csv("https://raw.githubusercontent.com/lovedlim/inf/refs/heads/main/p4/3_2/test.csv")
일단 이렇게 먼저 데이터 불러오고 생성하는것은 기본적으로 시험환경 사이트처럼 다 train = pd.read_csv('train.csv), test = pd.read_csv('test.csv) 이렇게 다 제공이 되는거지요?
2) 데이터 전처리, 피쳐엔지니어링 측면에서 숫자는 스케일링도 해줘야하는데, 한가지방법 통일 해다영상에서는 일부러 안하신건가요? StandardScale이나 MinMaxScaler를 안하시고, 베이스라인측면에서만 원핫 인코딩을 진행하고, 추후 성능개선때 스케일링을 하라는 의미로 받아들여야하는걸까요? 굳이 스케일링까지 안해도 되는거면 저야 땡큐지만 그냥 영상에서 강의하시는 내용만 보면 스케일링 안하시길래... 궁금하여 여쭤봅니다.
기출 11회 작업형 2_전체 데이터 학습 여부
0
11
1
예측값 결과 소수점 차이
0
16
2
기출 문제와 실전챌린지 연습문제 무엇부터 푸는게 나은가요?
0
13
0
전처리 train() test([ ])
0
14
2
작업형 1 배경지식 질문
0
17
2
옳게 풀은건지 질문드립니다!
0
13
1
roc_auc_score
0
22
2
추가질문 합니다
0
13
2
시험환경 구름
0
16
2
2유형 질문드려요
0
13
2
RandomForest vs lgb
0
22
2
전처리 관련질문
0
21
3
작업형3 기출
0
15
2
유형2에서 데이터분할 생략 가능여부
0
27
2
9회 기출 유형3 질문
0
16
2
lgb 기초편
0
12
1
괄호 사용
0
20
2
작업형 2 데이터 전처리 질문
0
20
1
11회 기출 유형 작업형1 문제 3-1
0
17
1
예시문제 작업형2 (ver2023) 질문입니다
0
19
2
Data type에 따른 처리
0
19
2
데이터 전처리 관련
0
17
2
시험에서 문제 불러오기
0
18
2
2번문제 출력값 질문
0
25
2