




feature map - ssd에 대해서 질문이 있습니다
537
작성한 질문수 158
안녕하세요
ssd의 이해 2강에서 anchor box 설명 전 feature map 기반으로 object detection 설명에서 질문이 있습니다
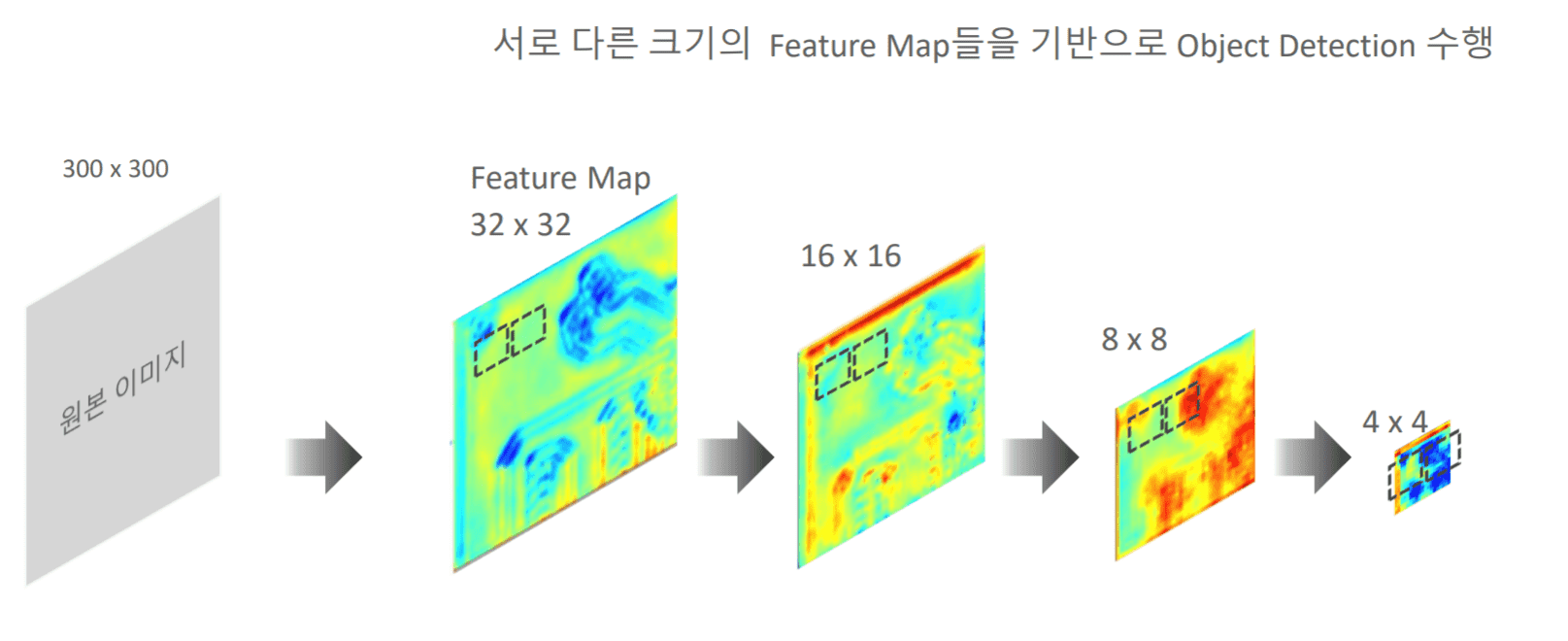
다음 그림에서 질문이 있는데, feature map이라는 것이 일정 크기의 필터 64개, 128개를 거쳐서 나온 결과값이라고 알고 있는데, 그러면 위에 32x32는 원본 이미지에서 약 10x10사이즈의 필터를 거쳐서 나온 결과값으로 이해하면 될까요? 그러면 이런 값들은 원본 이미지의 특성을 잘 나타내는 값이라고 보면되는거죠?
그리고 이어서 나오는 16x16이나 8x8도 3x3의 사이즈의 필터를 거쳐서 나온 것이고요? 이런 특성값과 여러개의 피쳐 맵을 통해서 객체가 어디 있는지 윈도우 사이즈에 의해서 판단하는 것이고요?
감사합니다
답변 4
2
Object Detection이 아니라 Image Classification을 예를 들어서 말씀드리면,
1. raw 픽셀 단위 자체로 classification하는 로직은 현재의 CNN 대비 성능이 나오지 않았습니다. Pixel은 예외, 변형, 공간 적용등의 이슈가 너무 크기 때문입니다.
2. 그렇다고 feature map만으로 classification을 하는것도 아닙니다(얼핏 보면 그렇습니다만). Kernel(filter)이 적용되어서 feature map으로 생성되었을때 이 결과를 학습하는 것을 기반으로 classification을 수행합니다. 마치 안경점에서 사물을 상세하게 보는게 아니라 보다 광범위하게 사물을 인식할 수 있는 매직 안경알(안경알이 여러개가 겹친, 여기서는 kernel로 보시면 됩니다)을 통해 사물을 인식하는 것입니다. 이 매직 안경알들은 여러개가 있으며, 이를 통과할 때마다 feature map이 만들어지고 이를 통해 사물을 인식합니다.
Deep learning CNN은 사물을 인간이 보는것과 같이 인식할 수 없습니다. 사물을 공간적/색깔적 상세함을 제외하고 중요 특징적인 요소들을 통해 인식 할 수 있도록 알고리즘 되어 있습니다. 그럼에도 불구하도수많은 이미지들을 통해 해당 특징적인 요소들에 대한 인식이 강화가 되면, 인간 못지 않게 잘 이미지를 판단할 수 있습니다. 하지만 이런 알고리즘적 제약으로 학습량이 적은 이미지는 잘못 판단하기 쉽습니다.(인간은 한번만 새로운 이미지를 보고도 잘 판단 할 수 있습니다.)
0
안녕하십니까,
전체적으로 맞는 말씀이십니다.
다만 일반적으로는 32x32 feature map이 원본 이미지에서 10x10 사이즈 필터를 바로 거쳐서 10분의 1 사이즈의 feature map으로 나오진 않고, 여러번 Convolution 연산(예를 들어 3x3 사이즈 필터를 여러번 통과 시키고, Pooling 수행)을 거쳐서 나옵니다. 가령 위에서는 원본 이미지를 VGG내에 여러 Convolution 연산을 통해 32x32 feature map으로 만들어집니다.
만들어진 feature map은 원본 이미지의 중요한 특징(feature)들이 형상화 된것입니다. 이들 피처맵 상의 객체들을 찾는 것이 바로 object detection의 핵심 로직 입니다.
감사합니다.
MMDetection 버전 이슈
0
57
2
강의 환경설정 질문
0
64
2
Custom Dataset에서의 polygon 정보 관련
0
114
3
cvat.ai 보안 수준이 궁금합니다
0
100
2
캐클 nucleus 챌린지 runpod 실습 코드 에러 질문드립니다.
0
120
3
추론 결과의 Precision(또는 mAP) 평가 방법
0
96
2
mmdetection mask rcnn inferenct 실습 시 runpod 템플릿 관해서 질문드립니다.
0
70
2
runpod에서 google drive 연결 시 오류 발생
0
128
2
로드맵 선택
0
74
1
mmcv
0
66
2
Anchor box의 Positive 처리 위치
0
71
2
해당 강의 runpod 적용 후 에러 제보드립니다
0
97
2
run pod credit 관련 제보
0
127
2
mmdetection 2.x과 3.x 호환 관련 표기
0
89
2
mm_faster_rcnn_train_kitti.ipynb 실행 오류
0
115
3
질문 드립니다.
0
89
3
mm_faster_rcnn_train_coco_bccd 실행 오류 질문드립니다.
0
90
1
강사님께 수정을 제안드리고 싶은 것이 있습니다.
0
103
1
google automl efficientdet 다운로드 및 설치 오류
0
87
1
이상 탐지에 사용할 비전 기술 조언 부탁드립니다.
0
112
2
OpenCV 관련 질문드립니다.
0
88
2
mmcv 설치관련해서 문의드려요
0
360
3
강의 구성 관련해서 질문이 있습니다
1
141
2
모델 변환 성능 질문드립니다.
0
129
1