




Boston 주택 가격에서, scailing 안하면 값이 발산합니다.
안녕하세요.
여러가지를 해보던 중, boston 주택가격 실습에서 MinMaxSclaer를 적용하지 않고, 한번 그대로 값을 넣어 gradient descent를 수행하니, loss function이 발산해버리는 현상을 발견했습니다.
혹시 이러한 결과가 나온 원인이 무었일까요??
어쨌든 gradient descent는 값의 범위에 상관 없이 항상 loss function의 값이 작아지는 방향으로 이동하는 것으로 이해했는데, feature들 간의 값의 차이가 있어서 loss function의 값이 발산하는것이 왜 그렇게 되는지 이해가 잘 되지 않아 질문 드립니다.!!
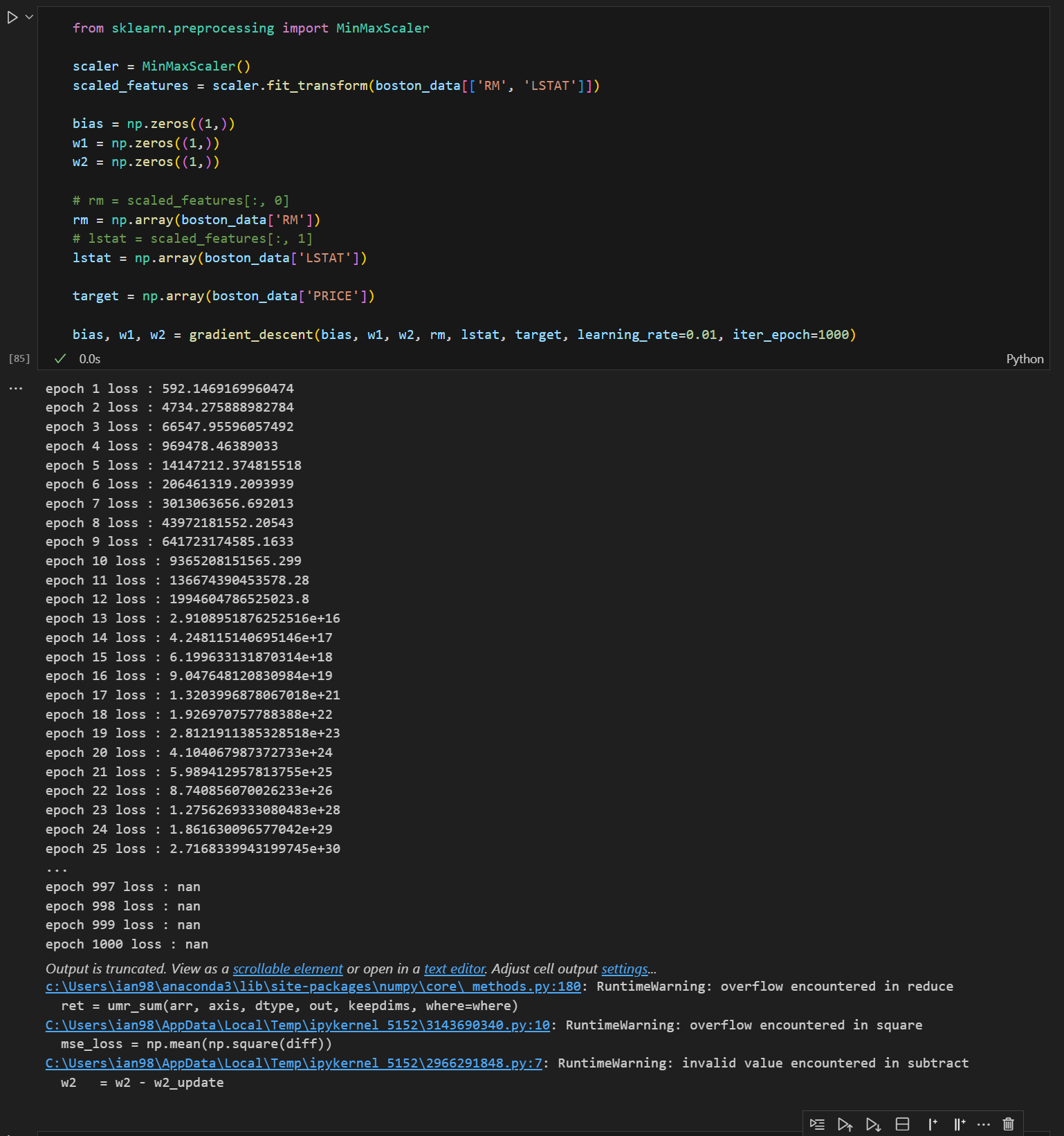
답변 1
1
안녕하십니까,
백프로 정확한 이유를 저도 잘 알지 못합니다.
Deep learning 모델은 기본적으로 Feature들을 Scaling 적용해주는 것이 좋습니다. 실습으로 보셨듯이, Feature 들의 Scaling이 적용되지 않으며 loss 가 발산되는 경우가 발생할 수 있습니다. 근데, 이런 경우는 Case by Case 인것 같습니다.
이미지 모델의 픽셀값의 경우는 CNN 모델 구축 시 Scaling을 반드시 적용하지 않아도 됩니다. 그런데 회귀와 같은 모델을 Naive한 Deep Learning 모델로 적용할 경우에는 Feature Scaling을 하지 않을 경우 보신바와 같이 loss가 무한대로 발생하는 경우가 종종 있습니다.
요약하지만 가능하다면 Deep Learning 모델은 학습 데이터에 대해서 feature scaling을 적용하시는게 좋습니다.
감사합니다.
resize 질문
0
60
1
20251212 Kaggle 런타임에 scikit-learn 설치 실패 트러블 슈팅
0
86
1
Loss와 매트릭 관계
0
77
2
Boston 코랩 실습
0
171
2
배치 정규화의 이해와 적용 2 강의 질문
0
144
2
Augmentation원본에 적용해서 데이터 갯수 자체를 늘리는 행위는 의미가있나요?
0
151
2
Conv함수 안에 activation 을 넣지 않는 이유가 뭔지 궁금합니다.
0
213
2
소프트맥스 관련 질문입니다
0
215
1
강의 관련 질문입니다
0
162
2
residual block과 identity block의 차이
0
200
2
옵티마이저와 경사하강법의 차이가 궁금합니다.
1
251
1
실습 환경
0
171
2
입력 이미지 크기
0
256
2
데이터 증강
0
203
2
albumentations ShiftScaleRotate
0
211
1
Model Input Size 관련
0
294
1
마지막에 bird -> frog 말고도 deer -> frog 도 잘못된것 아닌가요??
0
206
1
일반적인 질문 (kaggle notebook사용)
0
276
2
실무에서 Augmentation 적용 시
0
347
2
안녕하세요 교수님
0
235
1
가중치 초기화(Weight Initialization) 질문입니다.
0
332
1
테스트 데이터셋 predict의 'NoneType' object has no attribute 'shape' 오류
0
412
1
학습이 이상하게 됩니다.
2
1041
2
boston import가 안됩니다
0
230
1