




예시문제 작업형 2유형 질문있습니다
import pandas as pd
train = pd.read_csv("data/customer_train.csv")
test = pd.read_csv("data/customer_test.csv")
pd.set_option('display.max_columns',None)
# EDA
# print(train.shape, test.shape)
# print(train.describe(include='O'))
# print(test.describe(include='O'))
# print(train.isnull().sum()) # 결측치: 환불금액
# print(train.isnull().sum())
# print(train.info())
# print(train.describe(include = 'O'))
# print(sorted(list(train['주구매상품'].unique())))
# print(sorted(list(test['주구매상품'].unique())))
a = set(train['주구매상품'].unique())
b = set(test['주구매상품'].unique())
print(a - b)
print(b - a)
# 데이터 전처리
train['환불금액'] = train['환불금액'].fillna(train['환불금액'].mean())
test['환불금액'] = test['환불금액'].fillna(test['환불금액'].mean())
# print(train.isnull().sum())
# print(test.isnull().sum())
# 원핫인코딩
df = pd.concat([train,test])
df = pd.get_dummies(df)
train = df.iloc[:len(train)]
test = df.iloc[len(train):]
print(train.shape, test.shape)
# 검증데이터 분리
from sklearn.model_selection import train_test_split
x_tr,x_val,y_tr, y_val = train_test_split(train.drop('성별',axis =1), train['성별'], test_size=0.2, random_state=2022)
# print(x_tr.shape,x_val.shape,y_tr.shape, y_val.shape)
# 모델 및 평가
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import roc_auc_score
model = RandomForestClassifier(random_state = 2022, max_depth=4, n_estimators=500)
model.fit(x_tr, y_tr)
pred_proba = model.predict_proba(x_val)
print(roc_auc_score(y_val, pred_proba[:,1]))
# # 0.6759
# # print(test.shape)
# # print(test.isnull().sum())
# 예측 및 제출
pred_proba = model.predict_proba(test)
train이 test를 포함할 경우 train + test 를 합쳐서 원핫인코딩을 진행했습니다.
모델 및 평가까지는 에러 없이 진행하였는 데 test 데이터를 예측하는 pred_proba = model.predict_proba(test) 부분에서 아래와 같은 에러가 발생했습니다. 어떤게 문제였는지 궁금하여 질문글 올립니다.
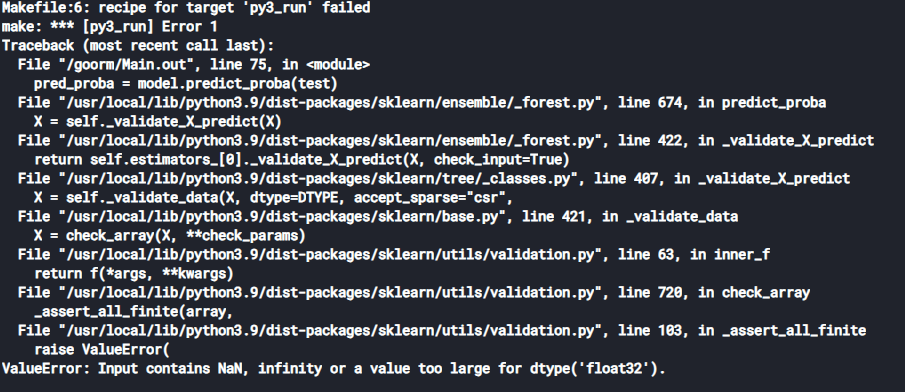
답변 1
0
NaN 값 그러니깐 결측치를 포함한 데이터를 모델에 넣었어요
데이터를 합치고 분리하고나면 샘플을 확인해보세요
train에는 성별이 있고, test는 성별이 없어요!
합치면 성별이 없는 데이터에는 NaN이 들어가고 다시 분리 시켜도 성별 컬럼이 남아 있습니다.
test 데이터에서 target(성별) 컬럼 제거(drop)가 필요해요
뒤로가기 버튼 같은 것이 있나요?
0
26
1
강의 연장 문의
0
28
1
출력값 질문
0
28
2
수업노트가 어디에 있나요?
0
28
1
실기시험 제출관련
0
160
2
6.20 작업형 2 과적합
0
167
3
코딩팡 장업형2 베이스 라인 인코딩 종류 질문
0
51
2
로지스틱회귀, 회귀
0
51
2
회귀 문제를 풀때 질문입니다.
0
58
1
불균형 처리 후 성능이 더 낮아졌다면,
0
65
2
실기 체험 제2유형 에러 문의
0
65
1
LIGHTGBM 으로 하면 pred값이 소수점 6자리까지 나오는게 맞나요
0
51
2
3번문제 등분산 가정
0
49
2
작업형3 target 형 변환 질문
0
37
2
[작업형1] 연습문제 섹션1 ~ 10 의 section4
0
39
3
원핫인코딩과 레이블 인코딩에서 concat
0
61
2
제2유형 질문입니다.
0
48
2
C()
0
44
2
작업형 2에서 strafity 적용 유무
0
52
2
수강 기간 연장 가능 여부 문의드립니다.
0
61
1
ols
0
44
2
2유형 작성관련 질문(일반 심화)
0
40
2
2유형 작성관련 질문
0
41
2
2유형 object컬럼 개수 다르면
0
48
2