





Python 無料講座 (基本編) - 6 時間で私も開発者
nadocoding
無料
入門 / Python
4.9
(1,842)
39,000+
6時間。Python開発者になるのに必要な時間です。 重要な内容だけを厳選 / 各章にクイズと解説 / 実生活に基づく例でとても簡単に説明します。 そして完全無料です。
入門
Python

Python機械学習で
映画おすすめシステムを作ろう! 🎞️

機械学習、一度は聞いたことがありますか?機械学習は人工知能の一分野であり、韓国語では機械学習というのですが、良質のデータを与えればそのデータを自ら学習してモデルというものを作るのです。このモデルを利用すれば、新しい入力値が入ったときに出力値を予測する式で、だから関数を直接作ることだと理解すればいいです。

大型遊園地は絶対一日ですべての乗り物を利用することはできません。しかし、一度訪れてみると、遊園地がどのように見え、どこにどんな乗り物があるのか、次回訪れたら何を先に乗ればいいのかという大きな絵は描くことができるでしょう。
私の講義はこのように遊園地に初めて訪れる感じで勉強してほしいです。機械学習についてすべてを知ることは難しいですが、機械学習が何なのか、学習のために考慮すべき部分が何なのか、どんな内容をもっと勉強してみると良いのかを感じるのです。そうすれば、ここで一歩進んで、さまざまな資料を通じてより深い知識を積むことができるようになるでしょう。一緒に始めましょうか?
ここにこれらの点が散らばっています。
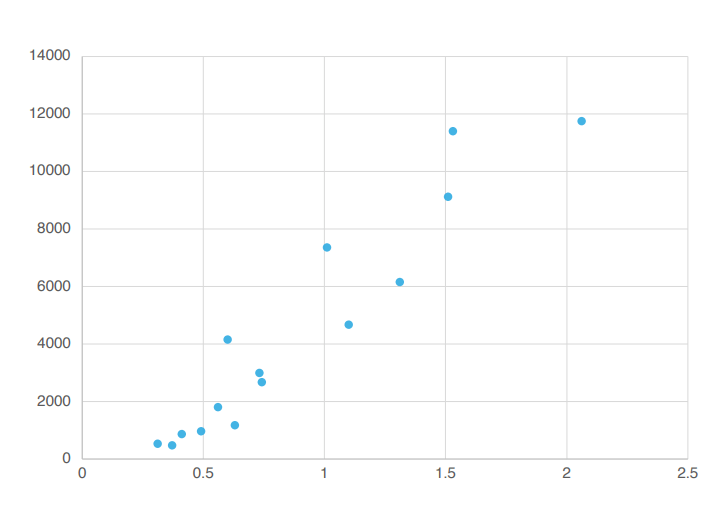
この時、これらの点を最もよく表現する直線をひとつひとつ探すなら何でしょうか?
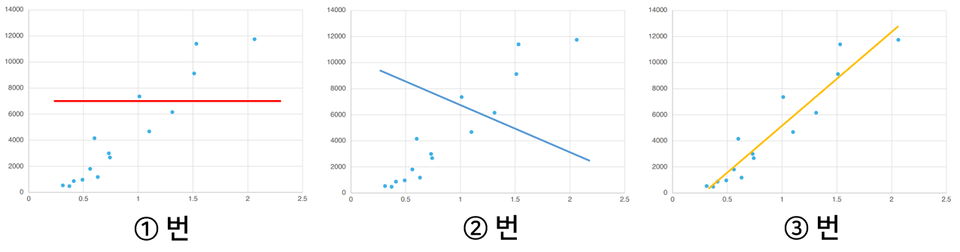
そうですね!まさに3番です。なぜそう思いましたか?はい。ちょっと見てもちょうどそう見えますか?
私たちは、機械が自分で学習を通じてモデルを作成するプロセスを経験しました。これらのモデル(ここでは直線)が作成されたら、今では予測ということを試すことができます。
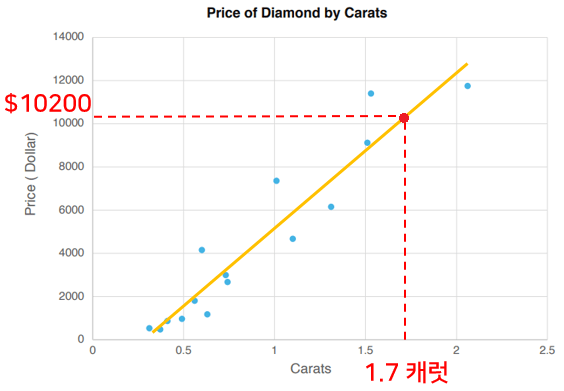
このグラフがカラットによるダイヤモンドの価格データであり、x軸がカラット、y軸が価格であるとすれば、新しい1.7カラットダイヤモンドがあるときにおよそいくらかを見積もることができるのです。このように、連続的な数値データを通じて予測することを回帰モデルといいます。
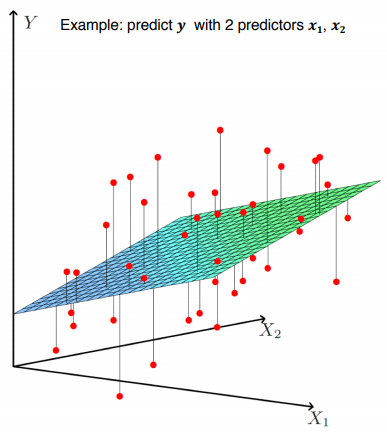
回帰モデルは時々より複雑になることがあります。例えば、勉強時間による試験スコアを予測しようとしたら、スコアに影響を与えるのが必ずしも勉強時間が1つしかないのではないでしょうか。このようにテストスコアという結果に影響を及ぼす要素を独立変数といい、その時の結果を依存変数といいます。そして、独立変数が多くなると、少し複雑な形の多重線形回帰モデルが必要になる。次元が増えながらグラフが少し複雑になると考えればいいです。
暑い夏には長い間エアコンを使うのが怖くなります。家庭用電気には累進区間があり、ちょっと使ってみると電気料がしっかり走って、そういえば数十万ウォンを大きく超える場合もできますよね。累進区間によって膜厚増加するデータのように、xの変化によってyが急激に変化するなどの場合であれば直線1つだけで表現するには多少無理がある。この時多項回帰モデルを利用してみることができます。
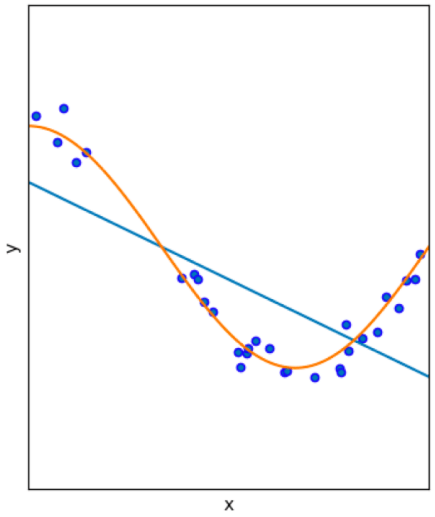
青い点のデータを表現するための2つのモデルがあるとき、直線の水色ではなく曲線状のオレンジ色がはるかに優れています!
しかし、このような予測モデルを作成したときに本当にこれがよく予測するかどうかを大胆にすることができますか?したがって、モデルを作成したら、このモデルのパフォーマンスがどれほど良いかを評価する必要があります。そうするために、データセット全体を二つに分け、一つはトレーニング用に、一つはテスト用に使いますが、通常80:20の割合で割ってトレーニング用セットだけで学習をしてからモデルが大丈夫かどうかをテストセットで検証してみます。そして、場合によってはセットを混ぜながら検証することもあります。
この過程で訓練セットについては本当によく予測しますが、テストセットについては不都合な予測をすることを過大適合といい、訓練セットすら予測がうまくいかない場合を過小適合といいます。モデルを作成するときに過剰適合や過小適合が発生しないようにすることが重要です。


このような連続的なデータではなく、カテゴリー型データということもあります。回帰ではなく分類に該当する内容です。勉強時間による試験スコアではなく、今回は資格証明試験に変えて合格/不合格に分けると見なされます。だから4時間勉強したときは合格し、6時間勉強したときは合格したというデータがあるときに7時間を勉強すれば合格か不合格かを分けることになるんです。
機械学習の代表的な分類アルゴリズムはロジスティック回帰です。名前は回帰ですが、実際には分類に使用されるモデルであり、分類モデルは必要に応じて基準を少し調整することもあります。つまりモデルでは「あなたは4時間勉強すれば合格するよ」と出てくるとしても保守的に接近して「あなたは6時間は勉強しなければならなかった」と言うのです。
これまで説明された内容は、機械学習の中で指導学習に該当する部分でしたが、機械学習には正解を知らせない非指導学習ということもあります。非指導学習は、機械が自らデータ内で有意なパターンや構造を見つけるのですが、このようなパターンを見せるデータ同士の群れをつくる群集化というものがあります。ニュース記事を科学/技術、スポーツ、健康などのカテゴリに分けるのも群集化の一例です。
群集化の代表的なアルゴリズムとしてK-平均というものがあります。あなたが果樹園で初めてリンゴを取って商品として販売するために分けるというとき、どのように分ければ一番いいのでしょうか?ただ、大きさによって大きいものと小さいもの、こうして二つに分けることもでき、大/中/小の3つの分類に、またはきれいなものと悪いものに分けてできなかったものは安く売るようにすることもできるでしょう。

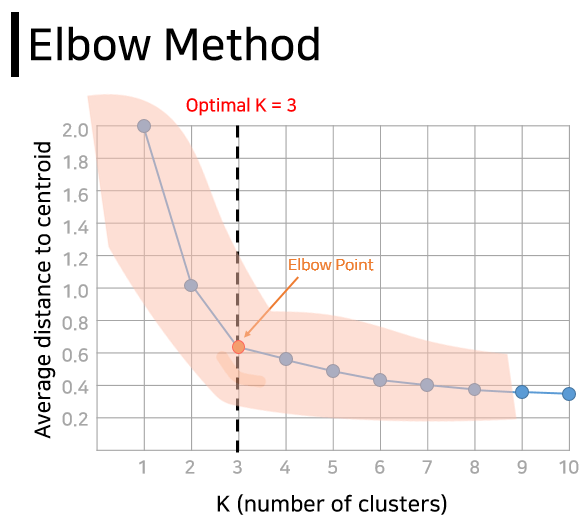
この時、いくつかのグループに該当するのがまさにKです。リンゴではなく、複雑で大量のデータをまとめると、いくつかを決めるのが難しくなります。幸い、最適なKを見つけるために参考にする方法があります。肘の形に似ているエルボーの方法です。簡単に説明すると、Kの変化に伴う各データから各クラスター(グループ)の中心点までの距離平均を計算し、グラフ上で傾きが緩やかになり始めるその時点をKで見ることです。
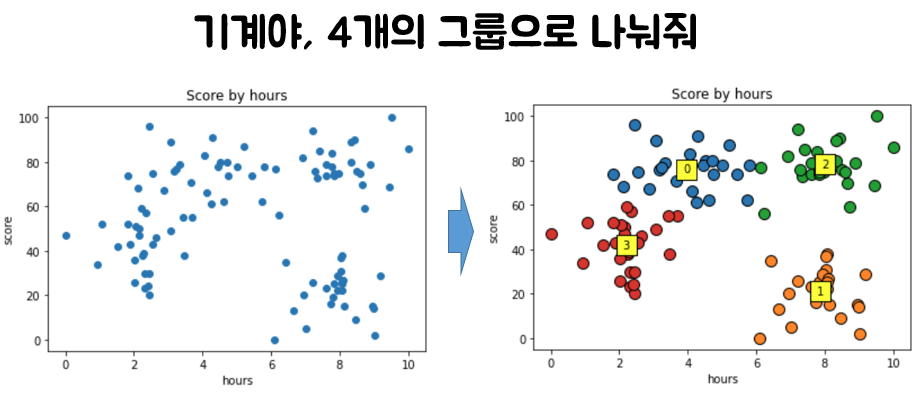
このようにKが決まったら、我々は何処に散らばっているデータから、以下のようにK個のクラスタ(グループ)に分けられた結果を得ることができるようになります。この例が試験の勉強時間によるスコアであるとしたら、各グループの友人に異なる勉強戦略を提供することもできます。
上で取り上げた機械学習の基本的な内容は、詳細な理論の説明と実習で勉強することになります。終わったらクイズを通してこれまで学んだ内容を復習します。
クイズでは、データセットだけが甘く与えられ、そのデータを持っていなければならない7つの小さなミッションがあります。基本内容をよく勉強したら十分に消化できます。そして、クイズを自分で解くことができるという言葉は、あなたが自分でデータ分離、訓練セットによる学習、データ視覚化、評価、予測までできるようになるという意味です。すごいですか? 😃
クイズを解いたら、もう何か使ってみるべきでしょう!他のすべての活用編講義もそうだったように、機械学習編でもプロジェクトを進行します。プロジェクトのテーマは映画推薦システムです。約5,000個の映画関連データセットを持ち、分析と学習を通じておすすめ映画10個を選ぶ内容を勉強します。おすすめの方法にもいくつかありますが、簡単に次の3つを勉強します。
1. 多くの人が好きな映画のおすすめ
2. 特定の映画によく似た映画を推薦
3. 個人の映画好みに応じたオーダーメイドのおすすめ
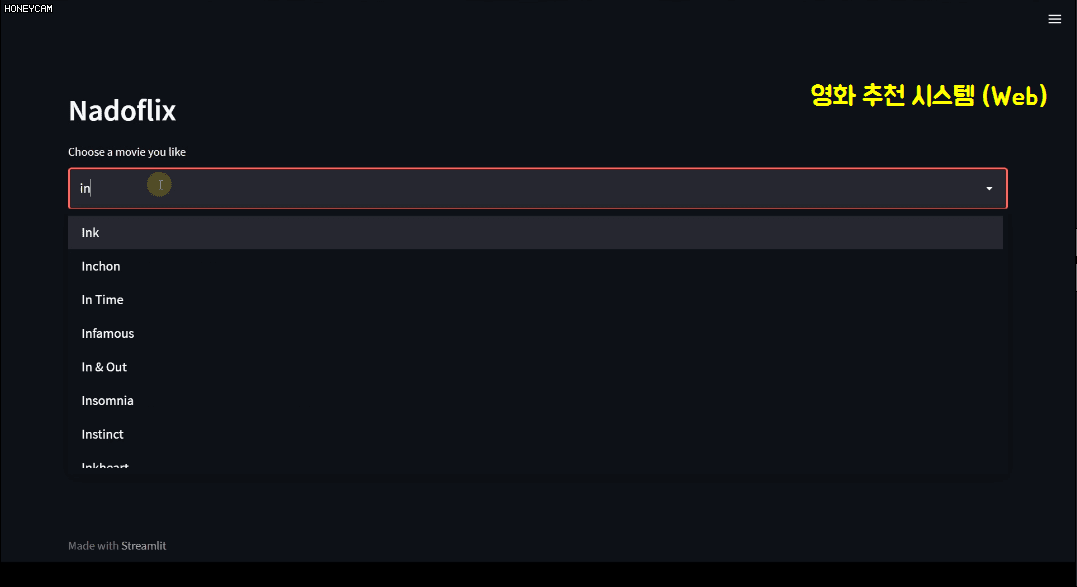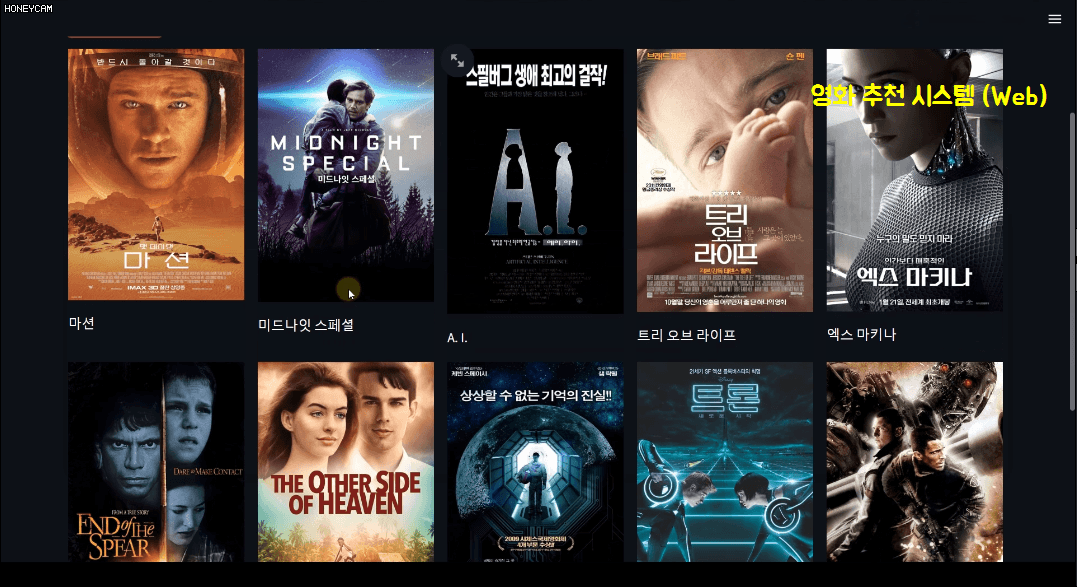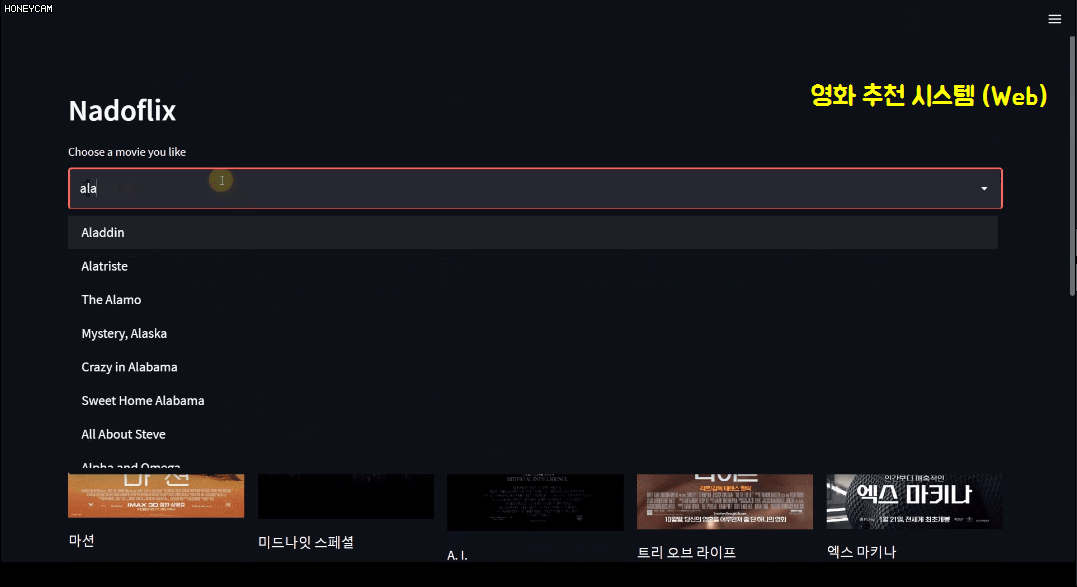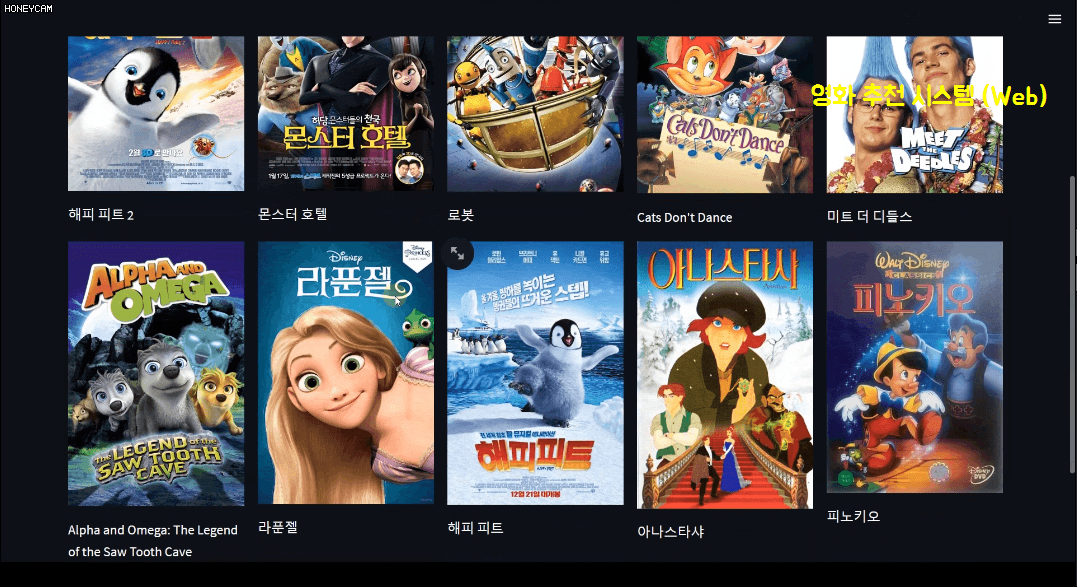
この過程でテキスト分析方法についてもある程度学ぶことになります。そしてコードだけ見れば疲れているのでstreamlitという、数行以内のコードできれいなWebページを作れるパッケージを通じて映画推薦システムサイトを直接作ってみます。ここでは、ある映画を選ぶと、その映画のジャンル、監督、出演俳優などの情報をもとにおすすめ映画10本を選んで韓国語のポスターイメージを編んだ〜と見せてくれます。そうですね?
特に最後の個人映画の好みに合わせたオーダーメイドのおすすめはSurpriseというパッケージを利用しますが、これまで積み上げられた販売履歴データを通じてどの顧客にどの商品をおすすめすれば良いのか、どのようなものをセットで販売すればよりよく売れるかなどの戦略を立てるのに大きな助けになることでしょう。
Images, Videos by pixabay, pexels
:https://www.pixabay.com
:https://www.pexels.com
Designed by freepik, flaticon
:https://www.freepik.com
:https://www.flaticon.com
グッド
良い講義をありがとうございました。
とても良い講義です!
ああ、このような良い講義がありました…本当にありがとうございました〜!
大学の講義で受けるような内容を、こんなに分かりやすく噛み砕いて聞けるのがすごく良いなと思います。


























![[ICTアーカイブ] ビッグデータの核心とビジネスモデル講義サムネイル](https://cdn.inflearn.com/public/files/courses/338811/cover/01k44rs7zkwq0ehc8vqsy2mdtb?w=420)


