





AI入門のためのLLMアーキテクチャの理解とGPU活用戦略
hyunjinkim

トランスフォーマーベースのLLMアーキテクチャとGPU活用戦略を理解し、vLLMを活用した実際のサービング過程まで直接実習します。 AIシステムパイプラインの構築からモニタリング、マルチGPUの活用まで実務フロー全体を扱い、 複雑な数式なしで図解と実習を中心に直感的に理解できるように構成された講義です。
初級
GPU, attention-model, AI



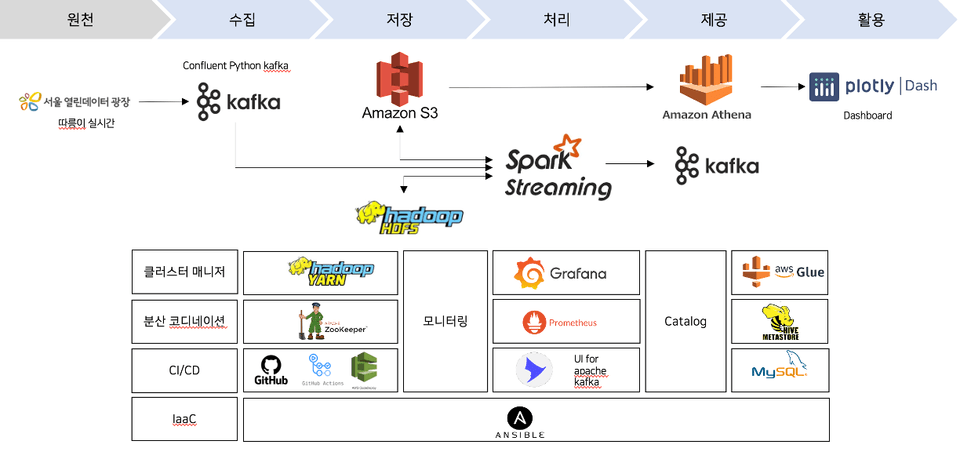
リアルタイムデータパイプラインを学びたいです。
データパイプラインには興味があるものの、リアルタイム処理は経験したことがない方

DataLakeについて知りたいです。
Cloud上に構築されるDataLakeがどのように実装されるかを学びたい方

アーキテクトとして成長したいです。
インフラ設計からコードレベルまで大容量処理が可能で堅牢なアーキテクチャ実装が気になる方



非常に完成度の高い講義でした。感動そのものです 普通、講義を聞いていると、同じようにやったのになぜできないんだ?という状況が少なくないと思いますが、そういったことなくスムーズに完講しました。 私は講義を選択するにあたり、まず最初にカリキュラムを見て、価格と講義時間を比較します。 これまで価格の割に、あまりにも表面的な講義が多かったのですが、 현진님의 kafka&spark 講義を聞けば、今後のプロジェクトでも十分に完成度の高い成果物を出すことができると断言します! 大変勉強になりました、ありがとうございます! (シーズン2はいつ頃出るのでしょうか…?)
いつも感じることですが、熟成講義よりもこのように内容が豊富で詳しく扱う方が実力を積むのにはるかに役立ちます。 本当に私のスタイルです。ありがとうございます。
信頼できる現進先生。強くお勧めします。 airflow講義から知ることになりましたが、他の講義とは異なる差別化ポイントが多いです。概念からアーキテクチャ設計まで、使用理由と原理を説明してくださるのが良かったです。実習も楽々そのものです。回答まで常に親切につけてくださいます。まだ受講初期ですが完走してみます〜 天気が暑いですが、健康に気をつけてください。
期待以上によく整理されたカリキュラムと内容で多くのことを学んで帰ります。 丁寧に講義を作ってくださったという感じをとても受けました。 後続講義を待っています。 ありがとうございます。
一つ一つ学んでいく部分が実際の業務に大きな助けになりそうです 👍




