公共データでPythonデータ分析を始める
イディヤはスターバックスの近くに入店するという説がありました。果たしてイディヤとスターバックスの店舗立地はどのくらい違いがありますか? 2013年から2019年までの不動産価格変動の傾向は、アパートの売り手にも反映されますか? 私たちの近所にはどんな公園がありますか?公共データポータルのデータをどのように活用すればよいですか?パブリックデータを通じてさまざまな形式のデータを扱い、Pythonと複数のデータ分析ライブラリに慣れることを目指しています。

お知らせ
5 件
こんにちは。講座を受講してくださった方々に感謝します。
💻証券データ収集と分析で信号とノイズを探す👉 http://bit.ly/inflearn-finace-data
講座を新たにオープンするようになりました。アーリーバード期間中に30%割引を行います。
📈証券データで信号と騒音を探す
現在も上り下りする株価データをリアルタイムで受け取り分析します。
誰かが収集したデータを使用せずに直接収集できる方法を学びます。
前処理する方法を学びます。
業務や研究に使用するデータ分析方法を身につけて適用してみることを目的としています。
📊証券データでデータ分析を学ぶのは良い理由
Pandasが証券会社で働くクオントによって開発されたことを知っていますか?
証券データは、さまざまな分析方法、式、統計などを適用してみることができるデータです。
数十、数百ページのウェブサイトの内容をエクセルに貼り付けなければならないなら?
収集したデータがあまりにも汚れていて、どこから手をつけるべきかわからないとしたら?
カテゴリー型データと数値型データにはいくつかの違いがあります
データの信号とノイズを見つけるための適切な可視化方法は?
さまざまなフォーマットのデータを扱う方法を学ぶことができます。
移動平均、ボリンジャーバンド、MACD、RSIなどの技術的分析を直接実装してみたり
すでに実装されているライブラリを介してコードを1つ2行で描画します。
技術分析の原理を理解し、
HTSやMTSで見ているように、チャートを実装してみます。
⚡️川の特徴
🧹セレニウムのような重いツールを使ってこそ収集できそうだったウェブページのデータを
ブラウザの[ネットワーク]タブを使用して、1行または2行のコードで収集する方法を学びます。
仕事や研究に必要な情報を直接収集して分析することができます。
📈静的な視覚化ツールだけでなく、動的な視覚化ツールの使い方を学びます。
🛠多くのツールを一度に習得するのは難しいです。
さまざまなツールを使用しても、コア機能だけを理解すると
ツールが変わっても文書を見て理解できる方法を知れば
新しいライブラリが登場しても怖くないでしょう。
💡私たちが必要だと感じる機能は誰かが抽象化されたライブラリで作っておきました。
新しいツールをインストールして習得する方法を学びます。
🛠学習スキルの紹介
🐼Pandas :Pythonの代表的なデータ分析ツールで、金融データ分析のために作成されました。
🧮Numpy :Pythonの数値計算ツールです。
📊 matplotlib :Pythonの代表的なデータ可視化ツールです。
📊 seaborn : matplotlib を使いやすく抽象化した高レベルの可視化ツールで基本的な統計演算を提供します。
📊 plotly :高レベル、低レベルの可視化機能を提供し、インタラクティブな可視化が可能です。
📊 cufflinks : plotlyとpandasを強力につなぐ生産的なツールです。
📈 FinanceDataReader :コードは、1つまたは2行で金融データを収集するためのツールです。
🌏 Requests :WebページのソースコードをHTTP通信で受け取ることができるツールです。
🔍 BeautifulSoup4 :Webページのソースコードから必要な情報を取得するためのツールです。
⏰ tqdm : データ収集や前処理に時間がかかる作業の進行状況を確認できます。
📊さまざまな可視化ライブラリの使い方と違い

画像ソース:https://pyviz.org/overviews/index.html
💻 コードが入力されていないファイル(input)と入力されたファイル(output)の2つの練習資料を提供
説明が書かれた空のセルに直接コードを入力し、1行1行のレッスンに従ってください。
コードが書かれているファイルで実行し、練習を進めることもできます。
講義をすべて聞いて空のセルを埋めながら復習してみることもできます。
📈HTS、MTSで見られる補助指標(移動平均、ボリンジャーバンド、RSI、MACD)を直接実装して原理を理解する

🙋♀️ 予想される質問 Q&A
•非専攻者も聞くことができますか?
データ分析は専攻/非専攻を問わず身につけておくと活用するところが多いです。 Excelの代わりにPythonを使ったデータ分析技術を学んでおけば、仕事や研究に多様に使ってみることができます。既にその内容でオフラインカリキュラムを通じて開発外職軍に企業講義を進めています。現場で困難を感じている部分について様々なインタビューを行い、カリキュラムを補完しました。分析と可視化のためのコア機能を身につければ、業務効率を高めるのに役立ちます。
•なぜPythonでデータ分析と収集技術を学ぶのですか?
エクセルはどんな仕事をしても会社員の必須スキルの一つです。しかし、Excelには読み込むことができるデータのサイズやタイプなどの制限がありますが、Pythonを通じて習得すれば、さまざまなフォーマットや大容量データも扱えるようになります。
•データ分析と収集技術を学ぶことは何ですか?
必要なデータを収集するためにページごとに引き渡され、ドラッグドロップとコピーペーストで何度も何度も何度も何度も何度も何度もやり直す必要があります。こういうことはもうPythonに任せ、⏰もう少し生産的な仕事に時間を投資したり休憩🧘♀️を取ることもできるでしょう。
•講義の受講後は何ができますか?
業務や研究で発生するデータを直接収集、分析視覚化し、生産量、在庫量、販売量、トラフィック量などに適用してみることができます。本人が投資している株価の業種やテーマ、ETFを分析する用途でも可能ですが、講義で投資意見を提示しません。
•講義を聞く前に準備する必要がありますか?
Pythonの変数、数字、文字、リストなどの概念を理解していれば役立ちます。また、平均、中央値、分散、標準偏差、百分位など中学校レベルの数学知識が必要です。
•クラスの内容をどの程度レベルまで扱いますか?
証券データを収集、前処理、分析、可視化します。 Pythonの基礎から中級までのスキルを扱います。 業種テーマ情報収集からは難易度がたくさん上がります。企画、マーケティング、営業、運営など多様な職群でデータ分析を直接活用してみることを目指します。 プログラミングが初めての場合は、講義の半ばからは難しく感じることがあります。こういうときは講師が提供している資料の中でファイル名の末尾にoutput という名前の完成したファイルを回して、すぐ下にコードセルを作って同じようにしてみることをお勧めします。•コンピュータのパフォーマンスはどのくらいでなければなりませんか?
4G以上のメモリと残りのストレージスペースが20G程度のPCやノートパソコンであれば構いません。•授業内容を個人のブログや羽毛にまとめて公開してもいいですか?
該当講義の羽毛に著作権表記がされています。まとめて公開するときはソース表記をしてください。⚠️受講前確認してください。
データ分析を学ぶと、証券市場で大きな収益を得ることができると期待される方
この講義は証券投資の講義ではなく、データ分析の講義です。残念ながら、投資に関連するスキルを期待している場合はがっかりすることができます。また、講義で学んだ分析技術を通じて投資をしたとしても、投資損失に対する責任は投資家にあります。インフラストラクチャのプレビューまたは知識共有者のYouTubeチャンネルを通じて公開されているいくつかの講義を最初に聞いて、受講するかどうかを決定してください。
受講前にいくつかの講義をプレビューできます。希望の学習方向であることを確認してください。また、ご不明な点は受講前のお問い合わせを通じてお問い合わせください。📈証券データ収集と分析で信号とノイズを探す👉 http://bit.ly/inflearn-finace-data
アーリーバード期間中30%割引予定です!
ありがとうございます。
こんにちは。
「 たった2枚の文書でデータ分析と可視化ポギー」講座を運営してから一年を超えました。
「公共データでPythonデータ分析を始める」講座のように、その講座も着実に更新を行う予定です。
「たった2枚の文書でデータ分析と可視化ポギング」講座にソウル市コロナ19発生状況分析コンテンツが追加されました。
そしてアップデート記念で7月24日までに20%割引を行います。
該当講座を受講していなくても、一部の講座を「 たった2枚の文書でデータ分析と可視化ポッティング」でご覧いただけます。
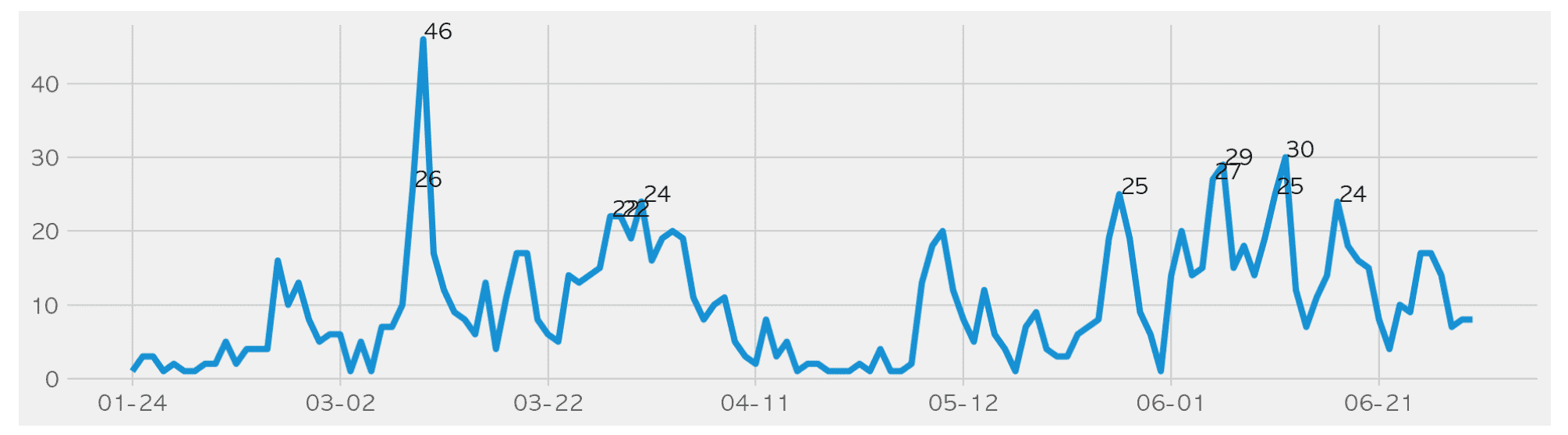
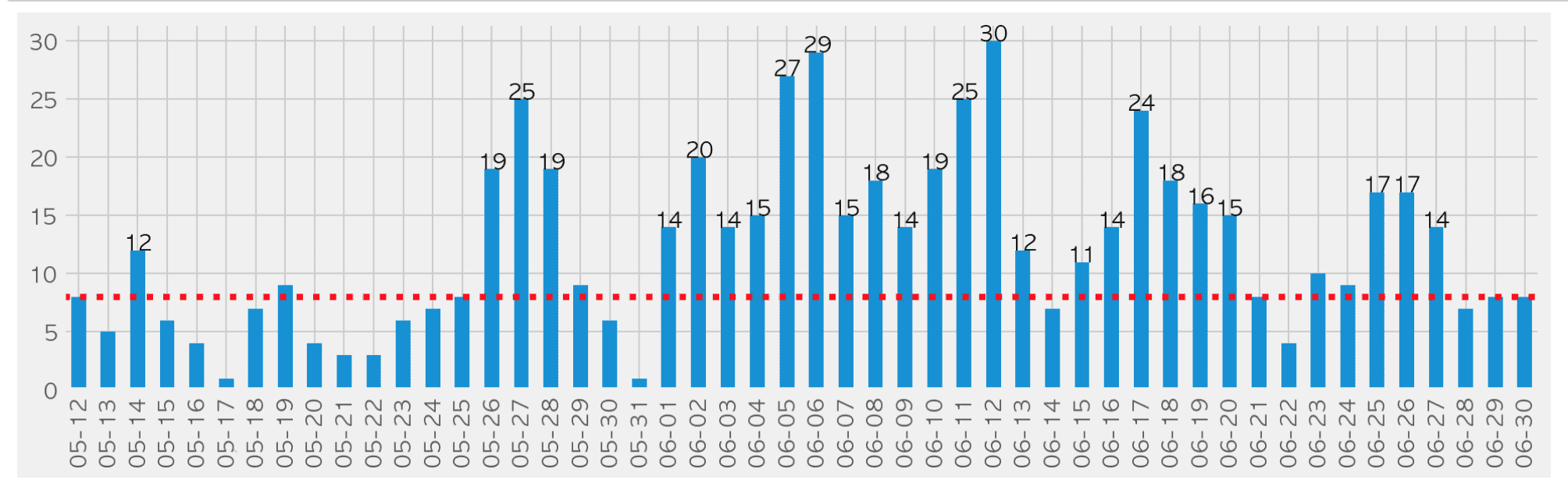
6月までソウル市で公開している確認者現況データ( https://www.seoul.go.kr/coronaV/coronaStatus.do )をパンダスでクロール、前処理、分析視覚化します。
たった2枚の文書で学んだ内容を、現業に似たプロジェクトで分析してみる
ソウル市コロナ19発生現況サイトをクロールから前処理、分析、可視化までパンダスを活用して分析してみます。
ニュース記事や日常を通じてよく遭遇するデータを直接分析してみます。
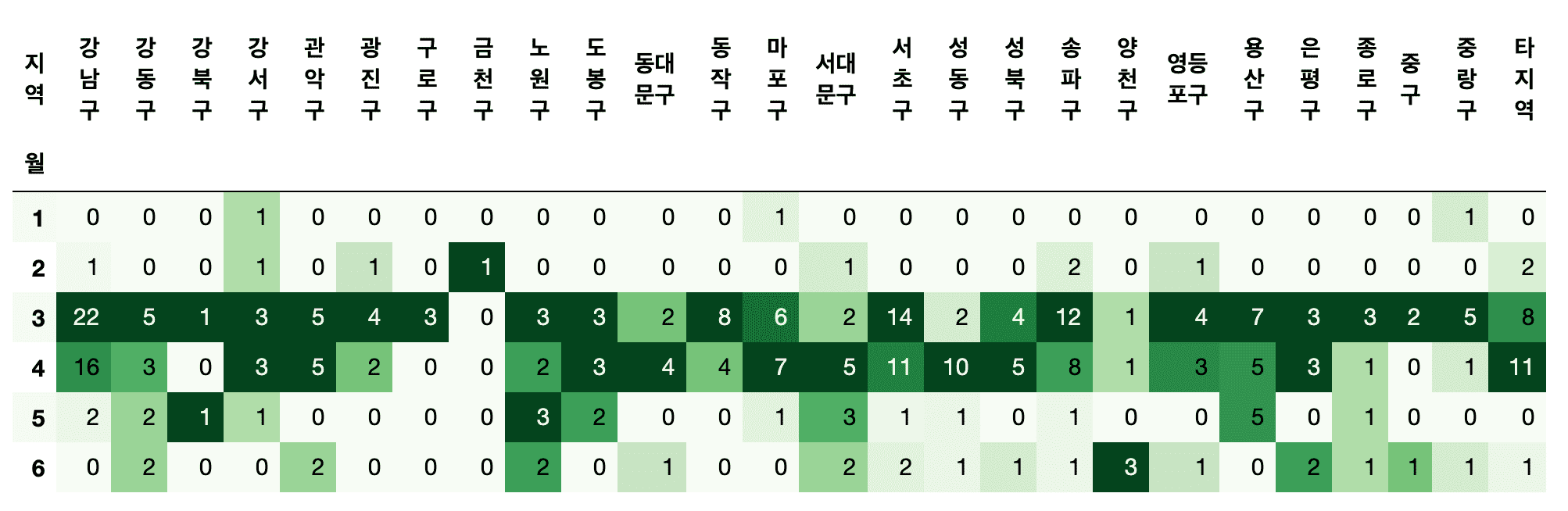
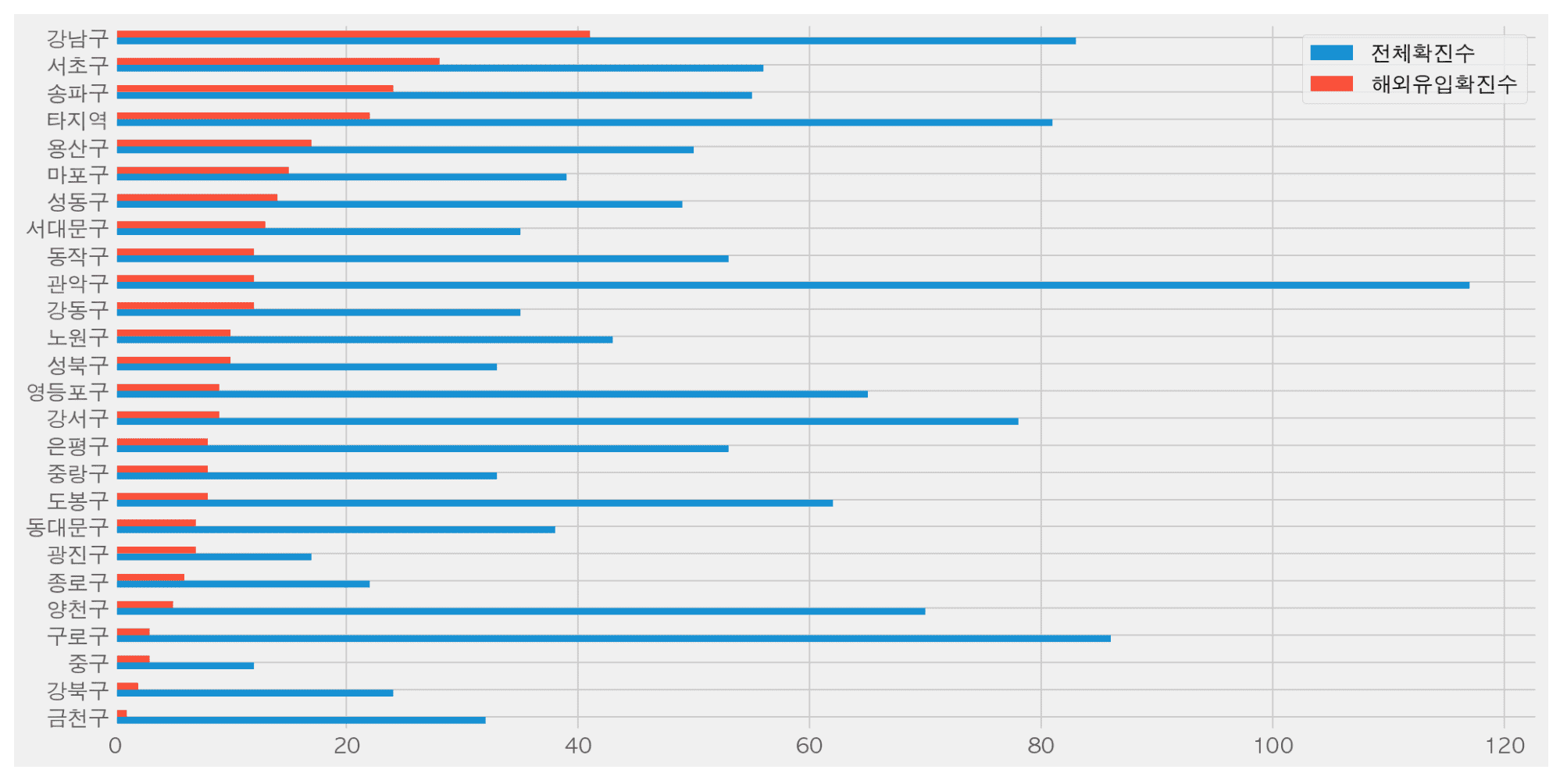
- 確信者が一番出てきた球はどこでしょうか?
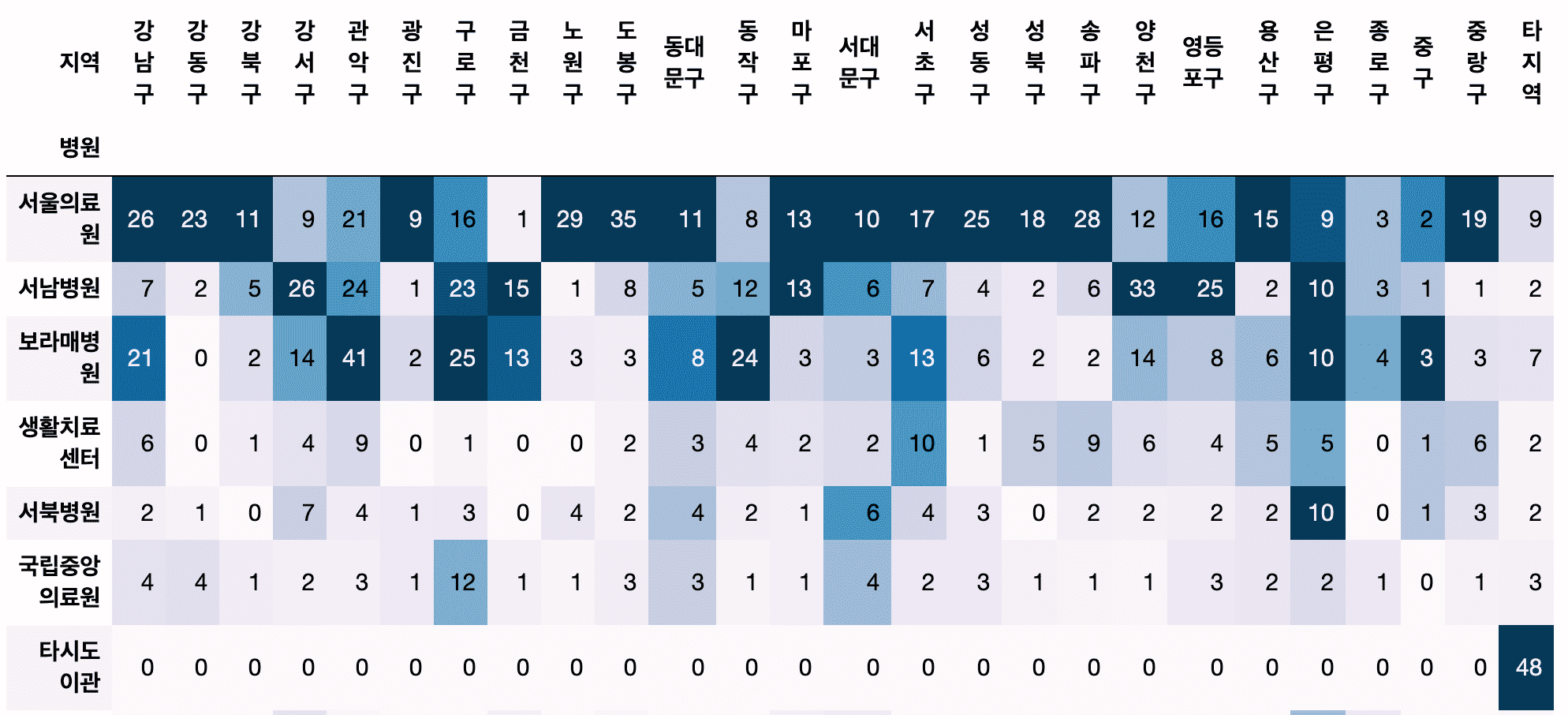
- どの病院で確信者を最も治療したのでしょうか?
- 区別的に多く移送される病院はありますか?
- 海外流入確定者が最も多く出てきた区はどこでしょうか?
- 複数の国をヨーロッパ、南米などでテキスト前処理をするためにはどうすればいいですか?
- 海外流入確定は月別にどの程度差が出るのでしょうか?
パンダスによるデータの前処理方法を理解し、実践してみましょう。
- テキストの日付から年、月、日、曜日、週はどうやって入手できますか?
- 確定者の現状データで累積確定数はどのように求められますか?
- groupby、crosstab、pivot、pivot_tableの違いはどのようになり、どの機能を使用するのに適していますか?
データフレームとシリーズのデータ構造を理解し、分析に適した形に加工してみます。
- Pandas の plot でグラフを描画するためのデータフレームの形はどのように作るべきでしょうか。
- グラフ内のカテゴリー値によって異なる色で値を表現したい場合は、データフレームをどのように変更する必要がありますか?
- シリーズをデータフレームに置き換えるにはどのような方法がありますか?
コースで直接確認してください!
過去1年間、多くの質問と良い受講評を残してくれたおかげで講義を更新することができました。
今後も着実に講座を改善・更新する予定です。
良い受講評を残していただければ、着実なコンテンツ改善に大きな力になります。
コロナ19から抜け出し、また日常に戻ることを願っています!
ありがとうございます。
こんにちは。
📊公共データでPythonデータ分析を始める講義が全面リニューアルされました。
チャプター1~4に続き、「チャプター5都市公園標準データ分析」では、データ前処理に集中して講座を改編しました。
✍🏻コードと映像をすべて新しく作成しました。
📈[章5] 従来55分 => 217分でデータ前処理に関するコンテンツが大幅に追加されました。
#都市公園の標準データは、欠測値、異常値、エラー値、日付など、さまざまなデータ前処理を必要とするデータであり、前処理を実データを通じて身につけてみたい方に適していると思います。
#さまざまなライブラリを使用した技術統計分析を簡単かつ強力にするためのPandas Profilingでレポートを生成する方法が追加されました。
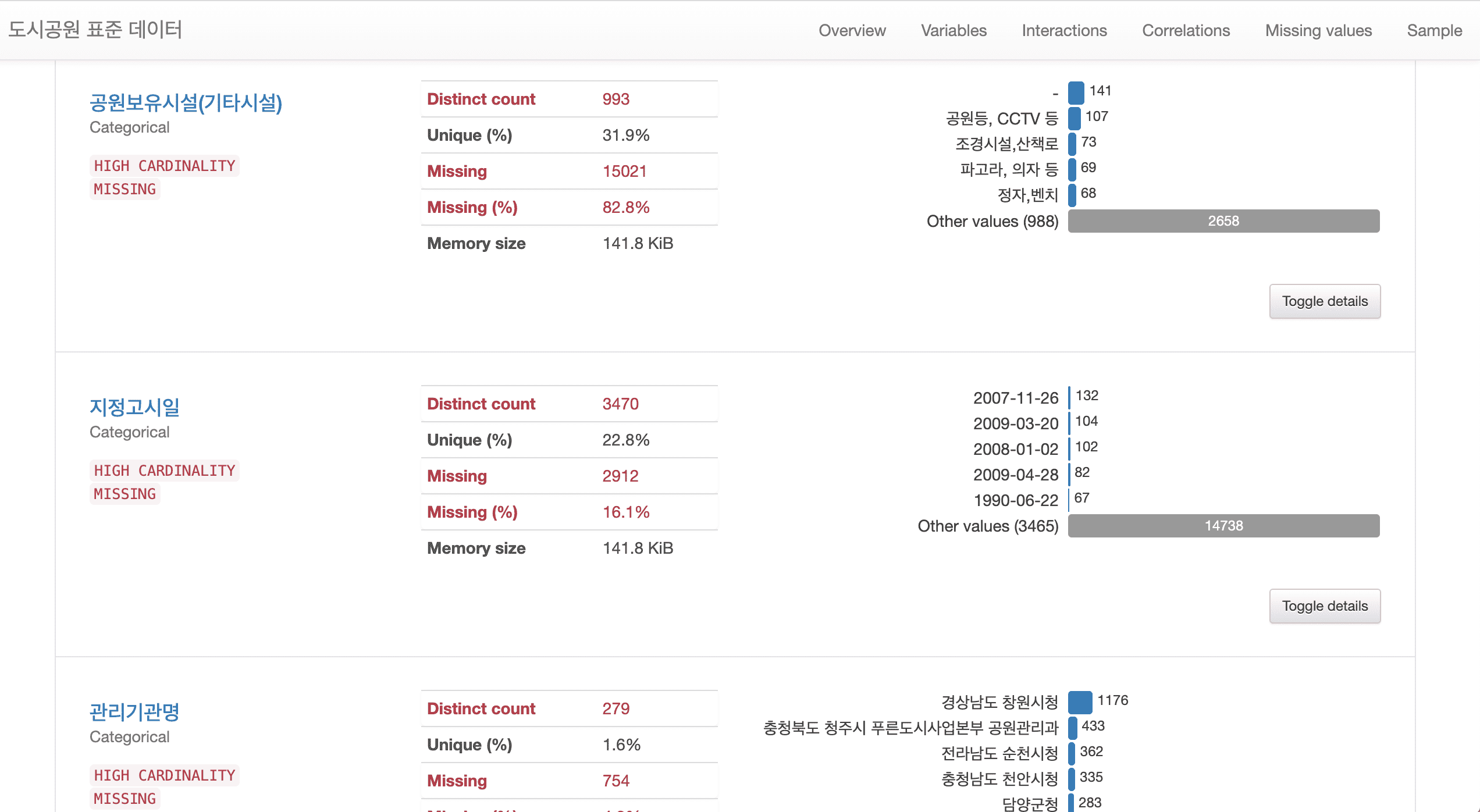
#正規表現によるテキストデータの前処理方法が追加されました。また、テキストデータをさまざまな方法で視覚化します。

#個人情報保護などに必要な情報マスキング技術が追加されました。
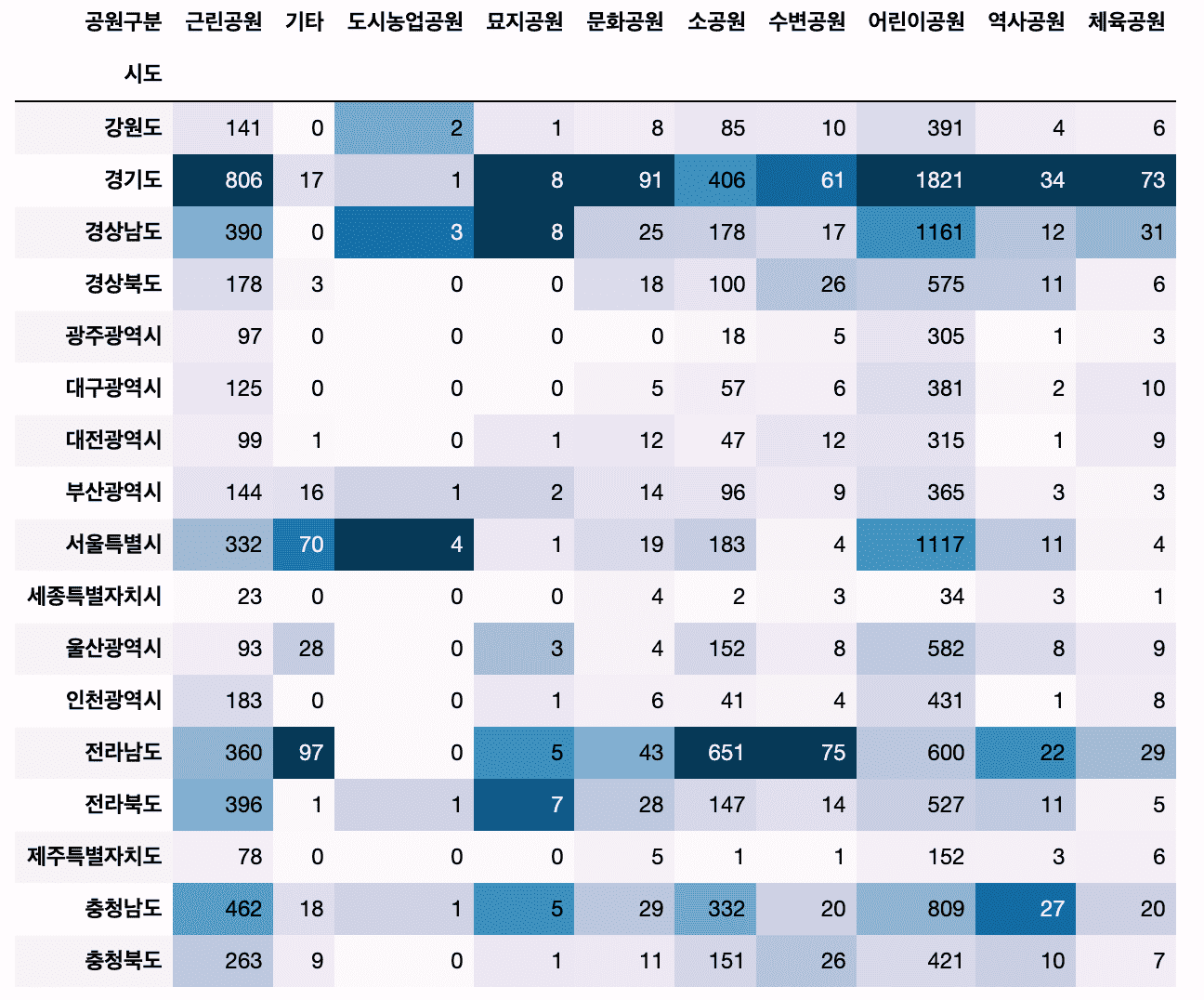
既存の都市公園の分布を分析してみる講義で、前処理業務でよく遭遇するさまざまな技法についての内容を大幅に補完しました。
特に正規表現によるテキストの前処理と分析に関する内容も一緒に学習できるように新規に追加されました。

#crosstabを介したカテゴリカル対カテゴリカルデータクロステーブルの作成方法が追加されました。
また、パンダスのスタイル機能により、視覚化せずにデータフレームに色を表現してみます。
#ビジュアライゼーション技術についてもう少しさまざまなアプリケーションを試してください。
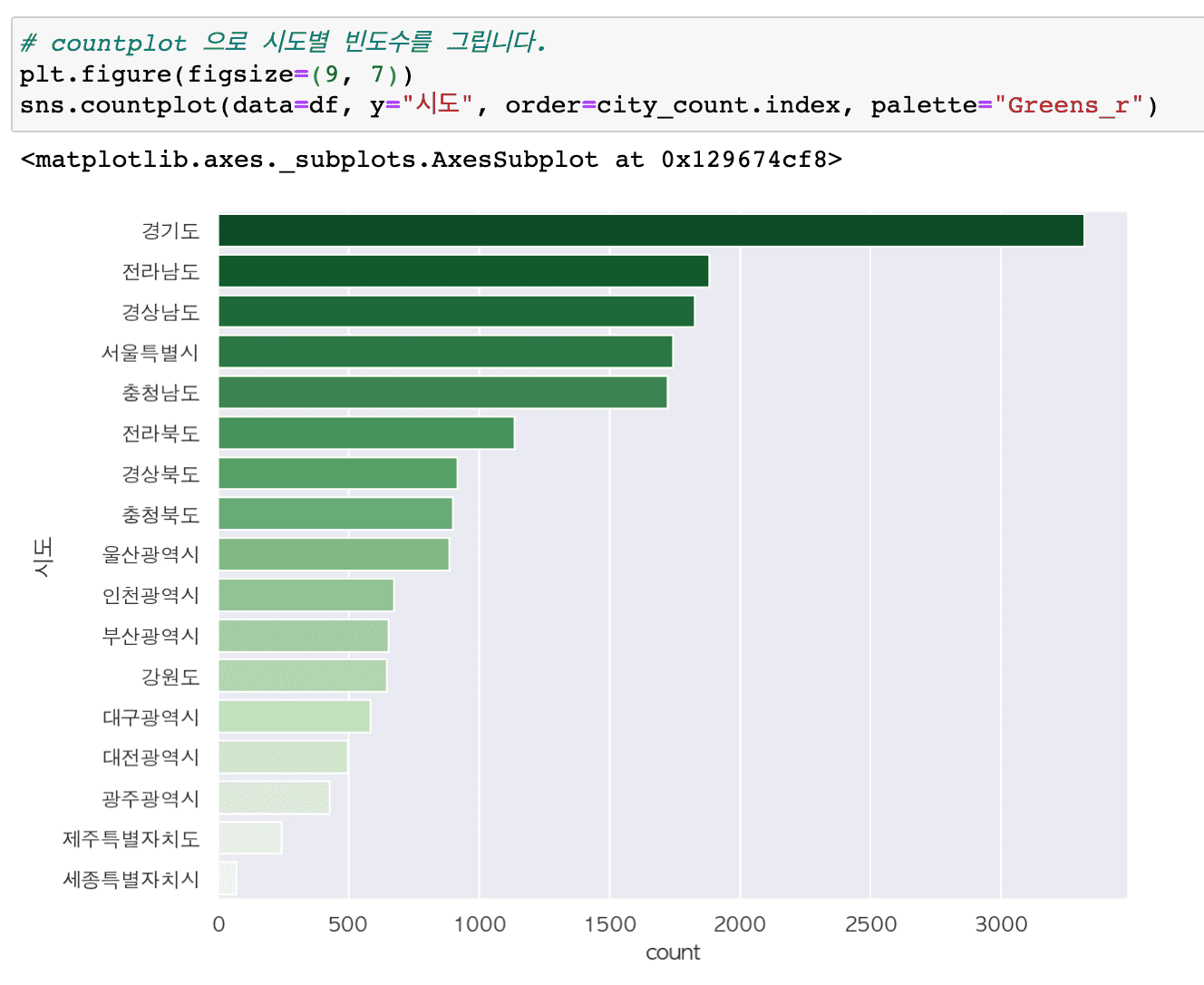
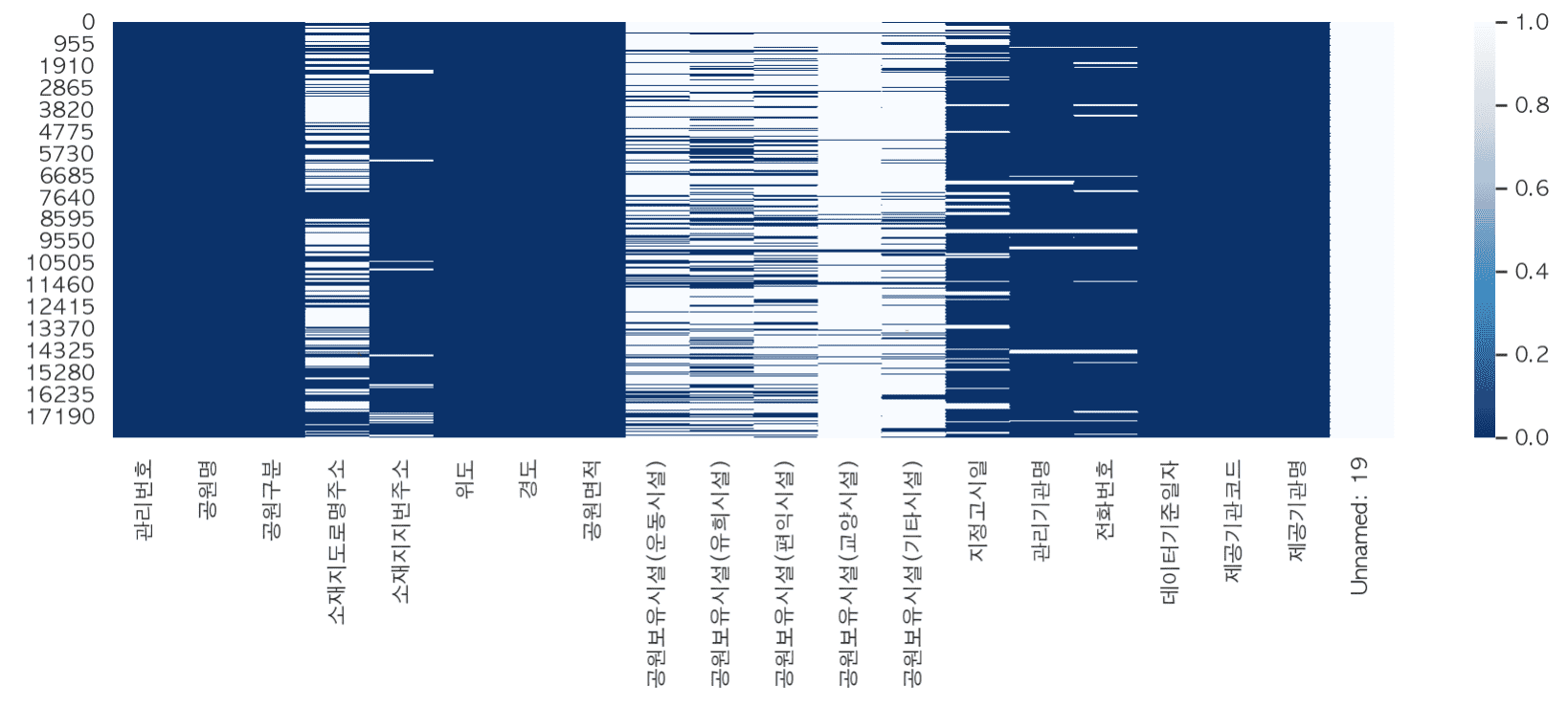
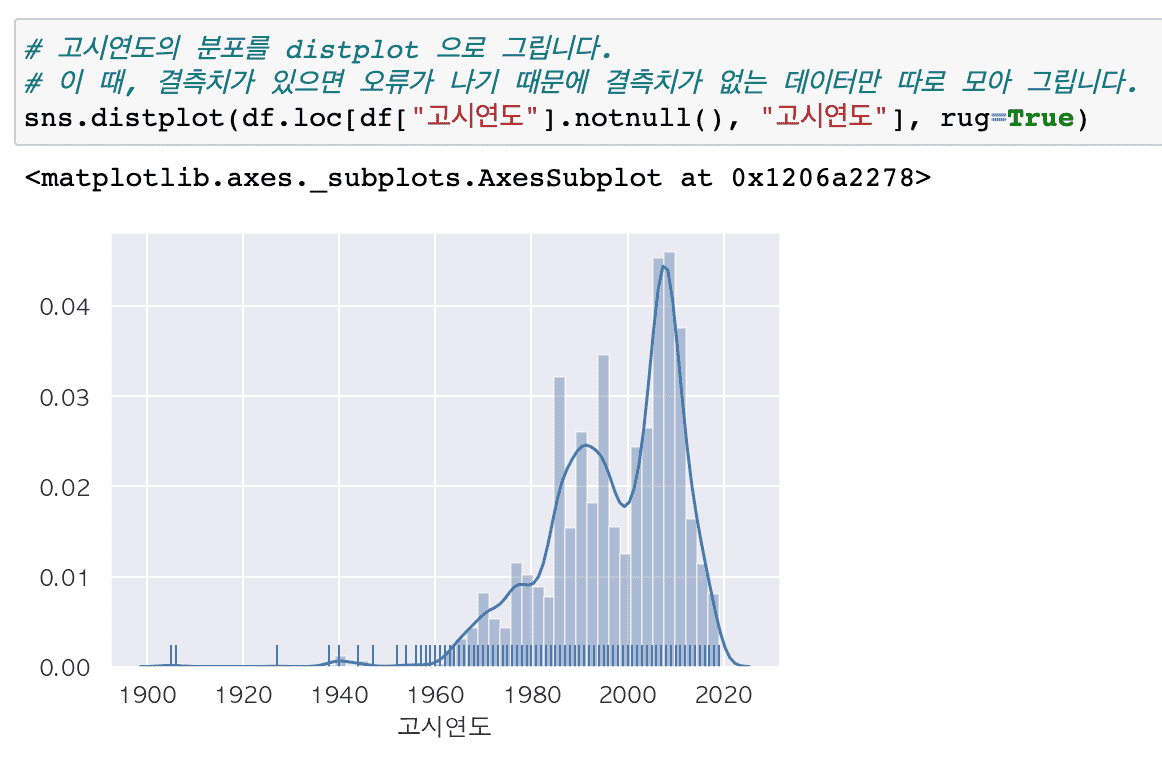
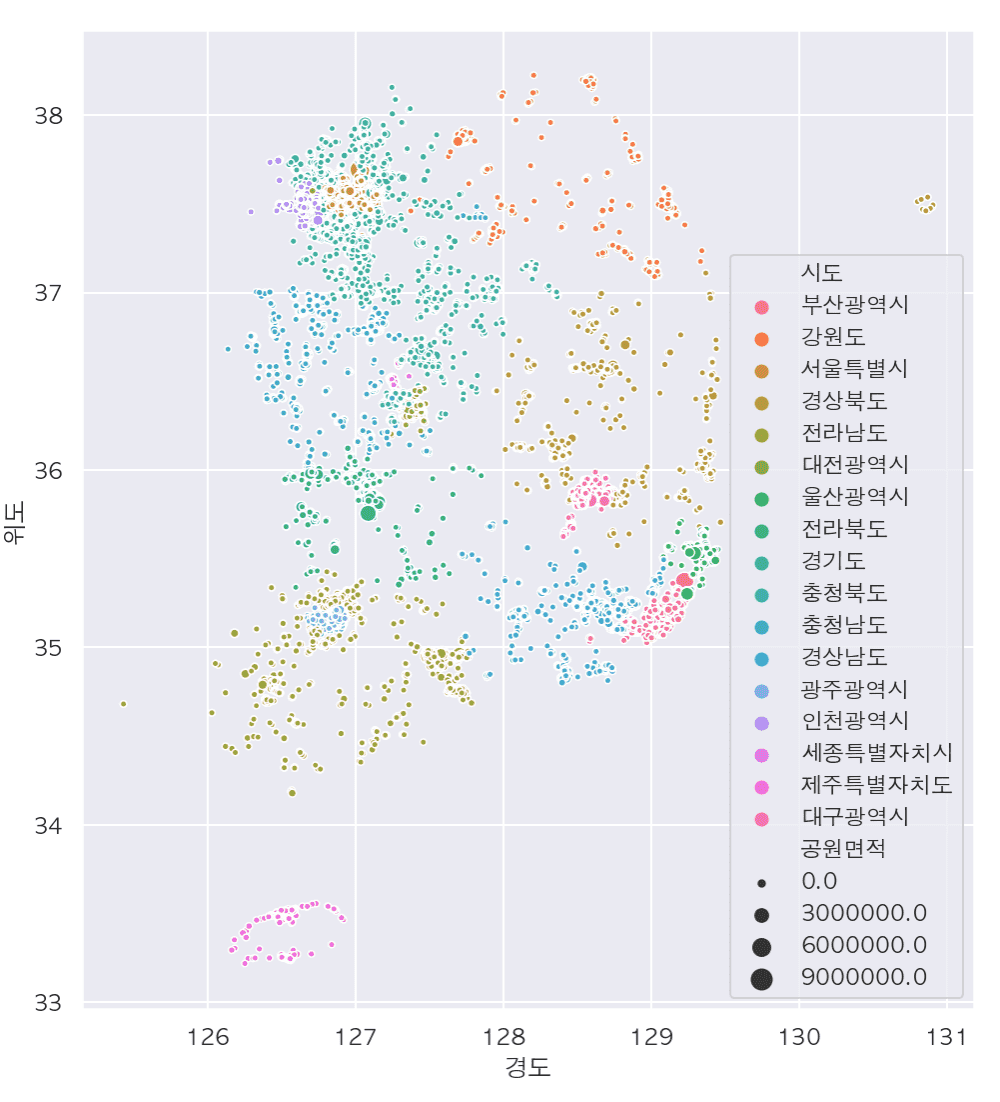
主なアップデート内容のクリーンアップ
#Pandas Profiling
- コード一行でデータ全体のさまざまな技術統計レポートを生成する
#実務に必要な各種データの前処理
- 派生変数の作成
- 欠測値を置き換える
- 異常値、エラー値の検索と対処
- データ型を変更する
#正規表現でテキストデータを扱う
- 必要なデータのみをインポートする
- 他の形態のテキストからキーワードのみを抽出して頻度数世紀
- ワードクラウドを描く
- コードを再利用するためのテキストデータ前処理関数の作成
- 情報をマスキングする:個人情報や電話番号、Eメール、自動車登録番号のパターンを探してマスキングする
#数値型対カテゴリ型変数
- データ型で数値型、カテゴリ型変数を探す
- pivot_table vs crosstabを使う
#私の周りの公園を探して地図に表現する
- データの前処理とfoliumによる視覚化
良い受講評を残していただければ講義を改編して補完するのに大きな力になります!
ありがとうございます。

商店街の情報分析がはるかに詳細になりました。
チャプター1リニューアルに続き、チャプター2~4までリニューアルになりました。全ての映像とソースコードを新たに作成しました。
<リニューアル前>

<リニューアル後>

チャプター2 29分=>167分
チャプター3 37分=>101分
チャプター4 91分=>113分
過去1年間に受け取った貴重な質問とフィードバックで内容を補完し、説明をはるかに詳細に追加しました。
また、練習ができるファイルと結果ファイルを一緒に提供し、Google Colaboratoryですぐに練習ができるリンクも提供します。
<チャプター2商店街(商圏)情報で技術統計を身につける>
missingnoを介してより多様な欠測値を可視化します。
また、欠測値を削除したときにメモリ使用量が異なることを見て、メモリ使用量を減らすことができる方法について説明します。
区別レストラン分析と大知洞と木洞に入試学院が多いか仮説を立てて分析をしてみる内容が追加されました。
そして技術統計内容を大幅に補完しました。
describeを通じて数値型、カテゴリー型データをまとめてみると、それぞれの値に対する意味と個々の値を別々に計算するプロセスが追加されました。
相関係数を求めて回帰線を描いて相関分析をする内容も追加されました。
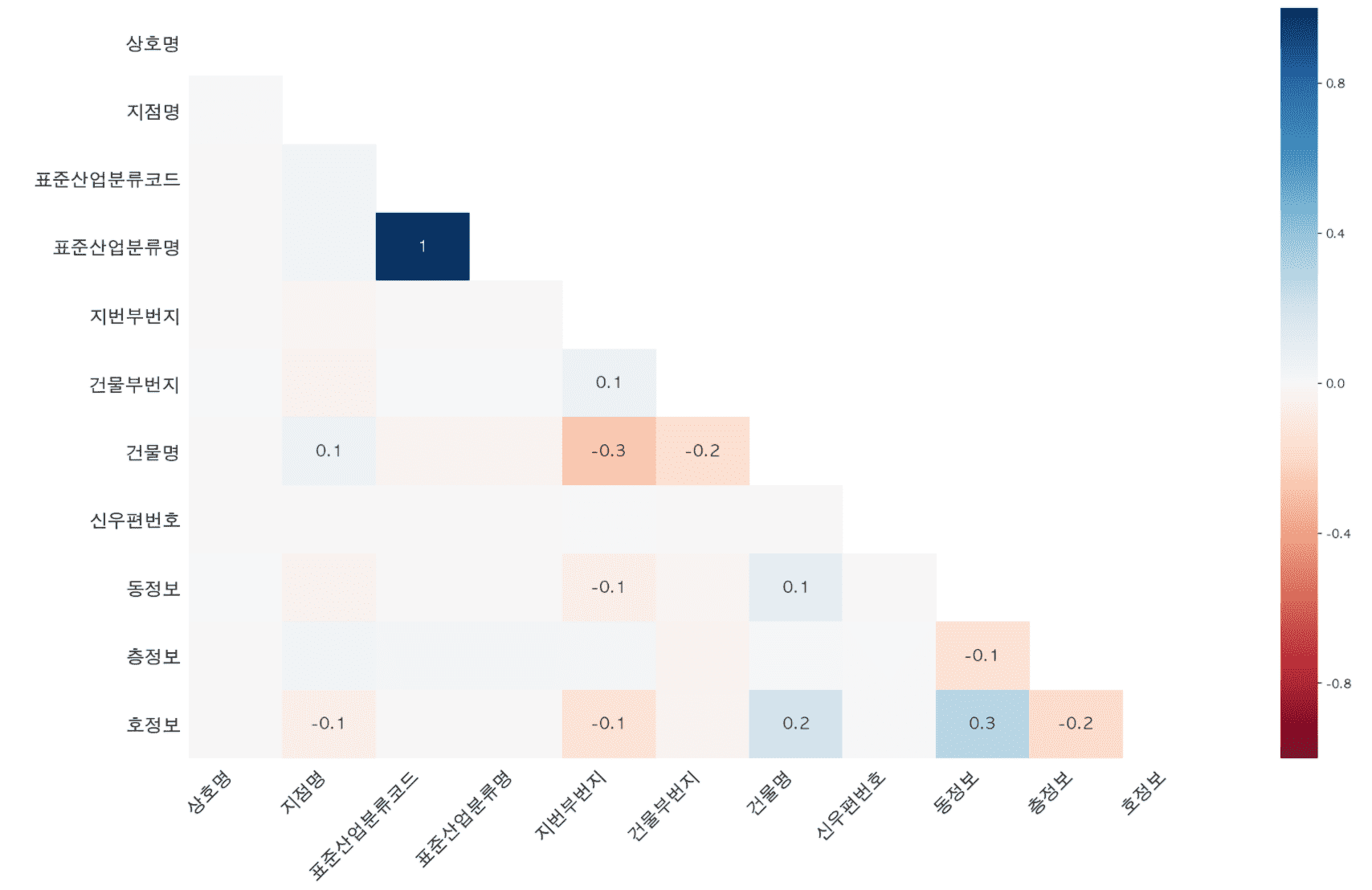
<チャプター3フランチャイズ入店分析>
さまざまな変数を視覚化し、jointplotを介して2つの数値変数を視覚化する方法をより詳しく説明します。
FoliumのCircleMarkerの他に、 MarkerCluster、Heatmapで位置別店舗の密集度を表現します。
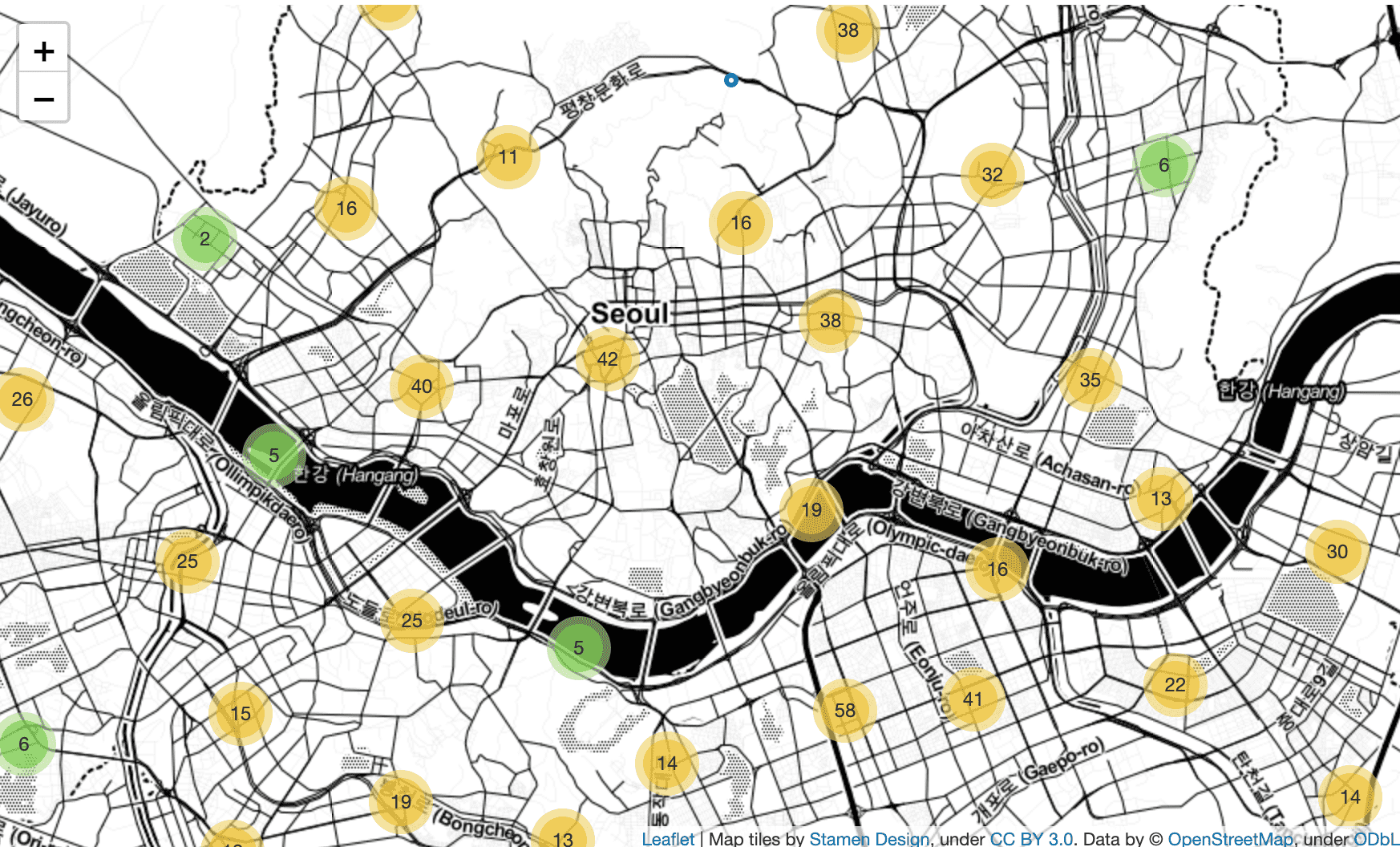
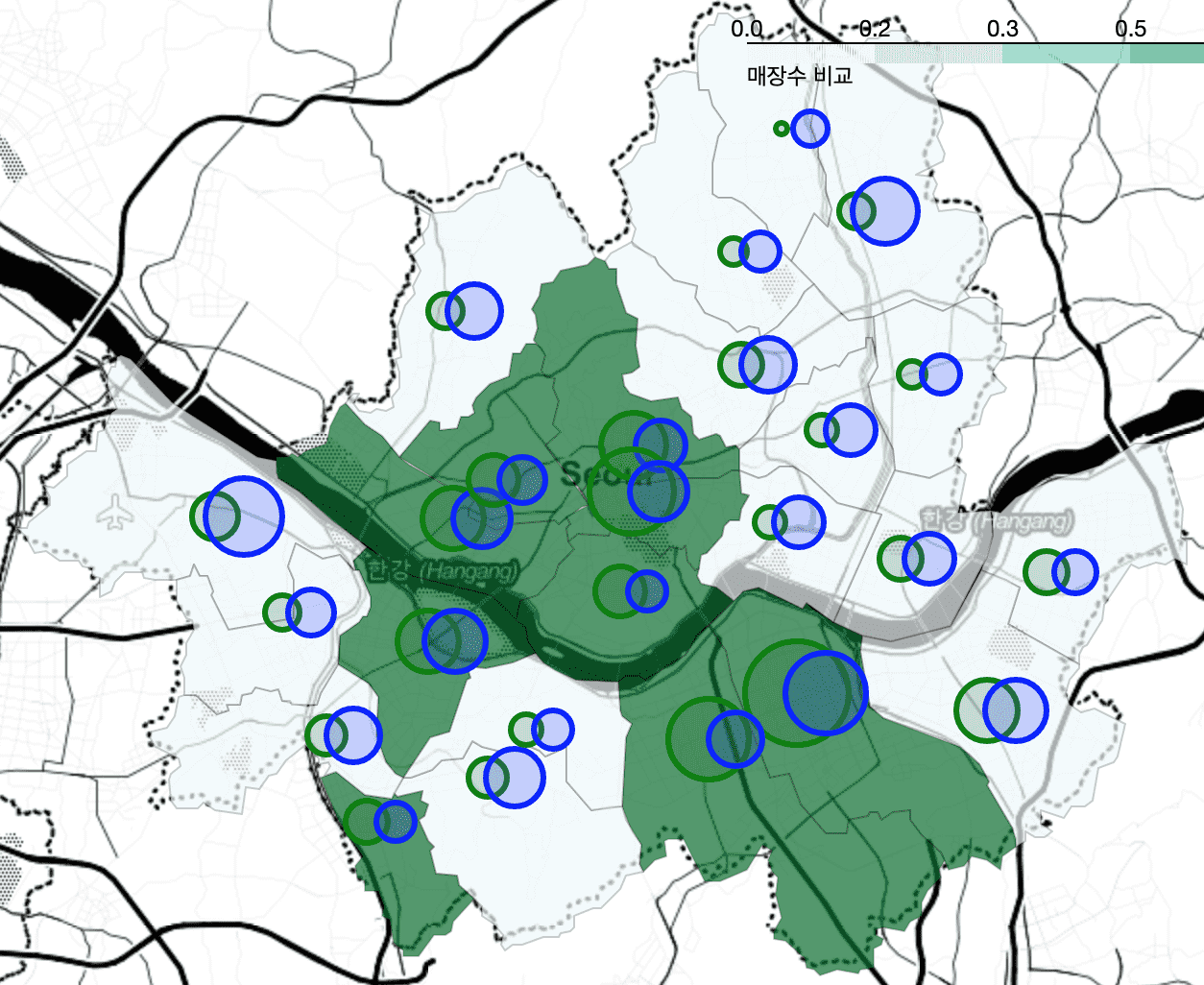
<チャプター4スターバックス、イディーヤ店舗位置比較>
CircleMarkerを区別するために、胃経度の平均を求めるプロセスをforステートメントを使用せずにpivot_tableを介して演算し、 mergeを介して演算結果を合わせるプロセスを扱います。また、説明がはるかに詳細になりました。
<チャプター5>もすぐにリニューアルされる予定です!
今後も質問や受講評を通じてコメントを残していただければ、より良い講義を作るのに役立つと思います!
受講評価とフィードバックを待ちます:)
1年間運営していただいた大切なフィードバックを集めて2020年3月
既存の「チャプター1全国新規民間アパート分譲価格動向」が全く新しくリニューアルされました。
チャプター1基準 既存映像9本(1時間41分)から20本(3時間25分)で説明と可視化がはるかに詳細になりました。
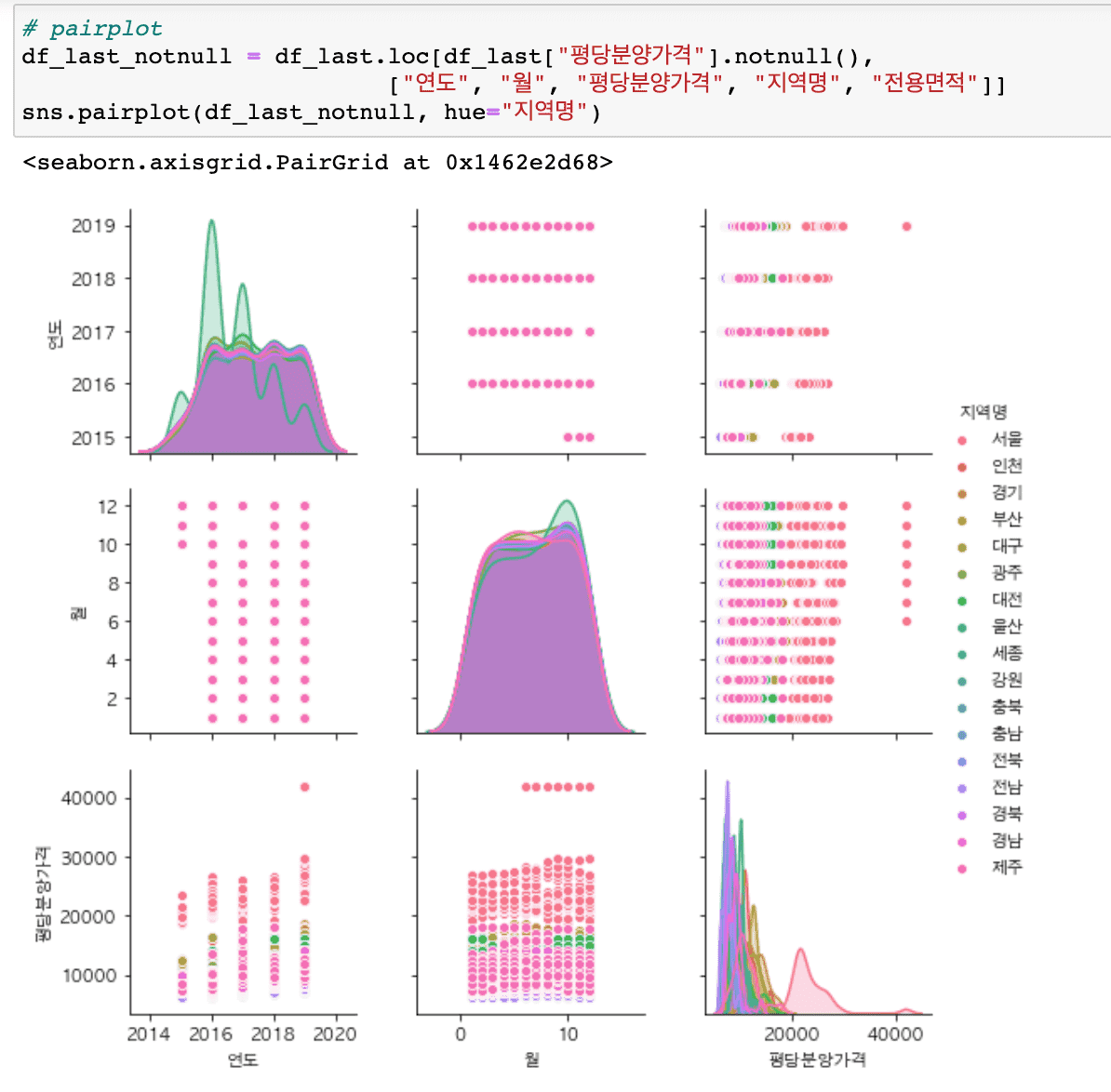
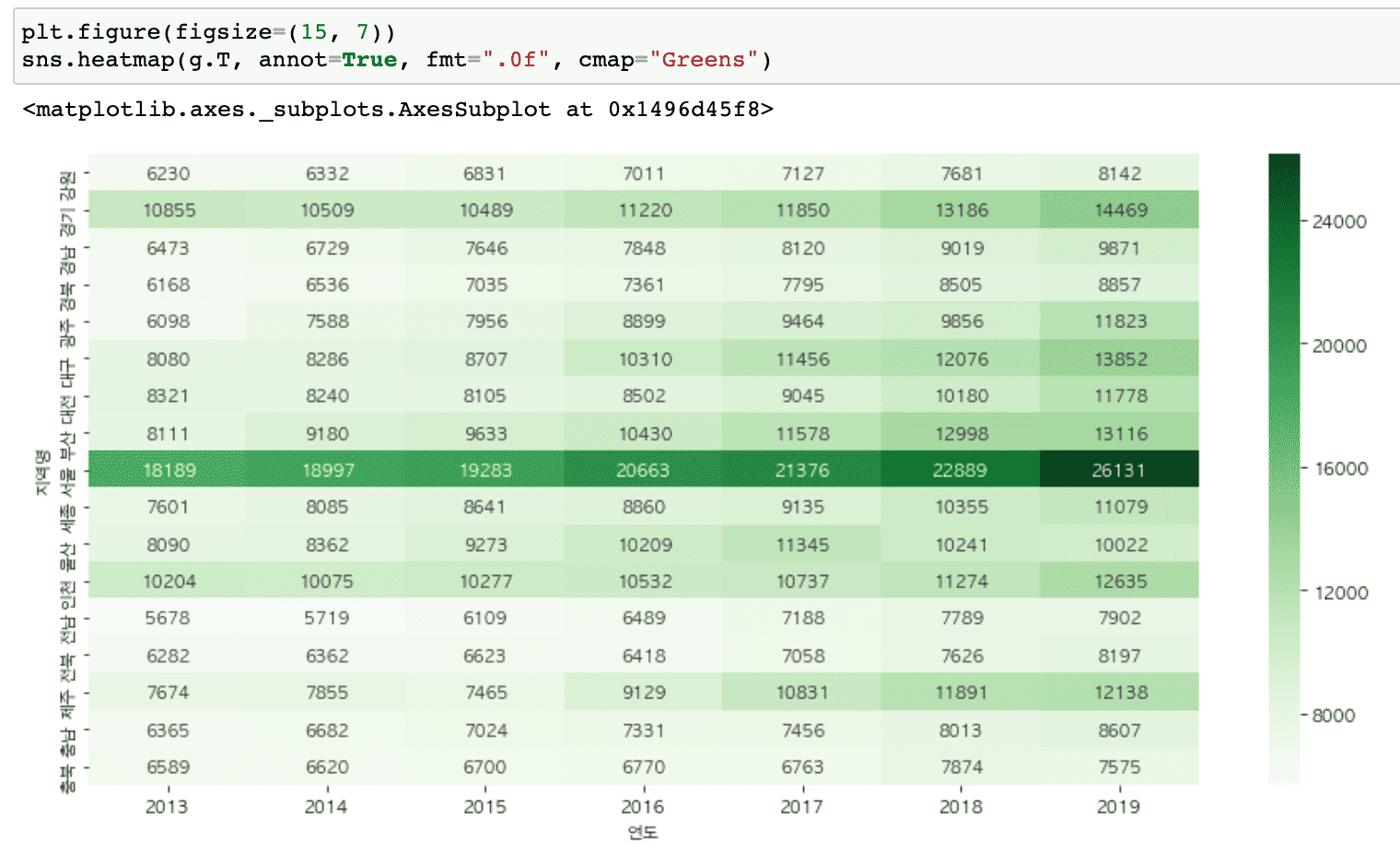
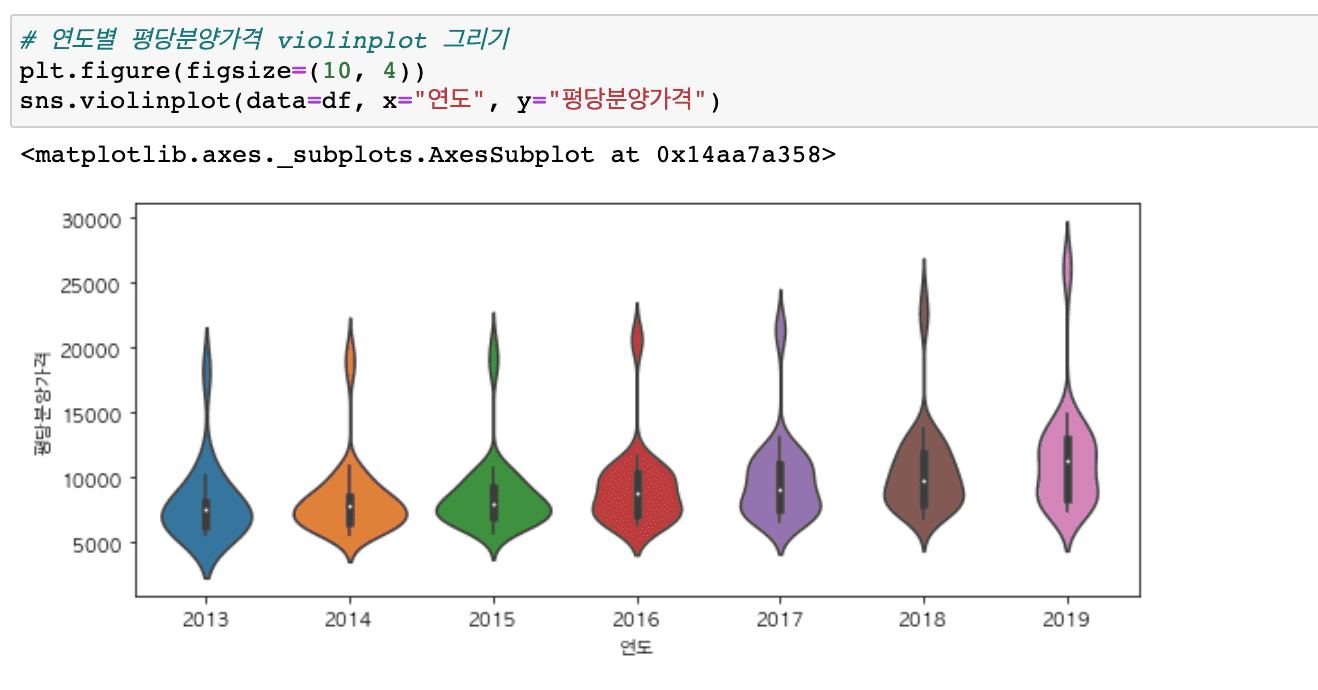
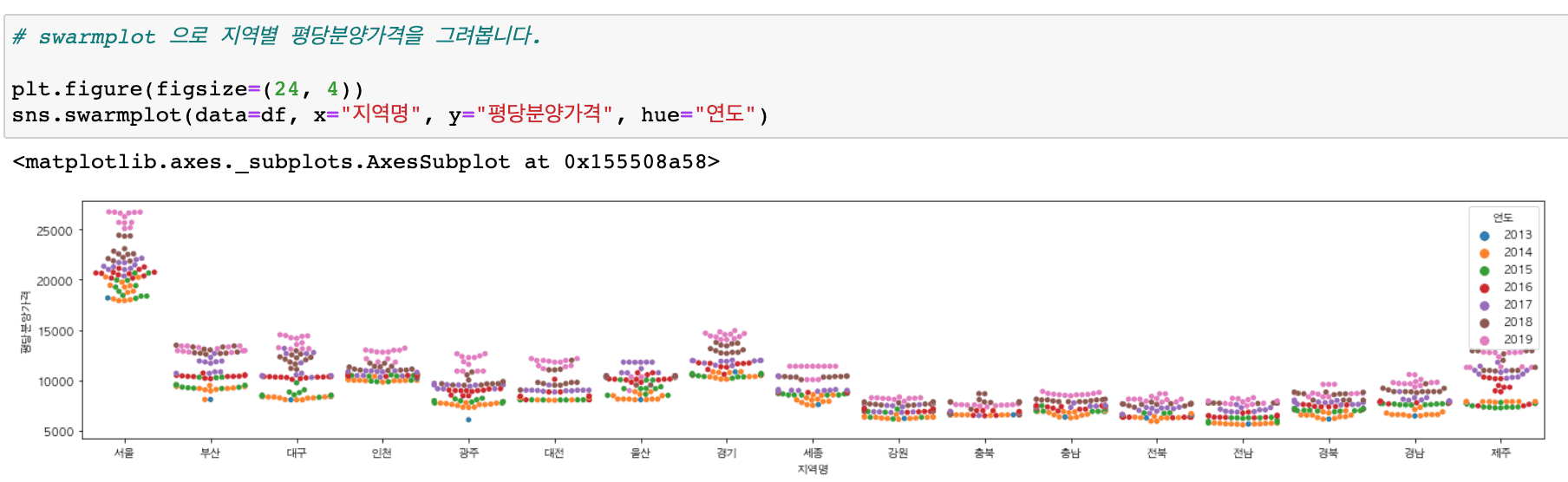
従来よりもはるかに多様なグラフを扱い(ヒートマップ、ヒストグラム、分布図、散布図、回帰グラフなど)、サブプロットを簡単に描くことができる内容が追加されました。
また、実習コードと結果コードを一緒に提供します。
ビデオを見てコードに沿って見ることができるように、簡単なガイドが提示された練習ファイル( 01-apt-price-input.ipynb )と結果が表示されている( 01-apt-price-output.ipynb)ファイルを活用してください。
コードの場所とgoogle colaboratoryのパスについては、ビデオ紹介欄を参照してください。
2020年3月他チャプターのチュートリアルもリニューアル予定です!
ありがとうございます。