




작업형2 모의문제2 오타 질문
안녕하세요 선생님,
첫번째 질문
작업형2 모의문제2를 수강하고 있습니다.
regressor = RandomForestRegressor()로 정의했다면,
밑에서 fit하는 것도 regressor.fit(X_tr, y_tr)로 정의하는게 맞는지 질문드리려고 합니다.
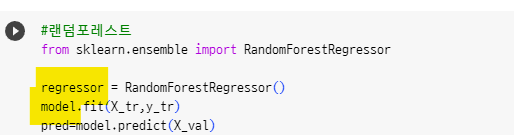
현재 노트에는 model로 정의가 되어 있습니다.
두번째 질문
수강하다가 보면 선생님께서 강의중에(아마 분류문제) 이정도 정확도?가 나왔으면 추가적으로 피처 엔지니어링이 필요 없이 그냥 제출해도 될 것 같다~ 라고 말씀을 하실 때가 있는데, 이 기준이 궁금합니다. 어느 정도여야 점수를 충분히 받는지,
예측에 있어서도 지표로 이런 판단이 가능한지 궁금합니다.
3.세 번째 질문
작업형2 모의문제 3을 듣고 있습니다.
xgboost 하이퍼파라미터 에 대해서 설명을 듣고 있는데, xgbclassifier의 max_depth의 디폴트는 3이라고 max_depth=3을 설정했을 때와 설정하지 않았을 때 값이 같음을 비교해주셨습니다.
그런데 제가 작성했을 때는 max_depth=3을 넣고, 안넣고 했을 떄 값이 다르게 나오는데, 혹시 왜 그런지 아실까요..?
(검색했을 때도 xgboost 디폴트 max_depth=3이라고 나와서 말씀해주신게 맞을 것 같은데..)
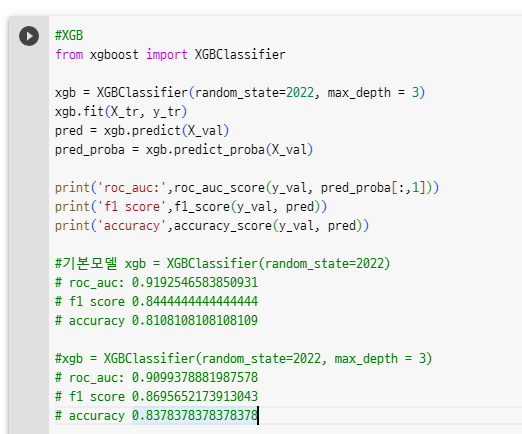
감사합니다.
답변 2
0
네 맞아요 model은 단순한 변수입니다 regressor로 변경라는 것이 맞아요
이 부분은 주최측에서 평가지표 기준을 제공하지 않아 전처리를 최소화한 첫 제출(베이스라인)을 기준으로 이보다 검증데이터 기준으로 점수를 좋게해서 제출하는 것으로 정리 하겠습니다😆
개인적으론 이진분류 기준 0.8 부근이면 괜찮은 모델이러 생각합니다만 성능이 너무 낮게 나오는 데이터도 있어 이 말은 무시해주세요!!
결론 본인이 만든 베이스라인보 조금 더 좋은 점수를 제출하는 것으로!!
1
답변 감사합니다! 세번째 질문에 대한 답을 안달아 주셔서 다시 답글 남깁니다!
감사합니다.
3.세 번째 질문
작업형2 모의문제 3을 듣고 있습니다.
xgboost 하이퍼파라미터 에 대해서 설명을 듣고 있는데, xgbclassifier의 max_depth의 디폴트는 3이라고 max_depth=3을 설정했을 때와 설정하지 않았을 때 값이 같음을 비교해주셨습니다.
그런데 제가 작성했을 때는 max_depth=3을 넣고, 안넣고 했을 떄 값이 다르게 나오는데, 혹시 왜 그런지 아실까요..?
(검색했을 때도 xgboost 디폴트 max_depth=3이라고 나와서 말씀해주신게 맞을 것 같은데..)
출력값 질문
0
13
1
수업노트가 어디에 있나요?
0
21
1
실기시험 제출관련
0
154
2
6.20 작업형 2 과적합
0
158
3
코딩팡 장업형2 베이스 라인 인코딩 종류 질문
0
50
2
로지스틱회귀, 회귀
0
48
2
회귀 문제를 풀때 질문입니다.
0
56
1
불균형 처리 후 성능이 더 낮아졌다면,
0
62
2
실기 체험 제2유형 에러 문의
0
61
1
LIGHTGBM 으로 하면 pred값이 소수점 6자리까지 나오는게 맞나요
0
50
2
3번문제 등분산 가정
0
48
2
작업형3 target 형 변환 질문
0
35
2
[작업형1] 연습문제 섹션1 ~ 10 의 section4
0
36
3
원핫인코딩과 레이블 인코딩에서 concat
0
59
2
제2유형 질문입니다.
0
46
2
C()
0
44
2
작업형 2에서 strafity 적용 유무
0
52
2
수강 기간 연장 가능 여부 문의드립니다.
0
61
1
ols
0
43
2
2유형 작성관련 질문(일반 심화)
0
39
2
2유형 작성관련 질문
0
41
2
2유형 object컬럼 개수 다르면
0
48
2
코딩팡질문이요ㅠㅠ
0
45
2
관찰값과 기대값의 개념이 헷갈립니다.
0
25
2