




LDA 그래프 좌우반전 질문합니다.
안녕하세요.
LDA 파트를 공부하는 중에
철민님께서 올려주신 소스코드를 동일하게 실행했는데

이런 결과가 나와야 하는데
같은 코드를 제가 돌렸을 때는

이런 결과가 나옵니다.
분류가 잘 되었음을 시각적으로 보는데에 있어서는 큰 문제가 없지만 어째서 이렇게 거꾸로? 보이게 되는지 궁금합니다.
답변 10
1
버전이 업그레이드 되면서 정확하게는 모르겠지만.. 뭔가가 바뀌었나봐요..
코드에서
for i, marker in enumerate(markers):
x_axis_data = irisDF_lda[irisDF_lda['target']==i]['lda_component_1']*-1
y_axis_data = irisDF_lda[irisDF_lda['target']==i]['lda_component_2']
x축 값에 -1을 곱하니깐 강의처럼 그림이 나오긴 하네요..!
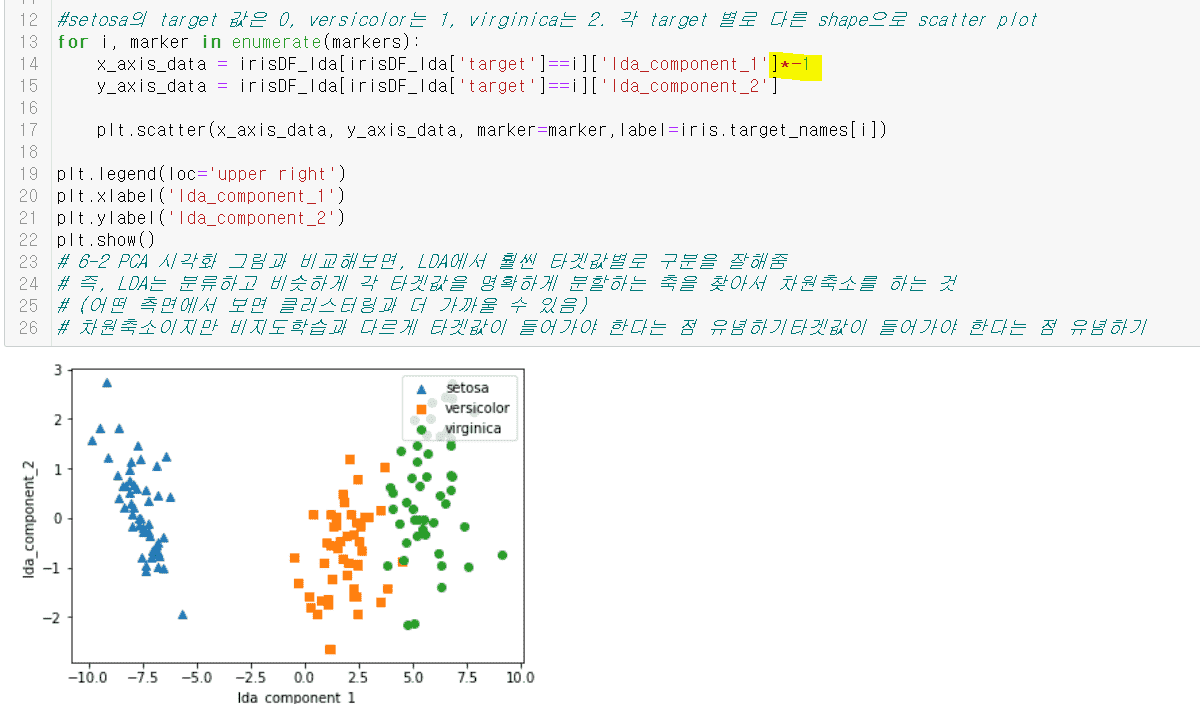
0
https://ratsgo.github.io/machine%20learning/2017/03/21/LDA/
이 글의 'LDA에 대한 첫번째 접근' 부분에 있습니다.
0
LDA계산 과정의 자료 중 2번째에 S_w^T * S_B 에 대한 eigenvector 분해를 통해서 진행한다고 하셨는데, 이에 대한 증명과정을 살펴보니, 증명결과로 S_w^-1 * S_B 에 대한 것으로 확인이 되어 있는 글이 있습니다.
이는 혹시 동일 목적의 다른 방법을 통해 구하는 과정일 수 있거나 한 것인지요?
대략의 생각으로는 두 분산의 행렬이 각각 최대와 최소가 되기 위한 값을 구하는 과정에 '하나를 Transpose해서 곱하는 과정'이 있는 것이 이해가 되지 않아서 찾아보다가 생긴 질문입니다.
0
확인해 보니 사이킷런 0.22.2 이상에서 부터 실습 예제 코드와 대칭으로 나오는 군요.
실습시 사용한 사이킷런이 0.22.1 인데 버전업이 되면서 결과가 달라지는 군요.
해당 부분은 제가 좀더 확인후에 다시 공지드리겠습니다.
감사합니다.
0
복붙에 용이하시라고 아래에 코드 덧붙입니다.
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.preprocessing import StandardScaler
from sklearn.datasets import load_iris
iris = load_iris()
iris_scaled = StandardScaler().fit_transform(iris.data)
lda = LinearDiscriminantAnalysis(n_components=2)
# fit()호출 시 target값 입력
lda.fit(iris_scaled, iris.target)
iris_lda = lda.transform(iris_scaled)
print(iris_lda.shape)
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
lda_columns=['lda_component_1','lda_component_2']
irisDF_lda = pd.DataFrame(iris_lda,columns=lda_columns)
irisDF_lda['target']=iris.target
#setosa는 세모, versicolor는 네모, virginica는 동그라미로 표현
markers=['^', 's', 'o']
#setosa의 target 값은 0, versicolor는 1, virginica는 2. 각 target 별로 다른 shape으로 scatter plot
for i, marker in enumerate(markers):
x_axis_data = irisDF_lda[irisDF_lda['target']==i]['lda_component_1']
y_axis_data = irisDF_lda[irisDF_lda['target']==i]['lda_component_2']
plt.scatter(x_axis_data, y_axis_data, marker=marker,label=iris.target_names[i])
plt.legend(loc='upper right')
plt.xlabel('lda_component_1')
plt.ylabel('lda_component_2')
plt.show()
0
깃허브에 올려주신 코드 그대로 실행했습니다.
한 화면에 담기 위해 화면 사이즈를 줄여서 캡쳐하느라 글자가 작아졌습니다. 양해바랍니다,,

버전은 아래와 같이 0.23.2 입니다.

참고로 PCA 공부할때는 문제 없이 동일하게 나왔습니다.
0
안녕하십니까,
저도 이유가 궁금하군요. 실습 코드를 변경하지 않으셨다고 했는데, 일단 수행하신 모든 코드를 여기에 올려 주시겠습니까?
제가 수행해 보고 말씀드리겠습니다. 그리고 사이킷런 버전도 부탁드립니다.
감사합니다.
강의 문의드립니다.
0
53
2
모델 서빙과 관련된 강좌가 출시되는지 질문드립니다.
0
67
2
안녕하세요 열심히 수강중인 학생입니다
0
102
2
정수 인덱싱
0
97
2
넘파이 오류
0
132
2
11강 numpy의 axis 축 질문 드립니다.
0
125
2
Kaggle 에서 Santander customer satisfaction data 를 다운로드 되지가 않습니다.
0
108
2
Feature importances 를 보여주는 barplot 이 그래프로 안보여져요.
0
96
2
타이타닉 csv 파일이 주피터 화면에 보이지 않습니다.
0
98
2
타이타닉 csv 파일이 주피터 화면에 보이지 않습니다.
0
87
2
5강 강의 오류가 있어요.
0
103
1
실무에서 LTV 관련 모델 선택 질문입니다!
0
97
2
14강 강의 듣는중에 궁금한게 있어서 질문합니다~
0
97
3
파이썬 다운그레이 후 사이킷런 재설치
0
149
2
좋은 강의 감사합니다.
0
96
2
scoring 함수 음수값
0
94
2
6번 강의에 사이킷런, 파이썬, 아나콘다 각각 버전 일치 안 시키고 진행해도 강의 따라가 지나요?
0
118
2
분류 평가 정확도 예측
0
108
2
안녕하세요. 강의 들으면서 업무에 적용하고 싶은 수강생입니다.
0
119
1
카카오톡 채널 있나요
0
128
1
혹시 강의에서 사용하시는 ppt 받을 수 있는건가요
0
210
2
pca 스케일링 관련하여 질문드립니다.
0
137
2
주피터 대신 구글 코랩
0
193
2
강의에서 사용하는 pdf or ppt자료는 따로 없는 건가요?
0
164
2