




순환신경망 모델에서 fully connected layer 차이
502
작성한 질문수 1
안녕하세요.
RNN은 forward 부분에서 fully connected layer에 nn.linear의 결과를 다시 sigmoid 함수에 넣어주는데 LSTM, GRU 는 그렇지 않은 이유가 무엇인지 궁금합니다.
RNN의 경우
self.fc = nn.Sequential(nn.Linear(hidden_size*sequence_length, 1), nn.Sigmoid())LSTM 및 GRU의 경우
self.fc = nn.Linear(hidden_size*sequence_length, 1)
답변 1
0
안녕하세요.
좋은 질문 감사 드립니다!
주가 예측 같은 regression 문제에는 마지막 레이어에 활성화 함수를 일반적으로 사용하지 않습니다.
하지만 우리 예시에서는 MinMax 스케일을 한 데이터를 사용해서 모든 타겟값이 0이상 1이하의 값이라는 것을 알고 있습니다. 따라서 sigmoid를 사용하여 [0,1]로만 예측값을 나오게 하여 수렴성을 좋게 할 수 있습니다.
문제에 따라 효과가 다를 수 있지만 우리 예시의 경우 sigmoid를 적용하여 수렴 속도 및 학습 성능을 개선할 수 있습니다. 물론 sigmoid를 사용하지 않고 학습률(learning rate)을 조절하여 수렴성을 개선할 수도 있습니다 :)
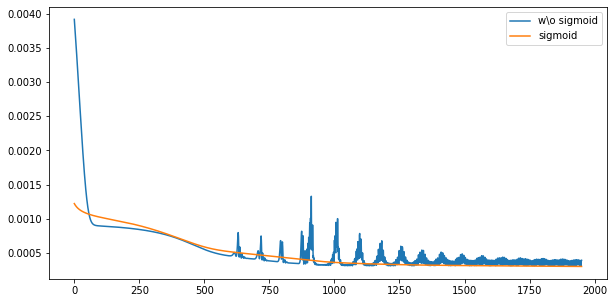
아래는 LSTM에서 sigmoid 유무에 따른 학습 손실함수 그래프입니다! (x축: epochs, y축: 손실함수 값)
수업자료 제공 부탁드립니다.
0
118
2
코드가 어디에 있는지 모르겠습니다.
0
117
2
논문 구현
0
209
2
overfitting이 나는 이유가 궁금합니다.
1
185
2
분류 성능이 잘 안 나오는 이유
0
226
1
AutoEncoder 차원 질문
1
260
2
사전 학습 모델에서의 layer 변경에 대한 질문
1
227
1
7강 폴더 만들
0
268
1
4-3강 cross-validation에서의 best model 선정 기준
0
462
1
regression 문제에 대한 결과 시각화
0
220
1
Loss function 관련하여 질문드립니다.
0
974
1
early stopping 코드 문의
0
333
1
예측 그래프
0
364
1
데이터 불균형
1
368
1
8강 전이 학습 질문
0
409
2
data의 gpu처리 질문
0
248
1
nn.Linear(1024, 10) 관련 질문드립니다.
0
297
1
학습과 평가시 Loss 함수가 다른 이유
0
256
1
전처리 관련해서 질문 있습니다.
0
232
1
데이터 엔지니어의 역량을 기르려면 어떻게 해야할까요?
0
950
2
역전파 내용 중 미분 관련 질문 드립니다
1
285
1
8강 전이학습에서 kernel size 관련 질문 드립니다.
1
969
1
이미지분류-합성곱신경망(CNN) 피쳐맵 질문입니다.
1
594
1
14강 데이터 불균형 RandomRotation
1
488
1