




split() 함수 사용시 결과값이 잘못나오는 이유는 뭘까요?
.split('[') 함수 사용시 결과 값이 틀린 이유는 뭘까요?

답변 2
1
우선 코드를 보여주시려면, 제가 복사해서 테스트해볼 수 있을 정도는 되야 해요. 제가 직접 이미지를 놓고 모든 코드를 이미지를 보면서 직접 쳐봐야 테스트를 해봐야 한다면, 답변을 드리는데에도 시간이 많이 걸리고, 대충 답변을 드리면 그것도 문제가 있을 것 같아요.
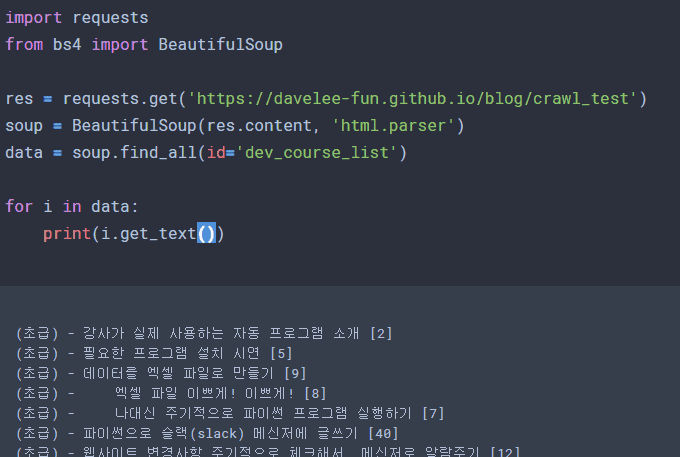
말씀하신 코드는 id 가 dev_course_list 인 데이터를 통째로 가져왔기 때문에, 반복문을 한번밖에 돌지 않고, 데이터도 통째 데이터밖에 없는 상태로 보입니다. enumerate() 함수로 반복문 횟수를 가져올 수 있으니, 다음과 같이 써보시면 이해하실 수 있을 꺼예요.
import requests
from bs4 import BeautifulSoup
res = requests.get('https://davelee-fun.github.io/blog/crawl_test')
soup = BeautifulSoup(res.content, 'html.parser')
data = soup.find_all(id='dev_course_list')
for num, i in enumerate(data):
print (num, i.get_text())
print (num, i.get_text().split('['))
0
캡쳐로 문의하면 그런 문제가 있었군요. 다음부터는 txt로 문의드리겠습니다. (죄송)
통째로 데이터를 가져온 상태라는 것에 대해 대충(?)은 이해 했습니다. ^^
33강 9:51 excercise55.
0
23
1
섹션2 - 32강 연습문제 48번 질문
0
30
0
주피터 노트북 사용법 강의 관련
0
30
1
exercise 20. 데이터 구조(리스트)
0
32
0
65강 소리
0
35
1
섹션 5 CSS selector사용해서 클로링하기2의 커리큘럼 일정 부재?
0
49
2
크롤링, 영상을 따라해도 제미나에게 물어봐도 안되요
0
54
1
정규표현식 및 여러 코드 꼭 외워야 하나요?
0
59
1
리스트 함수형도 정수 데이터 받을 수 있나요?
0
60
1
크롤링 관련 질문
0
75
1
문제 답이 없는 버전은 없나요?
0
89
1
requests, BeautifulSoup 임포트 부분에 대해 문의드립니다.
0
96
1
업데이트 강의
0
119
2
선생님 강의중에서 sqlite3 강의를 제공한 강의가 있나요?
0
146
2
연습용 예제 파일
0
87
1
lxml 관련 오류
0
117
1
SAVE Request 창 띄우는 법
0
106
1
포스트맨 사용법이 바뀌어서 강의를 따라가지 못하겠습니다. 2
0
90
1
포스트맨 사용법이 바뀌어서 강의를 따라가지 못하겠습니다.
0
113
1
예제 2, 4, 6에 대한 풀이 방식 질문.
0
104
1
문제 파일
0
93
1
pdf 파일 내 코드 복붙시 공백
0
315
1
데이터 저장 강좌 문의 건
0
108
1
" " 와 ' '의 차이를 알고 싶습니다
0
265
1