




멀티프로세싱 에러 질문입니다.
6578
작성한 질문수 1
안녕하세요.
실습을 하던 중 아래코드에서 AttributeError가 발생해서 질문 올립니다.
코드 :
from multiprocessing import Pool
import numpy as np
def _apply_df(args):
df, func, kwargs = args
return df.apply(func, **kwargs)
def apply_by_multiprocessing(df, func, **kwargs):
# 키워드 항목 중 workers 파라메터를 꺼냄
workers = kwargs.pop('workers')
# 위에서 가져온 workers 수로 프로세스 풀을 정의
pool = Pool(processes=workers)
# 실행할 함수와 데이터프레임을 워커의 수 만큼 나눠 작업
result = pool.map(_apply_df, [(d, func, kwargs)
for d in np.array_split(df, workers)])
pool.close()
# 작업 결과를 합쳐서 반환
return pd.concat(list(result))
이구요.
에러:
AttributeError: Can't get attribute '_apply_df' on <module '__main__' (built-in)>
위와 같은 에러가 발생하는데 5달 전에 같은 문제를 겪으신 분이 계시더라구요. 해당 답변에 colab에서는 잘 실행이 되는데 제 PC에서는 에러가 생기는데 어떻게 해야 해결될까요?
답변 5
1
안녕하세요.
colab 에서 실행이 잘 되었는데 사용하고 계신 환경에서 실행이 안 된다면 아마도 환경문제 인거 같은데요.
해당 코드는 멀티프로세싱을 하도록 쓰레드를 여러 개 만드는데 환경에 따라 오류가 발생하는거 같아요.
찾아보니 아래와 같은 이슈가 ipython 에 있는데 주피터 노트북은 ipython을 사용하고 있어요.
[Can't use multiprocessing module in IPython · Issue #10894 · ipython/ipython](https://github.com/ipython/ipython/issues/10894)
위에 있는 방법으로 해결을 해보시거나 Colab으로 실습을 해보시는게 좋을거 같아요.
해당 기능은 전처리시 시간이 오래 걸리기 때문에 멀티프로세싱을 통해 전처리 시간을 줄이도록 한 코드인데요.
worker의 수를 4가 아닌 1로 변경해서 해보시고 같은 오류가 발생한다면 Colab을 사용하시는 방법과 github에 있는 이슈로 해결해 보시는 방법이 있을거 같아요.
1
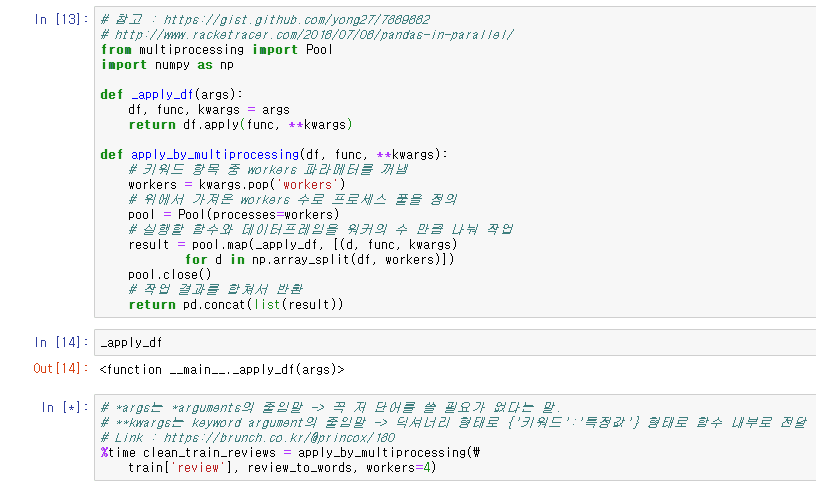
14번 라인에 말씀하신<function __main__._apply_df(args)> 가 출력되는데요.
그 아래 코드를 돌렸을 때 아나콘다 프롬프트에서
![]()
에러가 발생합니다.
1
안녕하세요.
어떤 강의에서의 질문인지를 몰라서 제가 파일 임포트 부분의 오류라 생각했는데 part1에서의 질문이었네요.
해당 함수를 다른 파트에서는 별도의 파일로 분리를 해서 사용하거든요.
혹시 위에 코드의 오류가 아래 코드를 실행했을 때 나는 오류인가요?
%time clean_train_reviews = apply_by_multiprocessing(\
train['review'], review_to_words, workers=4)
만약 그렇다면 새로운 셀을 만들고 다음코드를 그냥 실행해 보세요.
_apply_df
바로 아래 다음과 같은 결과가 나오는지도 확인을 해주세요.
<function __main__._apply_df(args)>
오류 내용을 봤을 때 함수가 제대로 정의되지 않은것 같아요.
아래의 코드가 실행된 상태여야지 _apply_df 를 사용할 수 있습니다.
from multiprocessing import Pool import numpy as np def _apply_df(args): df, func, kwargs = args return df.apply(func, **kwargs) def apply_by_multiprocessing(df, func, **kwargs): # 키워드 항목 중 workers 파라메터를 꺼냄 workers = kwargs.pop('workers') # 위에서 가져온 workers 수로 프로세스 풀을 정의 pool = Pool(processes=workers) # 실행할 함수와 데이터프레임을 워커의 수 만큼 나눠 작업 result = pool.map(_apply_df, [(d, func, kwargs) for d in np.array_split(df, workers)]) pool.close() # 작업 결과를 합쳐서 반환 return pd.concat(list(result))
1
안녕하세요.
해당 함수가 있는 파일이 제대로 로드되지 않은거 같아요.
import 를 통해 KaggleWord2VecUtility.py 파일이 로드 되어야 해당 함수를 사용하실 수 있어요.
파일 경로와 import 하는 과정이 제대로 되었는지 확인해 보세요!
0
선생님 tutorial-part-1 에는 KaggleWord2VecUtility.py 파일 import 하는 코드가 없는데 어찌해야할까요?
위 함수 돌리고 %time clean_train_reviews = apply_by_multiprocessing(train['review'], review_to_words, workers=4)
에서 에러가 발생해요.
word2vec 질문
0
312
1
질문 드립니다
0
335
1
%time clean_train_reviews = apply_by_multiprocessing(\ train['review'], review_to_words, workers=4)
0
337
2
한국어 텍스트 분석과 영어 텍스트 분석의 차이
0
565
1
코랩 실습 링크 파일 다시 올려주시면 안되나요?
0
478
1
강의 자료는 어디서 받을 수 있나요?
0
362
1
data폴더안에 tsv파일이 없다고 나오는데 어떻게 해야하나요?
1
734
4
젠심
1
393
1
질문드립니다
1
242
1
질문드립ㄴ디ㅏ
1
415
3
질문드립니다
1
341
2
word2vec 실행 오류
1
394
1
gensim 4.0 버전 문제
1
2180
1
멀티 프로세싱 오류 질문입니다
1
1109
1
1-2 NLP 텍스트 데이터 처리 오류 관련 질문드립니다.
1
360
1
1강 질문드립니다.
1
242
1
질문드립니다.
1
436
2
질문드립니다.
1
221
1
id 말고 어떤 영화인지는 어떻게 알수있을까요?
1
283
1
[NLP] IMDB 영화리뷰 감정 분석을 통한 파이썬 텍스트 분석과 자연어 처리
1
486
1
has no attribute 'syn0'
2
329
1
영상 "섹션1. [2/4] NLP 텍스트 데이터 전처리" 부분에 대해 질문 있습니다!
1
319
5
wget 오류
1
790
1
html5lib 과 lxml 에서 모두 에러가 발생하고 있습니다.
1
536
1