




판다스 value_counts()와 sort_values()에 대하여 문의합니다
715
작성한 질문수 15
- 먼저 유사한 질문이 있었는지 검색해보세요.
- 서로 예의를 지키며 존중하는 문화를 만들어가요.
- 잠깐! 인프런 서비스 운영 관련 문의는 1:1 문의하기를 이용해주세요.
Industry의 빈도를 순차적으로 결과를 도출하였고
value_counts()는 알아서 빈도가 높은 값부터 낮은 값으로 순처적으로 나온다고 하였는데
그래프를 df["Industry"].value_counts().head(20).plot.barh()
를 통해서 그리니까 빈도수가 반대로 나와서 다시 sort_values()를
통해서 정렬을 했는데요.
그래프로 하면 왜 value_counts()만으로는 빈도수가 제대로 정렬이 안되고
다시 sort_values()를 해줘야 하는걸까요?
그리고df["Market"].value_counts().sort_values().plot.barh()에서는
빈도수대로 정렬을 했는데
sns.countplot(data=df, y="Market").sort_values() 는 오류가 나서
빈도수대로 그래프 정렬은 어떻게 하면 되나요?
sort_values()에 대해서 찾아보는데 정해진 기준에 따라 값을
정렬하는 함수라고 하는데 현재 코딩에서는 어떤 특별한
기준이 설정되거나 주어지지 않은거 같아서요...
무작정 그냥 외우기에는 조금 부족한 느낌이 들어 문의합니다.
감사합니다~
답변 1
1
안녕하세요.
해당 내용은 ETF 시각화에서 자세히 다루는데요.
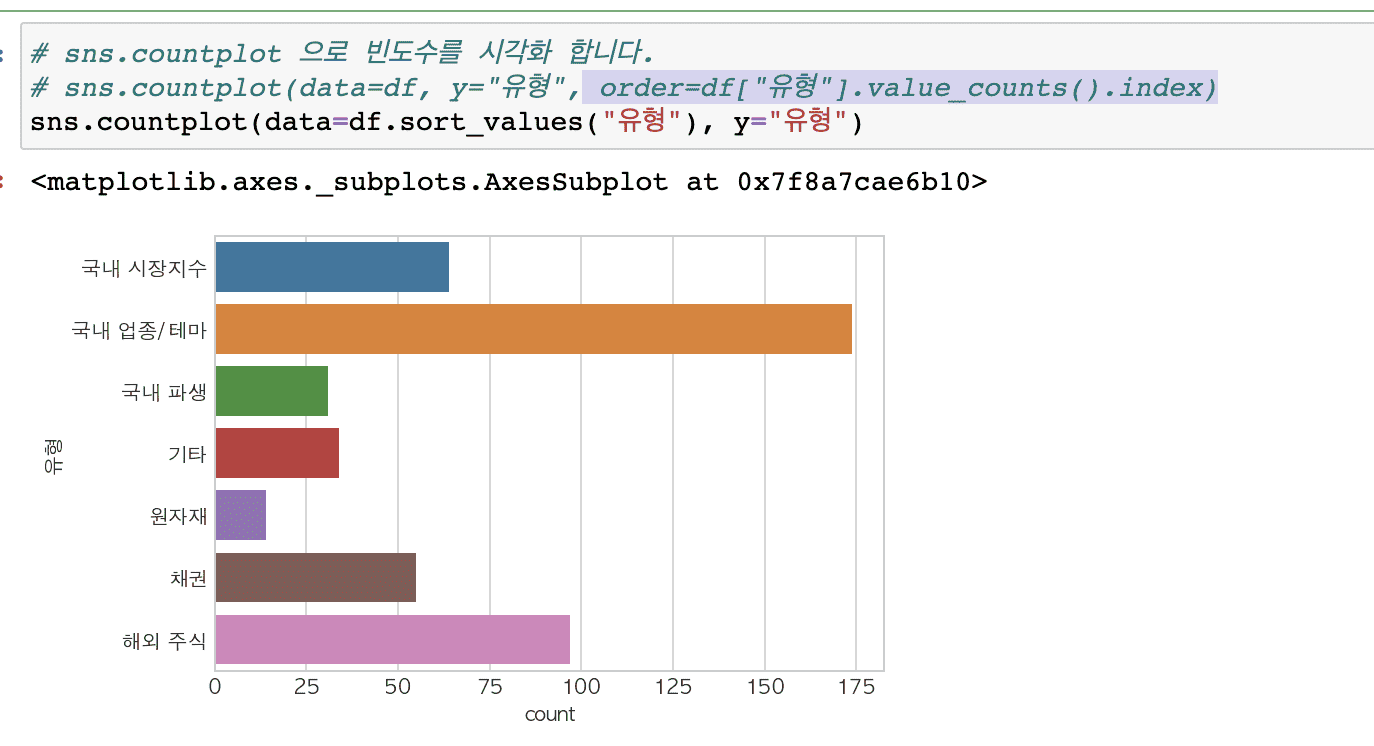
value_counts().barh() 를 하게 되면 빈도수가 낮은게 가장 아래에 표현이 됩니다.
그래서 sort_values()로 다시 정렬이 필요한데, 가로 막대가 그려지는 그래프는 빈도수가 가장 많은게 가장 하단에 오도록 구현이 되어 있어서 반대로 정렬하고자 하면 다시 sort_values()로 정렬이 필요합니다.
그리고 sort_values() 는 판다스의 기능이라 seaborn 에 메서드 체이닝 형태로는 사용할 수가 없습니다.
대신 order 에 정렬할 값을 리스트 형태로 지정하면 해당 값을 기준으로 정렬이 됩니다.
그래서 seaborn 의 countplot 을 사용하기 위해서는 아래와 같이 정렬해줄 값을 순서대로 지정해 주어야 합니다.
sns.countplot(data=df, y="유형", order=df["유형"].value_counts().index)
cufflinks 버전문제로 iplot() 미실행
0
71
2
[수정요청]직접 수집한 주가 데이터로 시각화해보기
0
81
2
pd.read_html(url, encoding='cp949') 에러
0
134
2
fdr.StockListing('KRX') 문제 발생
0
204
2
주식 자동매매 프로그램 제작 관련 조언 부탁드립니다
0
471
1
concat 을 통한 데이터 프레임 합치기 에러 문의
0
131
2
한글폰트 관련해서 문의드립니다.
0
270
2
데이터프레임 칼럼명 문의 드립니다.
0
267
3
금융데이터 수집의 모든것
0
175
2
녹화시점과 현재시점 컬럼명이 변경이 많이 되었을까요?
0
232
2
파이썬 증권 데이터 수집과 분석으로 신호와 소음 찾기 - 섹션1 [2/2]
0
192
1
Mac 환경에서 nbextensions 활성화 하는 방법
0
615
2
pd.concat(result.tolist()) 오류 문의
0
286
1
5.1 제약 데이터 수집 오류 해결
0
255
1
Table of contents 문의드립니다
0
230
2
concat을 통한 데이터프레임 합치기
0
578
2
Reindexing only valid with uniquely valued Index objects 오류 질문입니다.
0
512
1
데이터 비교시 데이터 불일치
0
438
1
dtype={"itemcode": np.object}) 을 dtype={"itemcode": object}) 으로 변경해야 하나요?
0
619
1
질문 : for문 풀어쓰기
0
515
1
파이참에서 Plotly 그래프 실행방법
0
1337
1
5.1 데이터프레임 병합(merge)
0
772
2
쥬피터노트북에서 실행파일 만들기
0
1467
1
주피터노트북 확장팩 설치가 안됩니다.
0
589
2