




crawling시 값을 못가져오는 경우...
314
작성한 질문수 29
답변 1
0
안녕하세요. 우선은 각자 연습해보시는 것은 너무 좋을 수도 있지만, 입문자 레벨에서 다양한 웹페이지를 크롤링 시도를 해보시면 또 역시 이슈가 발생할 수 있는 것은 사실이예요. 본 강의 질문/답변은 강의 영상에 대한 이해가 안가실 때 이부분을 해결해드려야, 다음 단계로 나가실 수 있으실 것 같아서, 오픈해놓은 질문/답변이거든요. 그런데 여기에 각자 크롤링 이슈를 문의하시다보면, 제가 해당 코드를 확인하려면 결국 제가 각자 원하시는 크롤링 코드를 작성하는 상황이 발생하더라고요. 즉, 일종의 외주를 평생 저에게 맡기는 상황이 되버려서요. 이 부분은 양해를 부탁드려요.
가볍게 설명드리면, 요즘에는 크롤링을 막기 위함도 있고, 웹사이트 기술이 발전해서, 일부 데이터는 정적인 웹페이지가 아니라, 특정 데이터를 동적으로 가져옵니다. 동적으로 만들어지기 때문에, 정적인 웹페이지에서 데이터를 크롤링하는 기술로는 크롤링이 안됩니다. 이렇게 동적인 데이터를 크롤링하는 또다른 기술이 selenium 이고요. 관련 기술은 난이도가 조금 높아요. 그래서 관련된 부분은 별도 강의로 상세히 설명은 드리고 있습니다.
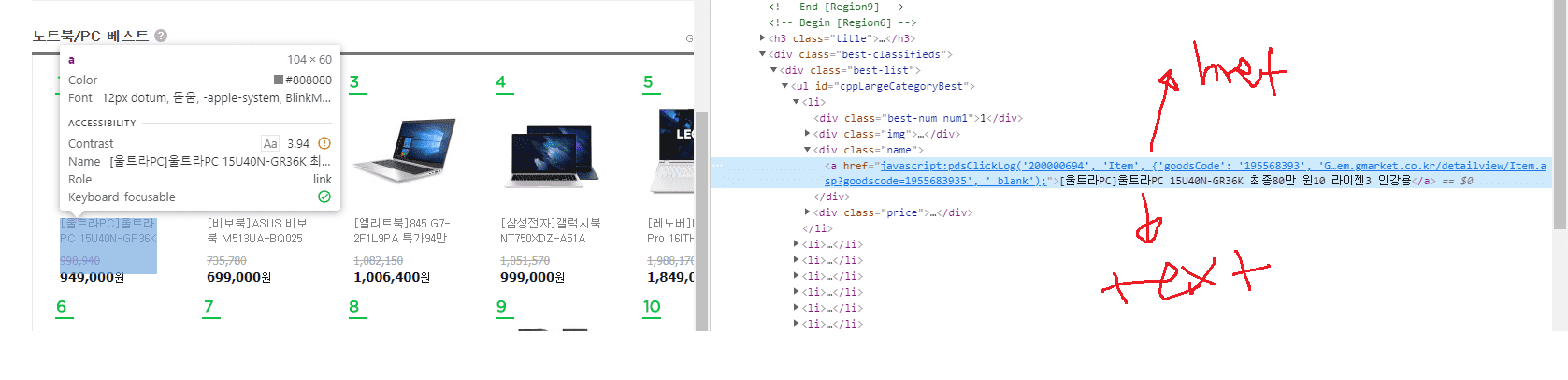
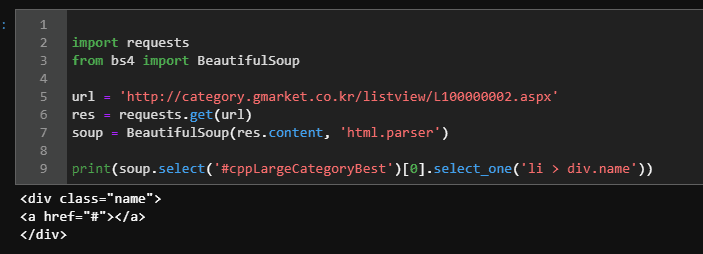
해당 페이지를 오른쪽 클릭하셔서, 소스 보기를 하시면 해당 정적인 웹페이지 태그에는 다음과 같이 나와있더라고요. 이 부분을 보시면 이해하실 수 있으실 것 같습니다.
감사합니다.

33강 9:51 excercise55.
0
34
1
섹션2 - 32강 연습문제 48번 질문
0
40
0
주피터 노트북 사용법 강의 관련
0
43
1
exercise 20. 데이터 구조(리스트)
0
39
0
65강 소리
0
49
1
섹션 5 CSS selector사용해서 클로링하기2의 커리큘럼 일정 부재?
0
70
2
크롤링, 영상을 따라해도 제미나에게 물어봐도 안되요
0
66
1
정규표현식 및 여러 코드 꼭 외워야 하나요?
0
73
1
리스트 함수형도 정수 데이터 받을 수 있나요?
0
72
1
크롤링 관련 질문
0
85
1
문제 답이 없는 버전은 없나요?
0
97
1
requests, BeautifulSoup 임포트 부분에 대해 문의드립니다.
0
108
1
업데이트 강의
0
137
2
선생님 강의중에서 sqlite3 강의를 제공한 강의가 있나요?
0
166
2
연습용 예제 파일
0
98
1
lxml 관련 오류
0
130
1
SAVE Request 창 띄우는 법
0
114
1
포스트맨 사용법이 바뀌어서 강의를 따라가지 못하겠습니다. 2
0
100
1
포스트맨 사용법이 바뀌어서 강의를 따라가지 못하겠습니다.
0
132
1
예제 2, 4, 6에 대한 풀이 방식 질문.
0
114
1
문제 파일
0
99
1
pdf 파일 내 코드 복붙시 공백
0
326
1
데이터 저장 강좌 문의 건
0
115
1
" " 와 ' '의 차이를 알고 싶습니다
0
286
1