




4분 drop_duplicates 질문드립니다
218
작성한 질문수 27
혼자서 데이터를 파헤쳐보며 연습하고 있는데요,
keep='last'조건을 주신거에대한 반례가 있는것 같아서 질문드립니다.

다음과 같이 US는 굉장히 많은 iso2들이 있습니다.
이 경우는 운좋게 keep='last' 적용했을 때 US로 출력됩니다.
하지만
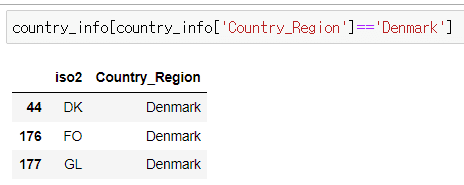
이 경우에는 덴마크에 대한 iso2(아마 지역구 별로 다르게 입력됐었던 것 같습니다) 는 덴마크의 keep='last'로 다뤘을때 옳은 값인 DK가 아닌 GL로 출력되게 되는데요.
이런 현상에 대해서 전체적으로 keep='last'를 적용하는게 맞나 싶어서 질문드립니다!
답변 1
0
음 우선은 직접 작성해보신 것이니까요. 제가 전체 코드까지는 잘 모르겠지만,
keep='first'가 default 이며, 중복값이 있으면 첫번째 값을 keep='last'는 그 반대로 마지막값을 선택한다고, 영상에서 설명을 드렸을 것이고, 해당 기능에 맞게 동작한 것으로 이해가 됩니다. 다음 실제 각 함수의 기능에 대해서도 확인을 해보신다면 좀더 이해가 가실 것 같고, 사실 영상에서도 역시 유사하게 설명을 드려서, 다시 한번 관련 기능에 대해서 영상을 보셔도 괜찮을 것 같은데, 어떠신가요?
https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.drop_duplicates.html
0
저도 이 부분에 대해 질문드리려고 하여 작성합니다. 전 이 작성자 님 말이 너무 이해가 가는데요.... 옳은값이 dk가 아닌 gl로 출력되는데 모든 상황에서 first로 설정하는게 맞는지 여쭤본건데 그게 맞는 답변은 없으신건가요 ??
Python 3 표시 없습니다.
0
91
1
강의실습 말고 강의에 대한 자료(pdf)가 없을까요?
0
104
1
구글 코랩과 아나콘다
0
121
1
강의와 다르게 오류가 뜨는 이유가 뭘까요?
0
133
1
COVID-19-master 관련 등 자료 누락
0
112
1
수업자료에 python_core_summary.ipynb 파일이 포함되어 있지 않습니다!
1
122
1
json.dumps관련된 질문
0
97
1
빅분기대비
0
124
1
파이썬으로 Plain Text 포멧 파일 다루기 연습문제 질문
0
115
1
강의자료 어디서 다운로드받나요?
0
157
1
pandas 라이브러리의 quotechar 인자에 대해 질문드립니다
0
122
1
iplot 에러 문제
1
220
1
플래그
0
84
1
플래그 라이브러리
0
98
1
CSV 파일 쓰기 다른 기법(사전 타입으로 쓰기) 관련
0
213
1
CSV 파일 읽을 때 오류
0
216
1
read() 함수 사용할 때 3번째 줄에 data로 출력 또는 print(data)로 출력 차이
0
154
1
강의 교재 및 실습 파일 제공되나요?
0
199
1
deep_data_and_visual 파일에서 에러가 납니다.
0
201
1
apply()함수
0
223
1
pandas groupby sum 질문
1
290
1
pandas_eda 자료 맨아래 heatmap 숫자가 안나옵니다
0
370
2
pandas_eda 힛맵에서 숫자가 안떠요
0
264
1
수업 자료에 pandas_basic 파일이 없습니다..!
0
285
1