




[빠짝스터디 1주차 과제] ARRAY STRUCT, PIVOT, 퍼널 쿼리 연습문제
107
작성한 질문수 5
<목차>
이번주차 중요 키워드
ARRAY, STRUCT 연습문제 1~4
추가 인사이트
PIVOT 연습문제 1~4
퍼널분석 연습문제
1주차 느낀점 및 하고싶은 말 (솔직후기)
🔐 이번주차 중요 키워드 : ARRAY(배열), STRUCT(구조체),pivot, 퍼널분석
✅ ARRAY, STRUCT 연습문제 1
<INPUT> advanced.array_exercises
<OUTPUT> title | genre
## 1) array_exercises 테이블에서 각 영화(title)별로 장르(genres)을 UNNEST해서 보여주세요. SELECT title, genre FROM advanced.array_exercises AS ae CROSS JOIN UNNEST (genres) AS genre
📊 추가 인사이트 정리
Q. 어느 genre에서 가장 많은 영화가 있을까?
A. action에서 가장 많은 영화가 있군, 나도 action 좋아하는데 2024년 베놈(venom)2 보러가야징 ㅎ

✅ ARRAY, STRUCT 연습문제 2
<INPUT> 위와 동일한 데이터 셋 advanced.array_exercises
<OUTPUT> title | actor | character
## 2) array_exercises 테이블에서 각 영화(title)별로 배우(actor)와 배역(character)을 보여주세요. 배우와 배역은 별도의 컬럼으로 나와야 합니다.
SELECT
title,
actor.actor,
actor.character
FROM advanced.array_exercises AS ae
CROSS JOIN UNNEST (actors) as actor
# actors = [STRUCT(STRING,STRING)], array 형태이므로 SAFE_OFFSET으로 직접 데이터에 접근해도
# 되지만, 새로운 컬럼으로 만들어지기 때문에 long format이 아니라 wide format으로 테이블이 만들어진다.
actors[SAFE_OFFSET(0)].actor AS first_actor
actors[SAFE_OFFSET(1)].character AS second_character
✅ ARRAY, STRUCT 연습문제 3
<INPUT> 위와 동일한 데이터 셋 advanced.array_exercises
<OUTPUT> title | actor | character | genre
### 3) array_exercises 테이블에서 각 영화(title)별로 배우(actor), 배역(character), 장르(genre)를 출력하세요.
SELECT title,
actor.actor as actor,
actor.character as character,
genre
FROM advanced.array_exercises as ae
cross join unnest(actors) as actor
cross join unnest(genres) as genre✅ ARRAY, STRUCT 연습문제 4
<INPUT> 위와 동일한 데이터 셋 advanced.array_exercises
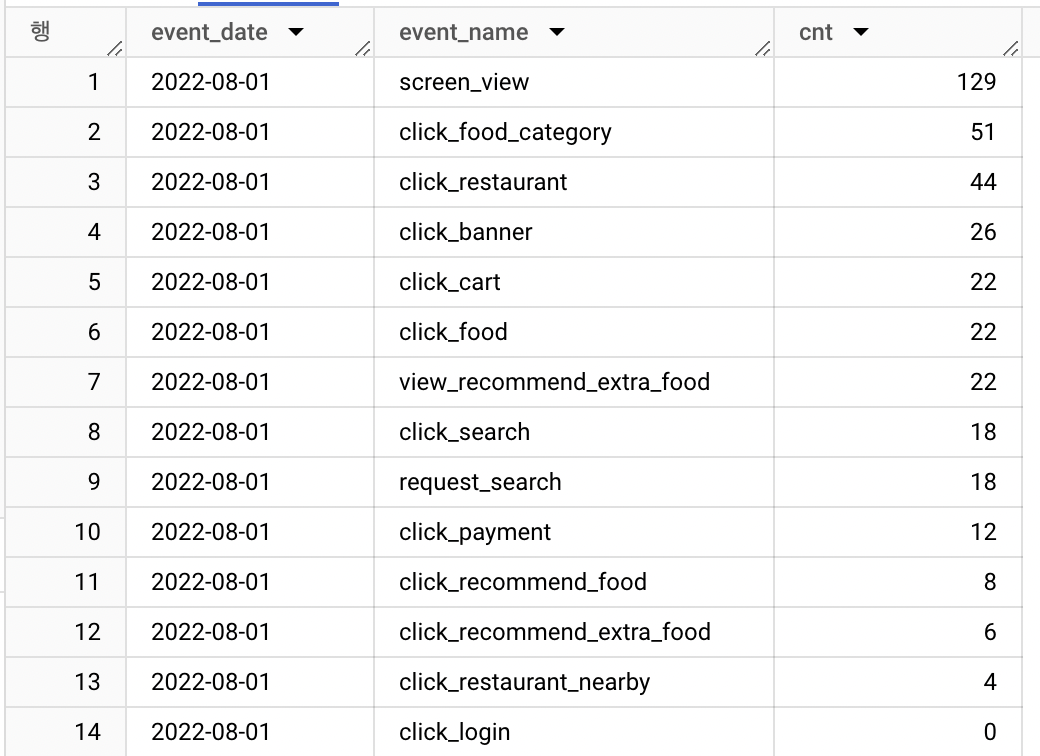
<OUTPUT> user_id | event_date | event_timestamp | event_name | key | string_value | int_value | user_id_1 | user_id_2 | user_id
### 4) 앱 로그 데이터 풀어주세요. # 데이터 - 미리보기 - event_params의 데이터 유형 RECORD = STRUCT
WITH app_log AS (
select
user_id,
event_date,
event_timestamp,
event_name,
event_param.key as key,
-- event_param.value as value,
event_param.value.string_value as string_value,
event_param.value.int_value as int_value
-- event_params,
from advanced.app_logs
cross join unnest(event_params) as event_param
where event_date = '2022-08-01'
)
<추가 인사이트 코드 추가>
select event_date,
event_name,
COUNT(DISTINCT user_id) as cnt
from app_log
GROUP BY ALL
ORDER BY cnt DESC
SELECT event_date,
event_name,
cnt,
LAG(cnt) OVER (ORDER BY cnt DESC) as before_event_cnt,
ROUND(1 - (cnt / LAG(cnt) OVER (ORDER BY cnt DESC)),2) as churn_rate
FROM (
select event_date,
event_name,
COUNT(DISTINCT user_id) as cnt
from app_log
GROUP BY ALL
)
ORDER BY cnt DESC
📊 추가 인사이트 정리
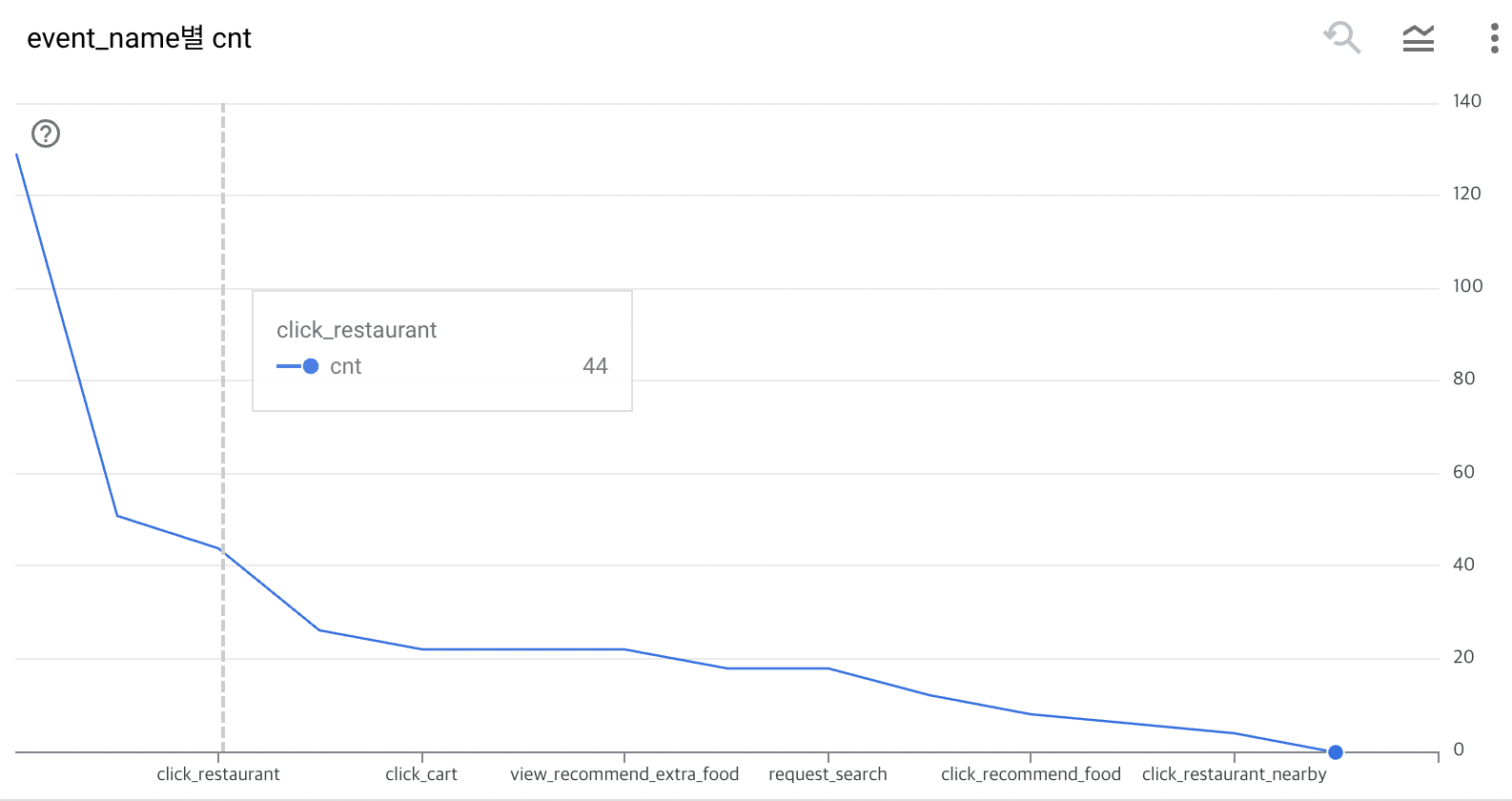
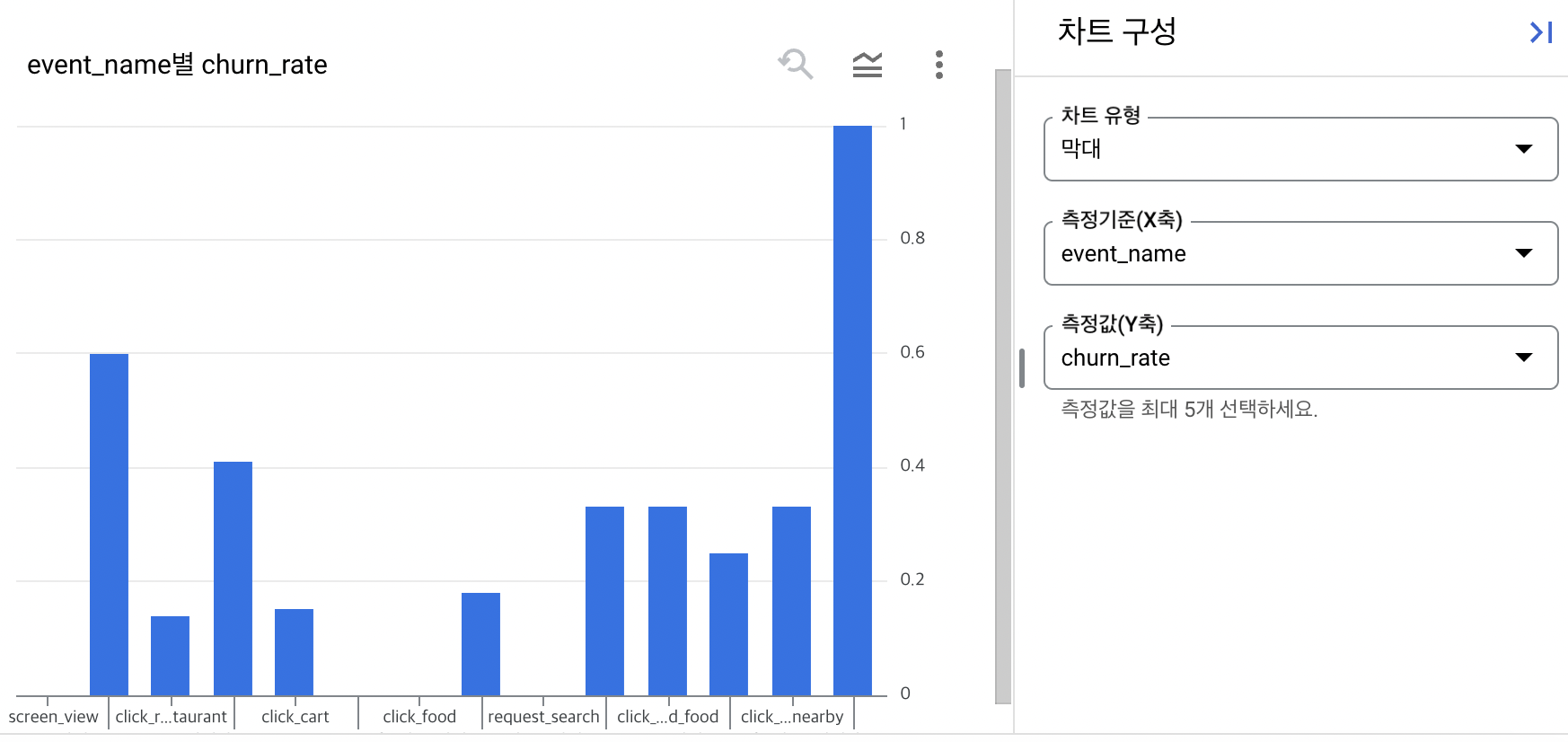
Q. 어디 event에서 가장 많이 이탈하고 있는지? 파악해주세요.
A. 퍼널단계가 다음 표와 같은 순서이고, 데이터 정합성이 있다고 가정하고, 1- 리텐션율 = 이탈율이라 했을때 churn rate은 아래 3가지 단계에서 이탈율이 가장 높음 → 추후 더 자세히 살펴볼 필요가 있음
(1) click_restaurant_nearby > click_login,
(2) screen_view > click_food_category
(3) click_restaurant > click_banner

✅ Pivot 연습문제 1
<INPUT> advanced.orders
<OUTPUT> order_date, user_id_1, user_id_2, user_id_3
-- 1) orders 테이블에서 유저(user_id)별로 주문금액(amount)의 합계를 PIVOT 해주세요. -- 날짜(order_date)를 행(row)으로, user_id를 열(column)으로 만들어야 합니다.
SELECT order_date,
SUM(IF (user_id = 1, sum_of_amount,0)) as user_id_1,
SUM(IF (user_id = 2, sum_of_amount,0)) as user_id_2,
SUM(IF (user_id = 3, sum_of_amount,0)) as user_id_3
FROM (
SELECT order_date,
user_id,
SUM(amount) as sum_of_amount
FROM advanced.orders
GROUP BY order_date, user_id
)
GROUP BY order_date
ORDER BY order_date
✅ Pivot 연습문제 2
<INPUT> advanced.orders
<OUTPUT> user_id | 2023-05-01 | 2023-05-02 | 2023-05-03 | 2023-05-04 | 2023-05-05
-- 2) orders 테이블에서, 날짜(order_date)별로 유저들의 주문금액(amount)의 합계를 pivot 해주세요. user_id를 행(row)으로, order_date를 열(column)으로 만들어야 합니다.
with tbl_2 as (
select user_id,
order_date,
sum(amount) as amount
from advanced.orders
group by all
order by 1,2
)
# 이름 지정 오류 해결법 : column alias 지정할떄, 영어제외하고 날짜형 백틱(`)을 통해 지정할 수 있음
# MAX 대신 ANY_VALUE() 함수는 그룹화 할 대상 중 임의의 값을 선택하는 함수(null 제외)
select user_id,
MAX(if(order_date = "2023-05-01", amount,0)) as `2023-05-01`,
MAX(if(order_date = "2023-05-02", amount,0)) as `2023-05-02`,
MAX(if(order_date = "2023-05-03", amount,0)) as `2023-05-03`,
MAX(if(order_date = "2023-05-04", amount,0)) as `2023-05-04`,
MAX(if(order_date = "2023-05-05", amount,0)) as `2023-05-05`
from tbl_2
group by all
✅ Pivot 연습문제 3
<INPUT> advanced.orders
<OUTPUT> user_id | 2023-05-01 | 2023-05-02 | 2023-05-03 | 2023-05-04 | 2023-05-05
--3 ) order 테이블에서 사용자(user_id)별, 날짜(order_date)별 주문이 있다면 1, 없다면 0으로 pivot 해주세요.
-- user_id를 행(row)으로, order_date를 열(column)로 만들고, 주문을 많이 해도 1로 처리합니다.
select user_id,
MAX(if(order_date = "2023-05-01", 1,0)) as `2023-05-01`,
MAX(if(order_date = "2023-05-02", 1,0)) as `2023-05-02`,
MAX(if(order_date = "2023-05-03", 1,0)) as `2023-05-03`,
MAX(if(order_date = "2023-05-04", 1,0)) as `2023-05-04`,
MAX(if(order_date = "2023-05-05", 1,0)) as `2023-05-05`
from tbl_2
group by user_id
✅ Pivot 연습문제 4
<INPUT> advanced.app_logs
<OUTPUT> event_date | event_timestamp | event_name | user_id |user_pseudo_id | firebase_screen | food_id | session_id
--4 ) 앱 로그 데이터 배열 PIVOT 하기
# 참고로 unique key는 user_id + event_timestamp
select
-- * EXCEPT(event_params) #except(컬럼) : 컬럼을 제외하고 모두 다 보여주는..!
event_date,
event_timestamp,
event_name,
user_id,
user_pseudo_id,
max(if(param.key = "firebase_screen", param.value.string_value, NULL)) as firebase_screen,
max(if(param.key = "food_id", param.value.int_value, null)) as food_id,
max(if(param.key = "session_id", param.value.string_value,null)) as session_id
from advanced.app_logs
cross join unnest(event_params) as param
where event_date = '2022-08-01'
group by all
limit 100
✅ 퍼널 분석 (Funnel) 연습문제
<INPUT> advanced.app_logs
<OUTPUT> event_date | event_name_firebase_screen | step_number | user_cnt
-- 퍼널 단계 : welcome, home, food_category, restaurant, cart, click_payment
-- event_name, firebase_screen 연결되어 해당 퍼널의 값 | step_number | cnt
-- 기간 : 2022-08-01 ~ 2022-08-18
-- 사용할 데이터 : advanced.app_logs
with unnest_tbl as (
select
-- * EXCEPT(event_params) #except(컬럼) : 컬럼을 제외하고 모두 다 보여주는..!
event_date,
event_timestamp,
event_name,
user_id,
user_pseudo_id,
max(if(param.key = "firebase_screen", param.value.string_value, NULL)) as firebase_screen,
max(if(param.key = "food_id", param.value.int_value, null)) as food_id,
max(if(param.key = "session_id", param.value.string_value,null)) as session_id
from advanced.app_logs
cross join unnest(event_params) as param
where event_date BETWEEN '2022-08-01' AND "2022-08-18"
group by all
)
, filter as (
select
* EXCEPT(event_name, firebase_screen, event_timestamp),
concat(event_name, '-', firebase_screen) as event_name_firebase_screen ,
DATETIME(TIMESTAMP_MICROS(event_timestamp), 'Asia/Seoul') as event_time
from unnest_tbl
where event_name IN ("screen_view", "click_payment")
)
SELECT event_date,
event_name_firebase_screen,
CASE WHEN event_name_firebase_screen = "screen_view-welcome" then 1
WHEN event_name_firebase_screen = "screen_view-home" then 2
WHEN event_name_firebase_screen = "screen_view-food_category" then 3
WHEN event_name_firebase_screen = "screen_view-restaurant" then 4
WHEN event_name_firebase_screen = "screen_view-cart" then 5
WHEN event_name_firebase_screen = "click_payment-cart" then 6
ELSE NULL
END AS step_number,
COUNT(DISTINCT user_pseudo_id) as cnt
FROM filter
group by all
having step_number IS NOT NULL
order by event_date
👩💻 1주차 느낀점 및 하고싶은 말 (솔직후기)
(1) ARRAY, STRUCT - 빅쿼리 사용법은 처음이라 이 문법은 생소했습니다. 학습완료!
(2) PIVOT - 태블로로 시각화할떄 long format으로 시각화하려다 보니 쿼리 로딩시간이 초과되어 alert을 받은 적이 있습니다. ㅎㅎ.. 이때 SQL로는 pivot하는 방법을 잘 몰랐는데 학습완료!
(3) 퍼널 분석 - 퍼널분석의 큰 흐름은 대충 알고 있었는데 퍼널분석 종류나 집계기준 종류, 해석하는 법 등 퍼널 분석 결과를 어떻게 바라보아야 하는지 정리해주셔서 명쾌했다.
쿼리 기초문법은 이론적으로 알고 있었으나 첫 데이터관련 인턴을 하면서, 실무에서 하는 업무는 그보다 더 복잡하고, 비즈니스적으로 어떻게 바라보아야 하고, 해석해야하는지 중요하다는 것을 알게되었습니다.
그러나, 실무에서 또한 의문점이 발생해도 명쾌한 해답을 얻기 어려웠습니다. 이에 데이터 분석가를 희망은 하고 있지만, 어떻게 공부해야 할지에 대한 지속적으로 의문이 들었습니다.
그때 마침, 카일스쿨님의 강의를 우연히 접하게 되었고, 그동안 조각조각이었던 개념들을 SQL로 작성하고, 시각화까지 하는방법들을 모두 보여주시면서 데이터분석에 대한 자신감이 붙을 수 있었던 것 같습니다.
카일스쿨님이 그동안 걸어오신 길이 모두 보이는 강의였습니다. 강의 만들어주셔서 정말 감사합니다. 🙏
답변 1
0
안녕하세요, 인프런 AI 인턴입니다. JYP님.
BigQuery를 이용한 ARRAY와 STRUCT를 다루고 PIVOT, 퍼널 분석 연습을 해보셨군요. 이러한 SQL 기능들은 데이터의 구조화 및 분석에 있어 매우 중요한 역할을 합니다. 이러한 새로운 자료형을 익히는 과정은 초기에는 복잡하게 느껴질 수 있지만, 데이터 분석을 보다 효율적으로 수행하는 데 큰 도움이 될 것입니다.
여러분의 연습 문제를 통해 ARRAY와 STRUCT 데이터 타입을 다루고 이를 언네스트(UNNEST)하여 원하는 데이터를 출력하는 방법을 연습하셨습니다. 이러한 연습은 실제 데이터 분석 작업에서 매우 유용하게 사용될 수 있습니다.
유사한 질문과 답변을 통해 더 깊이 있는 정보를 얻고 싶으시다면 아래 링크들을 참조해 보세요:
BigQuery에서 STRUCT와 ARRAY 활용하기 - 구조체와 배열을 활용하여 데이터를 처리하는 기법에 대해 더 깊이 있는 설명을 볼 수 있습니다.
퍼널 SQL 쿼리 작성 시 오류 해결 - 퍼널 분석 시 자주 발생하는 문제들과 그 해결책에 대한 다양한 사례가 담겨 있습니다.
이 링크들은 JYP님의 데이터 분석 과정에 많은 도움이 될 것입니다. 질문자님의 이해를 돕고자 지식공유자님의 기존 답변을 참고하여 유사한 답변 링크를 추천해드리고 있습니다. 현재 베타 기능으로 답변이 만족스럽지 않을 수 있는 점 양해 부탁드립니다. 🙏 추가적으로 궁금한 점이 있으시면, 이어서 질문해 주세요. 곧 지식공유자께서 답변해 주실 것입니다.
최종 과제 제출
0
117
3
BigQuery 활용편 18강 질문있습니다!
0
97
1
리텐션 공부하다가 궁금한게 생겨 질문드립니다
0
99
2
안녕하세요 강사님 코호트 쿼리 공부하다가 의문점이 생겨서 문의드립니다
0
94
2
biquery 테이블 생성 오류 이슈
0
70
2
동일하게 쿼리를 작성했는데 화면과 다른 값이 나옵니다
0
84
2
[과제] 퍼널 PIVOT 테이블 작성하기
0
78
2
array 등
0
73
2
N day 리텐션 쿼리 관련 질문
0
73
2
이동평균 계산 시 order by 기본값은 뭔가요?
0
79
2
윈도우 연습문제 1번 질문
0
79
1
user_id에 NULL이 나오는데 정상인가요?
0
83
2
3-13 리텐션 과제 제출
0
110
2
최종 과제 제출
0
141
3
weekly retention 구하기 과제
0
101
2
1-9. 피벗 쿼리 작성
0
91
2
app_logs 테이블 생성 문제
0
87
2
Weekly Retention 구하기 완성하였습니다.
0
88
2
[과제] 퍼널 쿼리(피벗테이블 적용) 작성 완료
0
118
2
3-7 Weekly, Monthly Retention 쿼리 작성
0
96
2
정성 데이터 분석 방법 문의
0
178
1
최종 과제 제출
0
113
3
1-6 예시 문제 풀이
0
73
2
최종과제 제출
0
157
2