




주피터 노트북 결과가 안나옵니다.
332
작성한 질문수 2
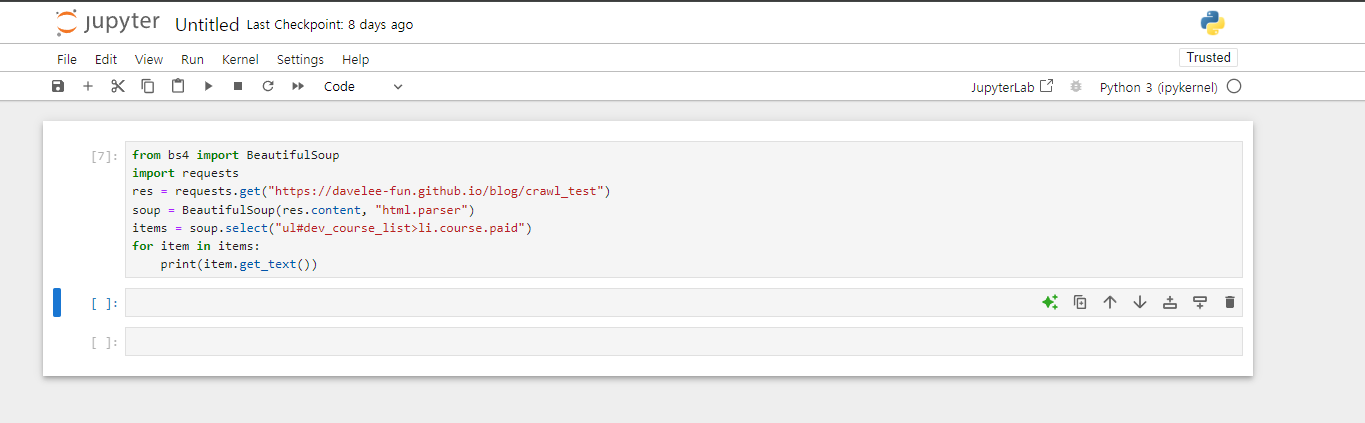
css selector 사용해서 크롤링하기 1 강의도중에 아래와같이 작성후 run 실행시켜도 결과가 안나오고 아무런
반응이없습니다.
에러도 안뜨고 보시다싶이 다른셀 실행되는것도 없는데 이런문제는 어덯게 해결하나요?
답변 1
0
안녕하세요. 답변 도우미입니다.
사이트 주소가 영상과 달라서, 해당 페이지에 해당 태그가 없기 때문에, 아무것도 출력이 안된 것으로 이해가 됩니다. 영상에서는 다음 페이지로 설명을 드리고 있습니다.
https://davelee-fun.github.io/blog/crawl_test_css.html
참고로, 일반적으로 작성된 코드에서 실행은 되었으나 결과가 출력되지 않는 이유는 여러 가지가 있을 수 있습니다. 몇 가지 참고할만한 점검해야 할 부분을 알려드리겠습니다.
### 1. URL 확인
우선 requests.get()으로 가져온 URL이 정확하게 동작하는지 확인해보세요. 웹페이지가 응답하지 않거나 접근할 수 없는 경우, 빈 데이터를 반환할 수 있습니다.
```python
print(res.status_code) # 응답 상태 확인
print(res.text) # 페이지 내용 확인
```
위 코드를 추가해서 웹페이지가 제대로 로드되는지 먼저 확인해보세요. 상태 코드가 200이어야 정상적으로 접근이 된 것이고, res.text로 가져온 내용이 빈 값이 아닌지 확인해보세요.
### 2. CSS 선택자 확인
CSS 선택자가 정확하지 않으면 원하는 데이터를 찾을 수 없습니다. 선택자가 제대로 작동하는지 확인하기 위해 선택된 항목이 있는지 먼저 확인하세요.
```python
print(len(items)) # 선택된 요소의 개수 출력
```
만약 len(items)가 0이면 CSS 선택자가 잘못되었을 가능성이 있습니다. 웹 페이지 구조가 변경되었을 수 있으니, 페이지의 HTML 구조를 다시 확인하고 적절한 선택자를 사용해야 합니다.
예를 들어 ul#dev_course_list>li.course.paid가 맞는지 다시 한 번 확인하세요. 선택자가 잘못된 경우 페이지의 HTML 요소를 브라우저 개발자 도구에서 다시 찾아보시고, 올바른 선택자를 지정해 주세요.
### 3. BeautifulSoup 파서 옵션
현재 "html.parser"를 사용하고 있는데, 파서 옵션에 문제가 있을 가능성도 있습니다. lxml 파서를 사용하는 것도 하나의 방법입니다. 먼저 lxml이 설치되어 있는지 확인하고 아래와 같이 수정해보세요.
```python
soup = BeautifulSoup(res.content, "lxml")
```
### 4. 네트워크 문제 또는 웹사이트 차단
일부 웹사이트는 크롤링을 방지하기 위해 요청을 차단하기도 합니다. 이를 피하려면 headers를 추가해 사람의 브라우저에서 요청한 것처럼 요청을 위장할 수 있습니다.
```python
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
res = requests.get("https://davelee-fun.github.io/blog/crawl_test", headers=headers)
```
### 최종 코드 예시
```python
from bs4 import BeautifulSoup
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'}
res = requests.get("https://davelee-fun.github.io/blog/crawl_test", headers=headers)
if res.status_code == 200:
soup = BeautifulSoup(res.content, "html.parser")
items = soup.select("ul#dev_course_list>li.course.paid")
if items:
for item in items:
print(item.get_text())
else:
print("선택된 항목이 없습니다.")
else:
print("웹 페이지를 불러오지 못했습니다.", res.status_code)
```
위 코드로 실행해보고 결과가 나오는지 확인해보세요.
감사합니다.
잔재미코딩 드림
33강 9:51 excercise55.
0
26
1
섹션2 - 32강 연습문제 48번 질문
0
31
0
주피터 노트북 사용법 강의 관련
0
33
1
exercise 20. 데이터 구조(리스트)
0
34
0
65강 소리
0
39
1
섹션 5 CSS selector사용해서 클로링하기2의 커리큘럼 일정 부재?
0
51
2
크롤링, 영상을 따라해도 제미나에게 물어봐도 안되요
0
56
1
정규표현식 및 여러 코드 꼭 외워야 하나요?
0
61
1
리스트 함수형도 정수 데이터 받을 수 있나요?
0
66
1
크롤링 관련 질문
0
76
1
문제 답이 없는 버전은 없나요?
0
92
1
requests, BeautifulSoup 임포트 부분에 대해 문의드립니다.
0
100
1
업데이트 강의
0
121
2
선생님 강의중에서 sqlite3 강의를 제공한 강의가 있나요?
0
152
2
연습용 예제 파일
0
90
1
lxml 관련 오류
0
119
1
SAVE Request 창 띄우는 법
0
110
1
포스트맨 사용법이 바뀌어서 강의를 따라가지 못하겠습니다. 2
0
92
1
포스트맨 사용법이 바뀌어서 강의를 따라가지 못하겠습니다.
0
118
1
예제 2, 4, 6에 대한 풀이 방식 질문.
0
108
1
문제 파일
0
94
1
pdf 파일 내 코드 복붙시 공백
0
319
1
데이터 저장 강좌 문의 건
0
108
1
" " 와 ' '의 차이를 알고 싶습니다
0
273
1