




04-13) slugify가 작동하지 않습니다
질문을 온전히 이해할 수 있도록, 모든 맥락을 전달해주세요.
질문은 질문자가 번거로워야 보다 좋은 답변을 얻으실 수 있습니다.
시행착오를 알려주시면 곧바로 원하는 문제에 집중할 수 있습니다.
오류 메시지는 일부만 알려주시기보다 전체 오류 메시지를 캡처해서 주시면, 오류 파악에 도움이 됩니다.
당신의 파이썬/장고 페이스메이커가 되겠습니다. ;-)
인프런 서비스 운영 관련 문의는 1:1 문의하기를 이용해주세요.
===================================
Song 모델, slug 필드 추가에서 질문이 몇 가지 있습니다.
우선, Meta 속성 추가는 makemigration을 위한 것이고, get_absolute_url method는 template에서 호출하기 위해 정의한 것으로 이해했습니다.
첫 질문은 makemigration을 두 단계로 나눈 이유가 있나요?
class Migration(migrations.Migration): dependencies = [ ("hottrack", "0001_initial"), ] operations = [ migrations.AddField( model_name="song", name="slug", field=models.SlugField(allow_unicode=True, blank=True), ), migrations.AddIndex( model_name="song", index=models.Index(fields=["slug"], name="hottrack_so_slug_7cf104_idx"), ), migrations.RunPython(forward_code, reverse_code=migrations.RunPython.noop) ]이런식으로 한번에 처리하면안되나요?
또한 영상 8:06 실습 영상에서는 생략되어있지만 5:40 설명하실 때는
class Song(models.Model):
melon_uid = models.CharField(max_length=20, unique=True)
rank = models.PositiveSmallIntegerField()
album_name = models.CharField(max_length=100)
name = models.CharField(max_length=100)
artist_name = models.CharField(max_length=100)
cover_url = models.URLField()
lyrics = models.TextField()
genre = models.CharField(max_length=100)
release_date = models.DateField()
like_count = models.PositiveIntegerField()
slug = models.SlugField(allow_unicode=True, blank=True)
class Meta:
# Model의 related field, primary key에 대해서는 자동으로 index가 생성된다.
# 이외에 model을 쿼리할 때 자주 사용되는 field인 경우 index 생성을 고려해보는 것이 좋다
indexes = [
models.Index(fields=["slug"])
]
def slugify(self, force=False):
if force or not self.slug:
self.slug = slugify(self.name, allow_unicode=True)
def save(self, *args, **kwargs):
self.slugify()
super().save(*args, **kwargs)
@property
def get_absolute_url(self) -> str:
# slug = slugify(self.name, allow_unicode=True)
######################################################
print("-----------check-----------")
self.save() # 강의 상에서 누락
#######################################################
return reverse(
viewname="hottrack:song_date_detail",
args= [
self.release_date.year,
self.release_date.month,
self.release_date.day,
self.slug,
]
# kwargs={"pk": self.pk}
)get_absolute_url 내부에 self.slugify()를 호출하여 detail 버튼을 클릭하였을 때 slug가 없으면 name으로 부터 slugify를 수행하는 것으로 이해하였는데 그 경우 db에 저장되지 않습니다. 그래서 제 경우 임으로 self.save()로 줄을 추가하여 db에 저장되도록 하였습니다.
테스트를 위해 0002 migration만 진행하여 빈 slug필드만 생성하였습니다.

그러나 버튼을 눌러 페이지를 호출 시
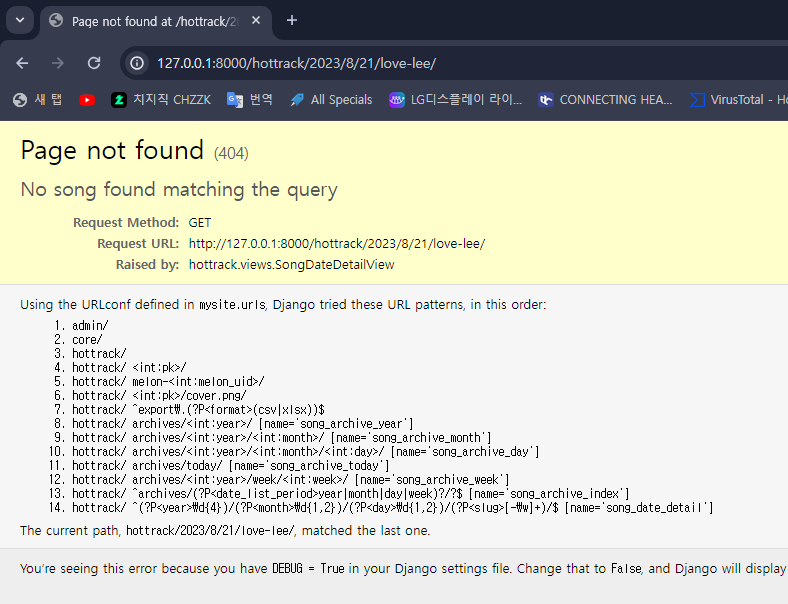
url은 정상적으로 생성되었으나 db 업데이트가 이루어지지 않아 404 not found가 발생합니다. 추가적으로
 print 문도 stream에 나오지 않습니다. 아마 template단에서 method를 콜해서 그런거 같은데 문제가 뭔가요?
print 문도 stream에 나오지 않습니다. 아마 template단에서 method를 콜해서 그런거 같은데 문제가 뭔가요?
만약 제가 이해한 바가 틀리다면, save와 slugify method는왜 정의했으며 어디에 사용되는 건가요?
답변 2
1
안녕하세요.
마이그레이션은 여러 파일로 나누어진 작업(operations)들을 필요에 따라 합칠 수 있습니다. 장고에서는 마이그레이션 파일 단위로 실행하고 롤백할 수 있기 때문에, 원자적(Atomic)으로 실행되어야할 단위로 마이그레이션 파일을 나누구요. 하나의 마이그레이션 파일로 수행되었을 때, 데이터베이스의 부하가 너무 심하게 걸린다고 판단이 될 경우, 나누기도 합니다. 여러 마이그레이션 파일을 하나로 합치셔도 됩니다. 선택의 문제일 뿐이구요.
대개 마이그레이션 파일은 모델의 변경 내역에 대해서만 생성되는 것으로 아시는 분들이 많은데요. 강의에서는 빈 마이그레이션 파일을 원하는 이름으로 생성할 수 있음을 보여드리고 싶었습니다.
---
slug 필드는 name 필드 기반에서 생성하고 있는 데요. slug 값은 대개 최초 생성 시에만 name 필드를 기반으로 자동생성되고, 그 이후에는 변경되지 않고 유지되어야 합니다. 이는 해당 slug 주소가 검색엔진에 의해 이미 색인되었을 수 있기 때문입니다. slug 값이 변경되면 기존 URL로 접근하던 사용자들은 해당 페이지를 찾을 수 없게 됩니다.
그래서 slug 값은 레코드 생성 시 1회에 한해서만 자동 생성하고, 그 후에는 자동 변경하지 않는 것이 좋구요. 만약 slug 값을 수정해야할 특별한 경우가 있다면, 직접 입력을 받아 수정토록 하는 것이 일반적입니다.
get_absolute_url 메서드에서 self.slugify() 메서드를 호출한 것은 slug 모델 필드를 추가하고, 아직 모든 레코드에 slug 값이 완전히 채워지지 않은 과도기적 상황에서, URL Reverse시에 임시방편으로 slug 필드 값을 채워주기 위함이었습니다.
그리고 get_absolute_url 메서드는 단순히 조회 기능만 수행해야 합니다. 만약 조회 과정에서도 매번 UPDATE 쿼리가 실행된다면 데이터베이스에 불필요한 부하가 발생되어 애플리케이션 성능이 낮아집니다. 따라서 get_absolute_url 메서드에서는 self.slugify 메서드와 self.save 메서드를 호출하지 않는 것이 올바른 방법입니다.
Song 모델에서 slug 값의 존재 여부를 매번 확인하여 저장하는 것보다는, slug 값이 항상 존재하도록 보장하는 것이 애플리케이션의 관리와 성능 측면에서 더 효과적입니다. 따라서 저는 slug 값을 save 메서드 호출 시에 명시적으로 지정하고 저장하는 것을 추천드립니다. 이렇게 하면 slug 값이 항상 존재한다는 것을 확신할 수 있고, 불필요한 추가 로직을 작성할 필요가 없어집니다.
또한 이 방법은 데이터베이스 쿼리의 효율성도 높여줍니다. slug 값의 존재를 보장함으로써, 애플리케이션의 안정성과 성능을 향상시킬 수 있습니다.
살펴보시고, 질문 남겨주세요.
화이팅입니다. :-)
0
말씀하신 대로라면 slug 필드를 생성하고 데이터를 채우는 방법을
migrate 명령어를 통한 방법
class 내에 method로 정의하는 방법
두 가지를 보여주신 것이고 영상에서 실행은 1번만 했고 2번은 구현만 한 것이며,
2번 방법을 수행하기 위해서는
song_qs = Song.objects.all()
song_qs.save()위의 스크립트를 shell_plus 같은 곳에서 실행해주면 1번을 수행하지 않아도 되는게 맞는건가요?
그리고 ㅠㅠ get_absolute_url 안에 print는 왜 runserver stream에 나오지 않는지 궁금합니다 실질적으로 self.save()도 작동하지 않은 이유와 같을거 같은데요. 원론적으로 하면 좋지 않다는 건 이해하였는데, 아무것도 뜨질 않으니 class based model을 구현 및 디버깅이나 리펙토링 할 때 어떻게 해야할지 모르겠습니다. debugpy를 쓰면 확인이 가능할까요?
1
Song 모델과 관련된 데이터베이스 테이블이 있구요.
slug 필드를 추가하기 전에 데이터베이스 테이블에 이미 Song 레코드가 있었습니다.
migrate 시에 slug 값은 채운 것은, slug 필드를 추가하기 전에 데이터베이스 테이블에 이미 있는 Song 레코드에 대해서 slug 필드값을 채운 것이구요.
Song 모델 내에서 slug 값을 채우고 저장하는 것은, slug 필드를 추가하기 나서 저장되는 Song 레코드에 대해서 slug 필드값을 채우는 것입니다.
강의 코드에서는 Song 모델 인스턴스의 save 메서드를 통해, slug 필드가 비었을 경우 값을 채우고 데이터베이스에 저장하고 있습니다.
질문해주신 코드에서. 쿼리셋에서는 save 메서드를 지원하지 않습니다. save 메서드는 모델 인스턴스에서 지원합니다. 쿼리셋을 순회하면, 매 순회 시마다 모델 인스턴스가 생성되니깐요.
for song in song_qs: song.save() 와 같은 코드를 써보실 수는 있는 데요.
이미 slug 필드가 채워진 Song 레코드에 대해서는 다시 slug 값을 갱신하진 않으니깐요. 모든 Song 레코드에 대해서 순회를 도실 필요는 없으실테구요. 003_populate_song_slugs 마이그레이션에서 수행했듯이 아래처럼 slug 필드 값이 빈 문자열인 Song 만 조회하여 save 하실 수 있습니다.
song_qs = Song.objects.filter(slug="")
for song in song_qs: song.save()
--
그리고, 파이썬 코드 내에서 print 하신 문자열은 그 코드가 수행되었다면, runserver를 띄운 터미널에 아래와 같이 출력됩니다.

파이썬에서는 pdb를 활용한 디버깅도 있지만, 너무 Low 레벨의 디버깅 방법이구요.
print 는 가장 원초적인 디버깅 방법이이구요. 잘 동작합니다. 동작하지 않으시다면 해당 메서드가 호출이 안 된 상황일 가능성이 높지 않을까 싶습니다.
디버깅은 IDE의 디버거 기능을 활용하시는 것이 가장 좋습니다. 파이참이나 VSCode의 디버거 기능으로 브레이크 포인트 걸어서 확인하시는 방법이 널리 사용됩니다.
그리고, get_absolute_url 은 함수로 구현하시면 되구요. @property 장식자를 지정하시면, get_absolute_url 메서드를 호출하는 다른 장고 코드에서 오류를 발생하게 됩니다. @property 장식자는 빼주세요.
0
안녕하세요, 인프런 AI 인턴입니다.
pplkjh2님의 질문에 대하여 비슷한 문제를 해결한 사례들을 찾았습니다. 답변 내용을 확인하시고, 비슷한 상황에서 어떤 접근을 했는지 살펴보시면 도움이 되실 것 같습니다.
질문 핵심 요약:
- slug 필드 추가와 makemigration 과정: SlugField를 모델에 추가하여 자동으로 slug를 생성하고 저장하는 로직이 작성되었습니다. 그리고 makemigrations를 사용하여 데이터베이스에 이 변화를 적용시키려고 하지만, 예상대로 동작하지 않는 부분에서 문제가 발생한 것으로 보입니다.
- get_absolute_url 사용: Detail 페이지의 URL을 생성할 때 자동으로 slug를 생성하고, 해당 slug를 URL에 포함시켜 주소를 생성하는 과정에서 문제가 발생하였습니다. 특히, slug가 비어있을 경우
self.save()를 호출하여 데이터베이스에 slug 값을 저장하려고 시도했으나, 이 과정에서 일정 부분 장애가 발생한 것 같습니다.
이와 관련하여 아래의 질문&답변 링크를 추천드립니다:
유사 질문 링크:
slug 추가시 attribute error - 이 링크에서는 slug 필드 추가 시 발생할 수 있는 attribute error 및 이를 해결하는 방법에 대해 설명하고 있습니다. 비록 직접적인 slugify 작동 문제에 대한 것은 아니지만 slug 필드와 관련된 일반적인 문제 해결 팁이 제공됩니다.
장고에서 song_detail.html을 찾아가는 이유를 모르겠습니다. - 이 링크는 URL 설정 및 이를 통한 Django 템플릿 연결에 대한 문제를 다루고 있습니다. 특히,
get_absolute_url메서드가 어떻게 작동하는지를 이해하는 데 도움이 될 수 있습니다.No post matches the given query - Slug와 관련된 URL 호출 시 발생할 수 있는 404 오류와 그 해결 방안에 대해 설명합니다. get_absolute_url 메서드 내에서의 처리 방식과 유사한 문제 해결 방법이 포함되어 있을 수 있습니다.
추가 설명:
makemigration 분할 이유: Django에서는 모델에 변화가 생길 때마다 마이그레이션 파일을 생성하여 이 변화를 데이터베이스 스키마에 적용합니다. 때때로, 특히 필드 추가 및 인덱스 생성, 다른 복잡한 조작이 한번에 함께 이루어져야 할 때, 복수의 연산을 담은 하나의 마이그레이션 파일을 생성하기도 합니다. 그러나 이 과정을 분리하여 순차적으로 진행하는 이유 중 하나는, 각 단계별로 분명한 확인 절차를 거치며, 특정 단계에서 발생할 수 있는 문제를 개별적으로 해결할 수 있기 때문입니다.
get_absolute_url과 save 호출: Django에서
get_absolute_url메서드는 객체의 상세 뷰로 연결된 URL을 반환합니다. 흔히 모델의 인스턴스가 저장된 후, 해당 인스턴스의 상세 페이지로 리디렉션 하는 등의 용도로 사용됩니다. 이 메서드 내에서self.save()를 호출하는 것은, 해당 인스턴스의 최신 상태(예: 새로 생성/변경된 slug 값)를 데이터베이스에 저장하기 위함입니다. 그러나, 이러한 처리는 대체적으로 모델의save메서드 오버라이딩에서 자동으로 slug를 생성하고 저장하는 것이 일반적인 패턴입니다. slug 필드가 비어있을 경우에만 slugify를 실행하는 로직을 모델의save메서드 안에서 정의하면, 이와 같은 명시적인self.save()호출 없이도 slug가 자동으로 생성되고 저장됩니다.
저는 질문자님의 이해를 돕고자 지식공유자님의 기존 답변을 참고하여 유사한 답변 링크를 추천해드리고 있습니다.
현재 베타 기능으로 답변이 만족스럽지 않을 수 있는 점 양해 부탁드립니다. 🙏
추가적으로 궁금한 점이 있으시면, 이어서 질문해 주세요. 곧 지식공유자께서 답변해 주실 것입니다.
Django의 View나 URL의 네이밍 컨벤션
0
75
1
08-14 FormView 관련 질문
0
90
1
07-01 IPv4AddressIntegerField 질문
0
100
1
14-08 수업 확인 요청 드립니다.
0
109
2
nextjs git 관리?
0
89
1
14-07에서 SESSION_COOKIE_DOMAIN = None 처리 필요.
0
91
2
고민
0
234
3
django-component==0.139 실행 시 오류
0
177
2
django-csp 4.0 migration 관련
0
130
2
01 윈도우 개발환경 설치 문의
0
108
1
강의 자료 문의
0
138
2
선생님 학습 방법 질문이 있습니다.
0
159
2
bulk_update에서 updated_at 필드
0
134
1
정규표현식
0
113
2
선생님 질문 있습니다.
0
85
1
공유자님 이 강의 공부 방법에 대한 질문입니다.
0
193
2
mydjango.py 질문 있습니다.
0
157
3
Django-Components의 0.128 세팅
0
240
3
질문 아님.
0
133
1
mydjango.py 실습 질문있습니다.
0
99
2
pycharm 개발환경 설정 오류
0
196
2
강의 듣다가 유료pycharm에 비해 vscode지원기능이 아쉬워서 확장프로그램 만들었는데 여기 공유해도 될까요?
0
175
1
중단점에 대한 질문 있습니다.
0
141
2
todo / react 붙이는 깃주소를 받고 싶습니다.
0
196
6