




201_classify_text_with_bert_tfhub_Kor.ipynb 오류
안녕하세요?
201_classify_text_with_bert_tfhub_Kor.ipynb 소스 수행 시 아래와 같은 오류가 납니다.
구글 colab gpu에서 돌리고 있습니다. (오류 이미지도 같이 첨부합니다.)
왜 오류가 나는지 답변 부탁 드립니다.
ValueError Traceback (most recent call last)
<ipython-input-17-3b4b1d94b15e> in <cell line: 1>()
----> 1 classifier_model = build_classifier_model()
2 bert_raw_result = classifier_model(tf.constant(text_test))
3
4 print(bert_raw_result)
5 print(tf.sigmoid(bert_raw_result))
7 frames
/usr/local/lib/python3.10/dist-packages/keras/src/backend/common/keras_tensor.py in __array__(self)
59
60 def __array__(self):
---> 61 raise ValueError(
62 "A KerasTensor is symbolic: it's a placeholder for a shape "
63 "an a dtype. It doesn't have any actual numerical value. "
ValueError: Exception encountered when calling layer 'preprocessing' (type KerasLayer).
A KerasTensor is symbolic: it's a placeholder for a shape an a dtype. It doesn't have any actual numerical value. You cannot convert it to a NumPy array.
Call arguments received by layer 'preprocessing' (type KerasLayer):
• inputs=<KerasTensor shape=(None,), dtype=string, sparse=None, name=text>
• training=None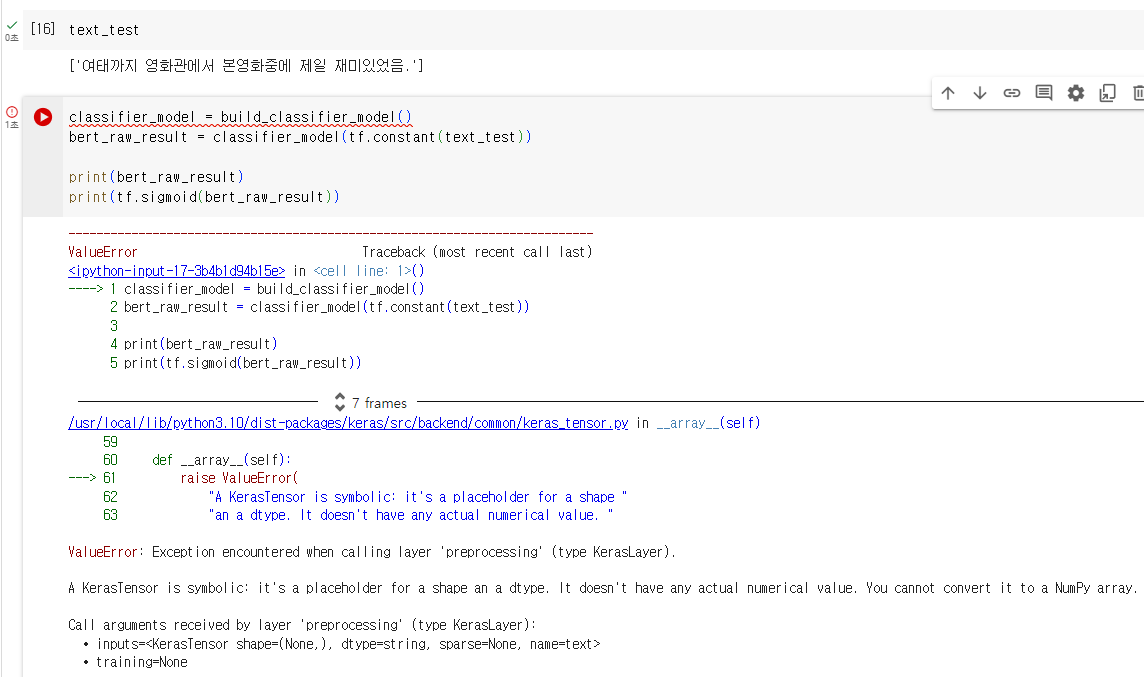
답변 2
1
다음과 같이 수정하시면 됩니다.
(기존)
!pip install -q -U tensorflow-text
!pip install -q tf-models-official
(수정)
!pip install -U "tensorflow-text==2.13.*"
!pip install "tf-models-official==2.13.*"
이 교재는 Google Tutorial의 https://www.tensorflow.org/text/tutorials/classify_text_with_bert 교재를 IMBD 대신 한글 naver movie 데이터로 제가 customizing 한 것인데 원래의 영문 tutorial 도 수정이 되어있네요. github 교재 source도 수정해 놓았습니다. 불편을 드려 죄송합니다.
제가 새롭게 고쳐서 실행해 보니 T4 GPU 기준 6시간 걸리네요. 예전 보다 시간이 훨씬 길어졌는데 아마도 Google 에서 무료 GPU 에 대한 지원을 낮춘 것으로 보입니다.
감사합니다.
트랜스포머 FeedForward 관련 질문
0
105
2
파라미터갯수에대한질문(030_IMDB_movie_reviews)
0
69
1
Transformer 번역기 분석 - Part1 따라치기 질문
0
80
2
Encoder-Decoder 질문 드립니다.
0
82
2
model 코드 부분을 따라하다가 전 값이 이상해서요
0
95
1
서적 추천
0
85
1
NLP와 LLM의 차이점
0
575
2
encoder-decoder model 질문입니다.
1
82
1
구글번역기에 대해서 궁금한점이 있습니다.
0
135
2
로드맵에대해서...
0
128
2
Bag of Word (BOW)와TF-IDF시 대명사인 I의행방
0
106
2
강의 교재 최신화 요청
0
150
4
self-attention에서 Wq, Wk, Wv weight matrix 학습과정 질문드립니다.
0
206
3
코랩 환경 설정할 때 질문이 있습니다.
0
261
1
transformer 훈련 마친 모델 공유 가능할까요?
0
223
2
130_Transformer.ipynb transformer.summary() 에러
0
191
2
강사님 궁금한게 있어 문의 드립니다.
0
140
1
강사님 Tensorflow 실습코드 중 궁금한 점이 있습니다.
0
133
1
패딩과 관련한 질문 드립니다.
0
178
1
Encoder Decoder 부터 Simple Chatbot까지 이상답변
0
228
1
seq2seq 모델
0
336
1
강의 내용중 질문있습니다.
0
206
1
Transformer 번역기 부분에 대해 질문 있습니다.
0
223
1
320_Custom_Sentiment_Analysis_navermovie.ipynb 실행 시 오류 납니다.
0
330
2