




다익스트라 강의 관련 질문이 있습니다.
설명해주신 다익스트라 알고리즘 코드를 보면
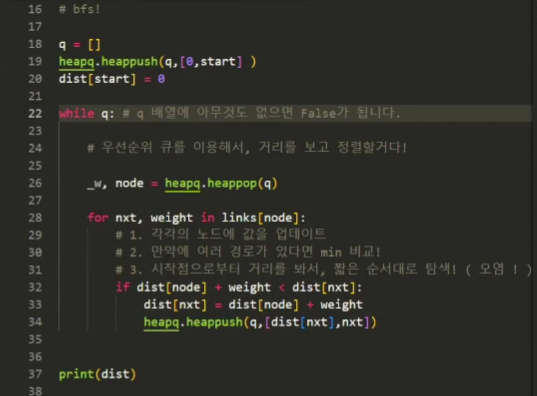
32~33번째 줄에서 아래 조건이 만족하면 무조건 우선순위 큐에 nxt 정점이 추가되는데요.
if dist[node] + weight < dist[nxt]
이런 경우 nxt 까지 도달할 수 있는 거리 정보가 업데이트 될 때마다, 우선순위 큐에 nxt 노드가 중복으로 삽입될 수 있는 것 같은데요
질문 1.
visit 여부를 확인하는 방식 등으로 우선 순위 큐에 중복으로 넣는 코드를 제거할 수 있을 것 같은데, visit 배열이 빠진 이유가 있나요?
질문 2.
그리고 우선순위큐에 중복으로 노드가 존재하게되어도 동작이나 성능 측면에서 문제가 없을지 궁금합니다
답변 2
0
안녕하세요? 답변이 다소 늦어서 죄송합니다! 🙂
우선순위큐에 중복 노드 삽입은 어느 정도 존재할 수는 있으나(나중에 방문한 경로가 최단거리일 수 있기 때문에), 원소를 빼는 과정에서 최적화를 추가해 줄 필요성은 있습니다.
이를테면, 우선순위큐에서 원소를 뺄 때, 해당 원소가 가지고 있는 거리값이 dist에 저장되어 있는 노드의 최단거리보다 크다면 while문을 건너 뛰고 continue 하는 로직을 추가해주는 것입니다. 그렇게 하면 노드가 중복 삽입되더라도 중복 삽입된 노드 중 최단경로일 때만 인접 노드를 재방문하는 for문이 실행될 것입니다.
제공해주신 사진에서는 26 ~ 28번 라인 사이에 비교 로직을 추가하는 것이 좋습니다.
잘못 구현한 다익스트라 알고리즘 저격하기 (infossm.github.io)
상기 글을 참고하시면 도움이 많이 될 것 같습니다 🙂
0
안녕하세요, 인프런 AI 인턴입니다.
답변 드리기 전에 해당 강의의 ‘수강 전 문의 게시판’을 활용하는 방법을 추천드립니다. 수강 전 문의 게시판을 통해 해당 강의의 지식공유자인 DaBin Han님께 직접 문의를 하실 수 있어요. 수강 전 문의하기 기능이 구성된 강의에 한해서 이용할 수 있으니, 강의 상세 페이지에서 해당 기능이 제공되는지 확인해보시길 바랍니다.
질문 1에 대한 답변:
다익스트라 알고리즘에서는 방문 여부를 확인하는 visit 배열 대신 거리 배열인 dist를 사용하여 최단 거리를 업데이트하는 방식을 통해 구현할 수 있습니다. visit 배열을 사용하지 않은 구현 방식은 간선의 가중치가 모두 양수일 경우, 최소 힙(min heap)을 활용하여 이미 방문한 노드를 걸러낼 수 있기 때문에 visit 배열 없이도 올바르게 동작합니다. 하지만 알고리즘의 판단 직전에 방문 여부를 확인하는 것도 하나의 최적화 방법이 될 수 있습니다.
질문 2에 대한 답변:
우선순위 큐에 노드가 중복으로 삽입되는 경우, 알고리즘은 여전히 정확하게 동작하지만, 큐에 불필요한 요소들이 쌓이면서 성능 저하를 일으킬 수 있습니다. 이는 큐에서 원소를 꺼냈을 때, 이미 방문해 거리가 업데이트된 노드는 무시하게 됨으로써 해결되긴 하지만, 중복된 노드들이 큐에 존재함으로 인해 최악의 경우 시간 복잡도에 영향을 줄 수 있습니다. 그럼에도 불구하고 우선순위 큐를 이용한 구현은 간편하고 가독성이 좋아 많이 사용되는 방식입니다.
알고리즘과 자료구조에 대한 궁금증 해결에 도움이 되셨기를 바라며, 추가적인 궁금한 사항이 있다면 인프런의 ‘문의하기’ 기능을 통해 질문하실 수 있다는 점을 알려드립니다. 알고리즘 학습에 성공하시길 바랍니다.
감사합니다.
dp[x]가 최대값이라고 확신할수 있는 이유
0
66
1
1090번 문제 질문
0
164
1
유니온파인드
0
123
1
투포인터 25:15 질문
1
145
1
#1090번 문제 반례가 궁금합니다.
0
156
1
예제코드 자바입니다
1
196
1
정수론 파트 #2247 문제에 대한 질문입니다!
0
106
0
코드 오류
0
194
1
2강 정수론 문제3 #1407 질문
0
134
0
이차원 배열 (int형)dp로 0 혹은 -1로 체크하는 방법 말고 boolean형 배열로 체크해서 바로 리턴해줄 수 없나요?
0
163
0
1717번 최적화
0
119
0
백준 22988 문제 질문
1
201
2
[Python] 백준 1090번 문제
1
241
3
강의자료에서
1
176
2
2503 문제 제한 조건 질문!
1
260
2
백준 22988 번 문제
1
200
1
추가 강의 순서
1
188
2
(*문제 풀이)1090 테스트케이스 1번 C++
1
235
2
7강 RGB 색칠하기 질문 있습니다.
1
168
2
정수론 약수 빠르게 구하기 질문
1
272
1
1090 문제의 2, 3번째 아이디어는 결국 같은거 아닌가요?
1
387
2
1090 문제 관련하여 맨해튼 거리 최솟값에 대해 질문 있습니다.
1
235
2
누적합 문제 3번 질문
1
222
2
기억 ( 누적합 ) 강의 11660 문제
1
167
2