Công cụ trích xuất dữ liệu web thú vị và hữu ích,
Tự tay xử lý và thu thập nhiều dữ liệu khác nhau!
📣 Sau đây là thông tin.
Các trang web trích xuất nội dung được đề cập trong khóa học này, chẳng hạn như Coupang, Naver Webtoon và Tistory, đã liên tục được cập nhật và sắp xếp lại kể từ khi khóa học được ghi hình. Hơn nữa, một số tính năng có thể không còn khả dụng do các phiên bản Selenium đã được nâng cấp. Do đó, nhiều bài tập có thể khó theo dõi. Học viên mới nên lưu ý điều này khi học. Thay vì cố gắng sao chép mọi bài tập được trình bày trong khóa học, chúng tôi khuyên bạn nên sử dụng khóa học để hiểu rõ hơn cách tiếp cận trang web tại thời điểm đó. Chúng tôi chân thành xin lỗi vì bất kỳ sự bất tiện nào.
Bạn có nhớ câu chuyện về con sói và bảy chú dê con không?
Trong khi mẹ của chúng đi vắng, bảy chú dê con bị bỏ lại, nhưng một con sói xấu xa đã đến tìm chúng.
"Mẹ ơi, mở cửa đi."
Nhưng một chú dê con từ chối mở cửa và nói rằng: "Giọng mẹ tôi không đáng sợ đến thế!"
Con sói lại quay trở lại, lần này với giọng nói rất hay
"Mẹ ơi, mẹ mở cửa được không?"
Một chú dê con hỏi,
"Hãy đưa tay ra"
Ngay sau đó, tôi nhìn thấy bộ lông đen và móng vuốt sắc nhọn ở bàn chân.
"Bàn tay mẹ tôi rất trắng," anh nói mà không mở cửa.
Nhìn thấy bàn chân sói xuất hiện trở lại phủ đầy bột trắng,
Lần này, lũ dê bị lừa mở cửa và phải chịu thất bại thảm hại. (Tôi sẽ không tiết lộ kết thúc đâu 😆😆)
Vậy là con sói đã thực hiện ba lần cố gắng đột nhập vào nhà của con dê.
1. Lời nói dối về việc làm mẹ
2. Nói dối về việc làm mẹ + giọng nói hay
3. Nói dối về việc làm mẹ + giọng nói hay + chân phủ đầy bột trắng
Cuối cùng, ngôi nhà đã phá được lỗ hổng ở lần thử thứ ba.
Thu thập dữ liệu web?
Phần giới thiệu khá dài, nhưng việc thu thập dữ liệu web đòi hỏi chính quy trình này. Nó giống như một trận chiến giữa giáo và khiên. Mặc dù bất kỳ giáo nào cũng có thể dùng làm khiên đơn giản, nhưng để xuyên thủng một tấm khiên chắc chắn, bạn cần một giáo sắc hơn, chính xác hơn và mạnh hơn.
Nhưng trong quá trình thu thập dữ liệu web, vai trò của dê và sói thực sự bị đảo ngược một chút.
Chúng ta là chú sói con hiền lành, và máy chủ mục tiêu là một con dê mẹ to lớn, vạm vỡ, có sừng. Chúng ta phải chinh phục máy chủ đó bằng cách nào đó.
Có một số cách tiếp cận vấn đề này và trong bài giảng của mình, tôi sẽ giải thích từng chiến lược của loài sói ở trên theo thứ tự, từng cái một.
À, nhân tiện, web scraping và web crawling có một chút khác biệt.
Thu thập dữ liệu web là,
Người lớn tuổi (kể cả tôi) có thể biết, nhưng hồi xưa có một chương trình mang tên "Cùng đọc sách, sách, sách". Điểm nhấn là có một kệ sách chất đầy sách, bên cạnh là một chiếc xe đẩy, cho khách khoảng một phút để thu thập càng nhiều sách càng tốt. Nếu họ thu thập được càng nhiều sách càng tốt, tất cả sẽ là của họ. (Tôi sẽ tạm gác chuyện "sách vàng" sang một bên nhé ^^)
Bạn sẽ làm gì nếu bạn là khách vào thời điểm này?
Có lẽ họ sẽ cố gắng đưa hết sách vào đó càng nhanh càng tốt mà không cần cân nhắc gì thêm. Bạn có thể coi đây là hành vi thu thập dữ liệu trên web.
Ngược lại, việc thu thập thông tin trên web liên quan đến việc giáo viên đưa cho bạn một tờ giấy trắng vào ngày trước kỳ thi và yêu cầu bạn viết bất cứ điều gì bạn muốn. Sau đó, trong giờ thi, bạn chỉ cần mở tờ giấy đó ra và làm bài.
Vậy nên, có lẽ bạn sẽ viết ra mọi thứ đã học trên lớp, chẳng hạn như các khái niệm quan trọng, công thức khó, hoặc từ vựng tiếng Anh, theo một định dạng dễ tham khảo. Đây chính là web scraping. Nó khác biệt, phải không?
Nói cách khác, thu thập dữ liệu web là hành động trích xuất dữ liệu tôi muốn từ một trang web và xử lý nó thành định dạng tôi muốn .
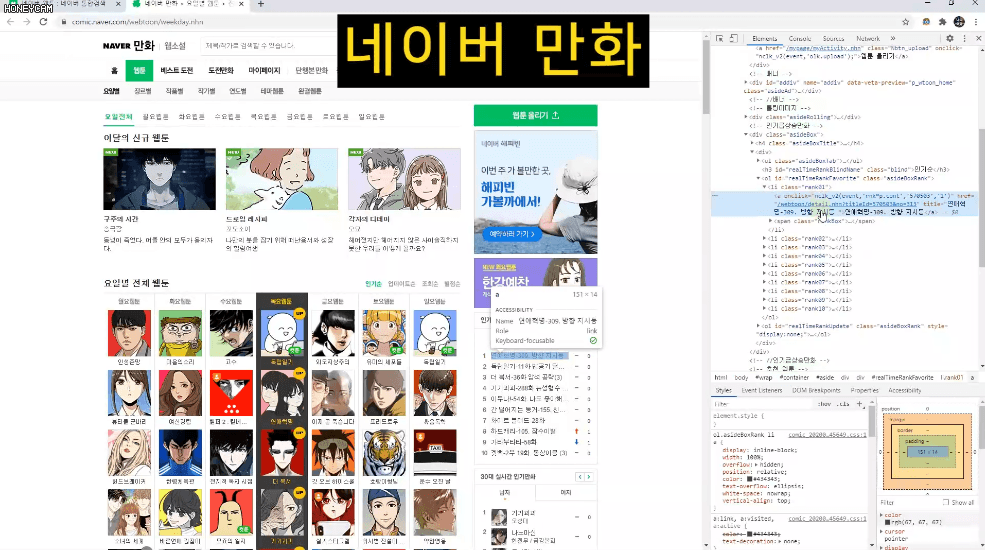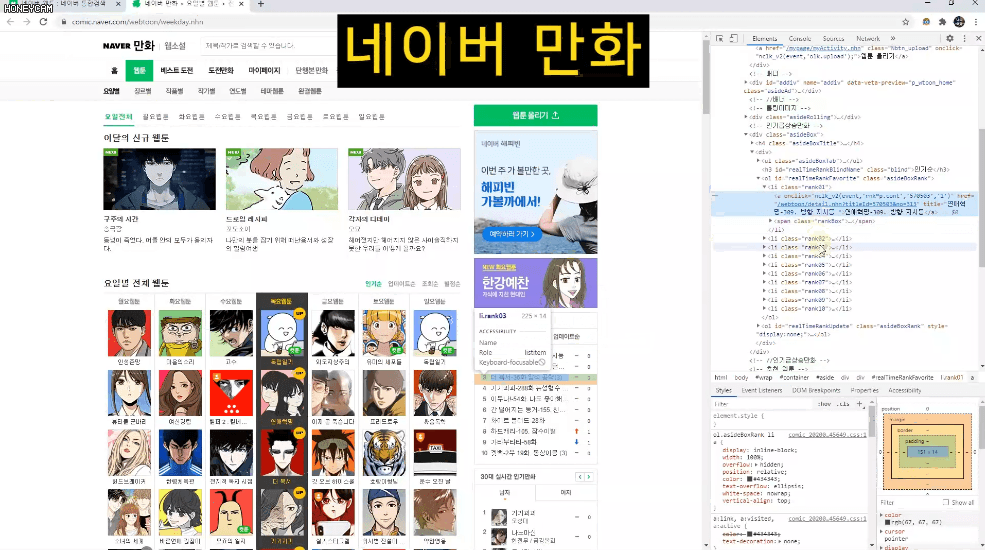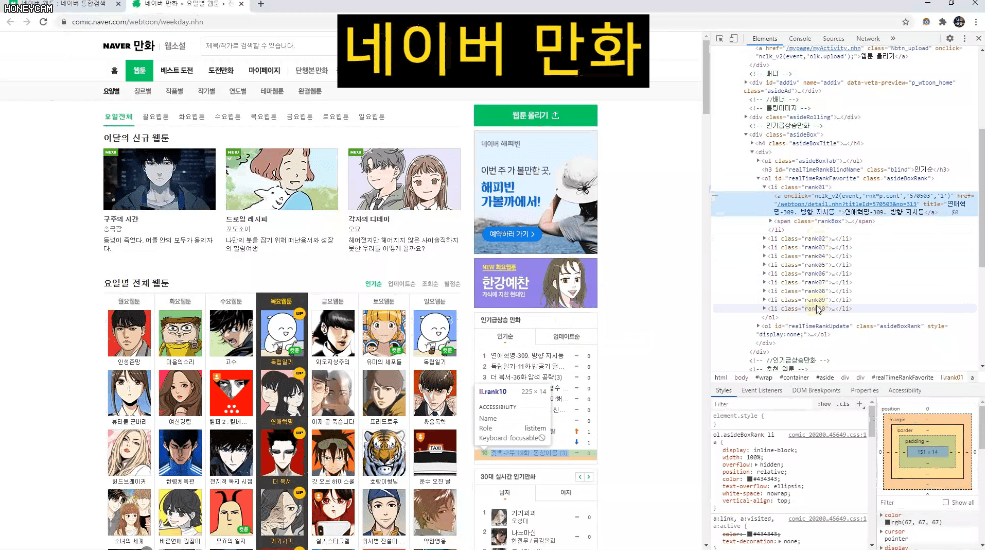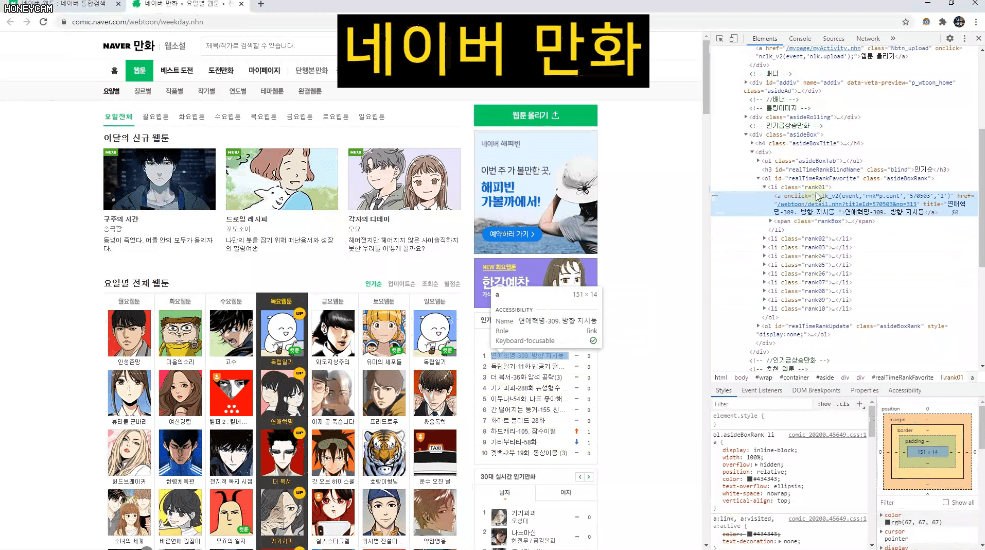
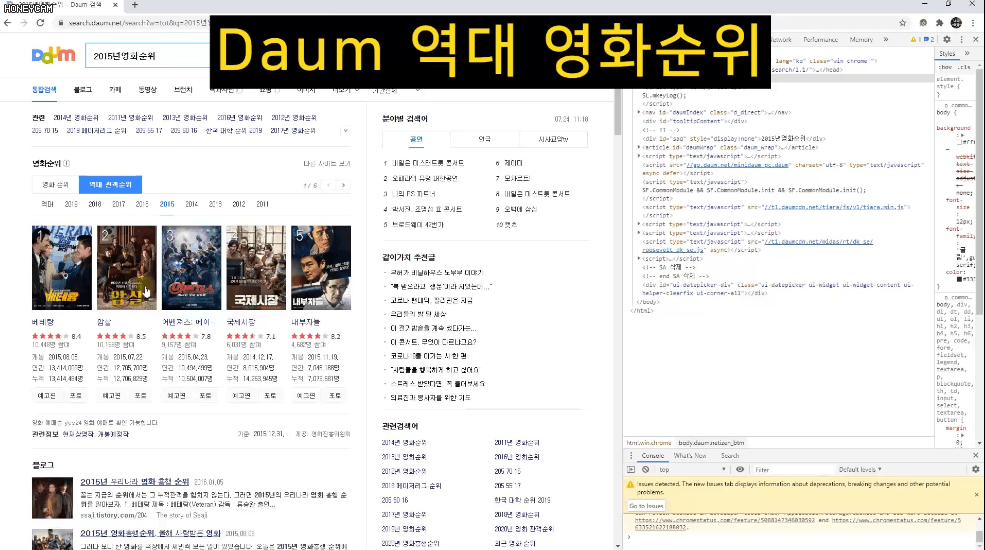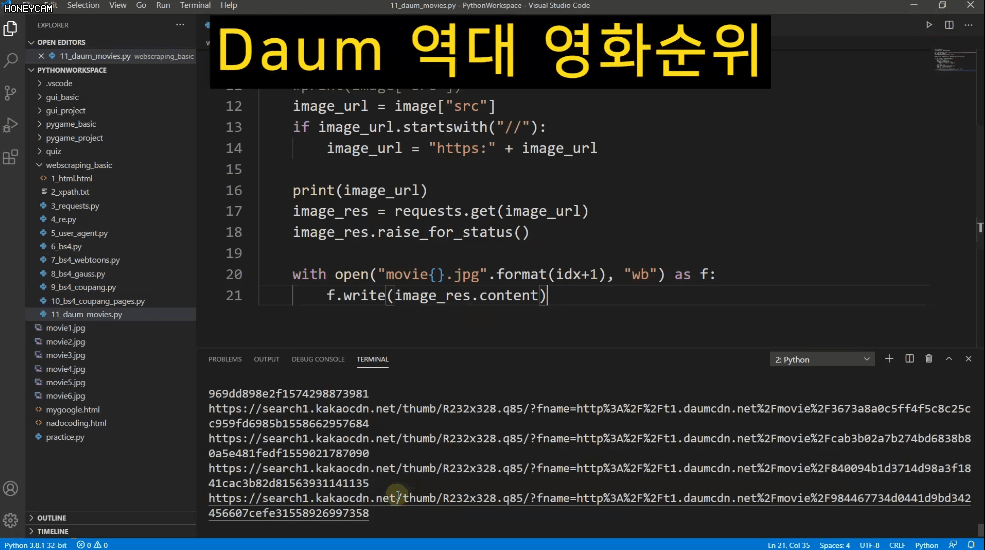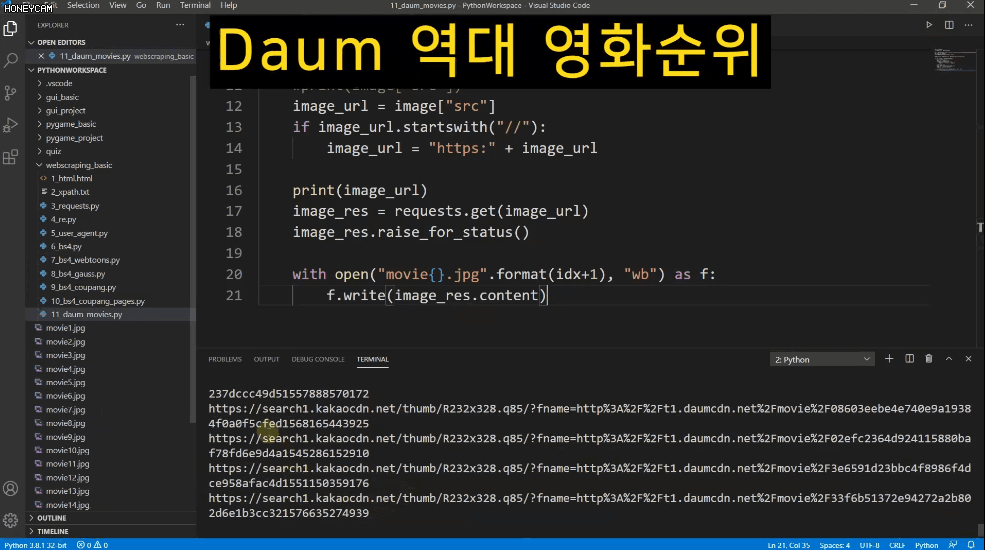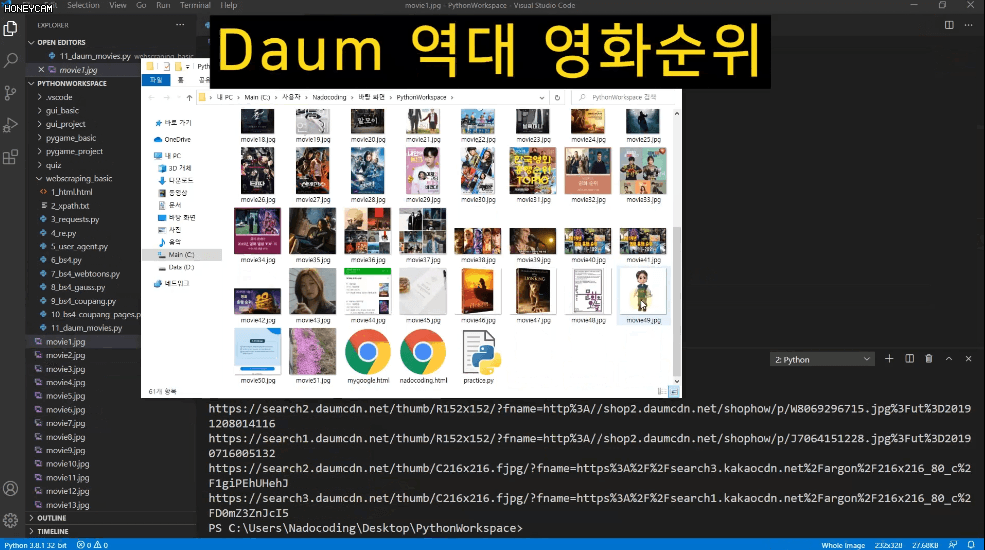
Ví dụ, lấy tiêu đề của tất cả truyện tranh trên trang web Naver hoặc bảng xếp hạng thời gian thực của Top 1-10,
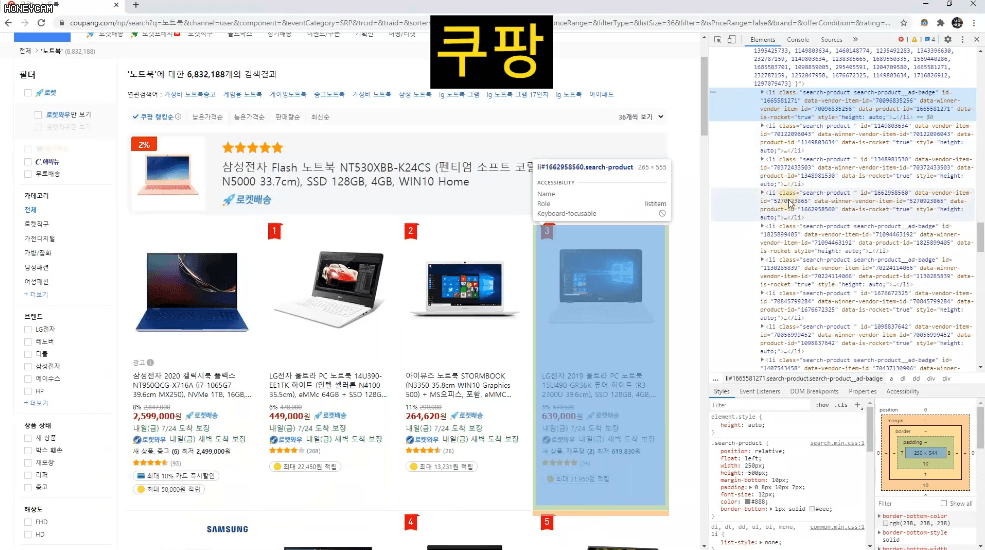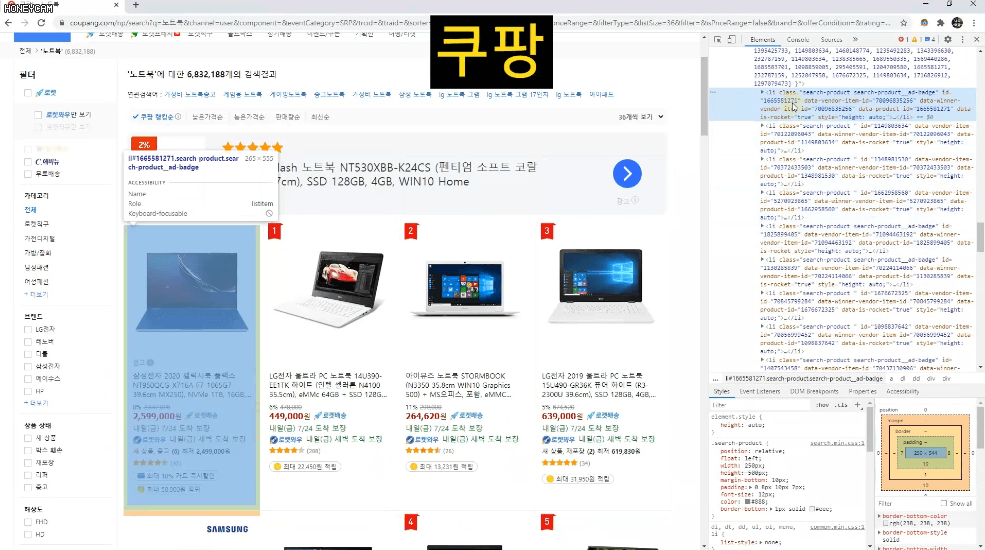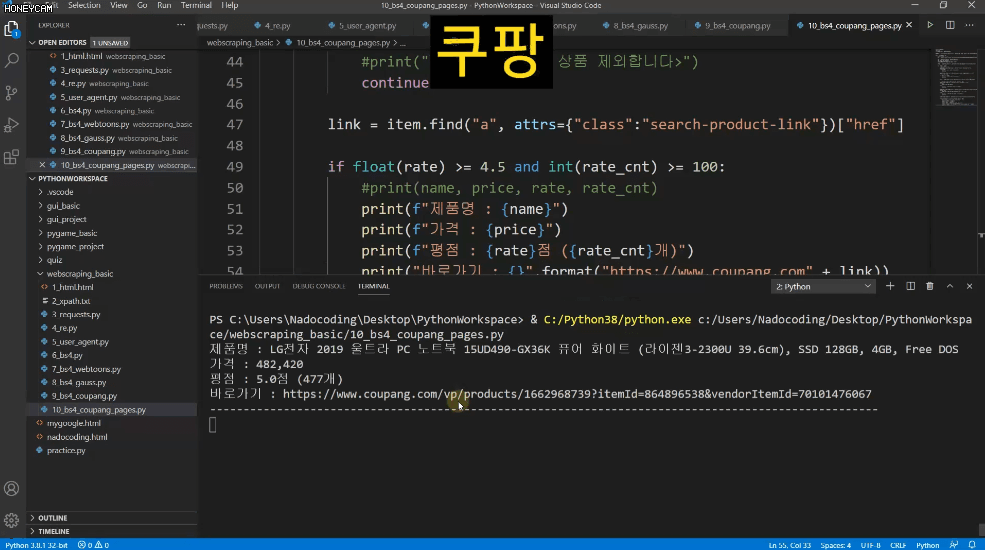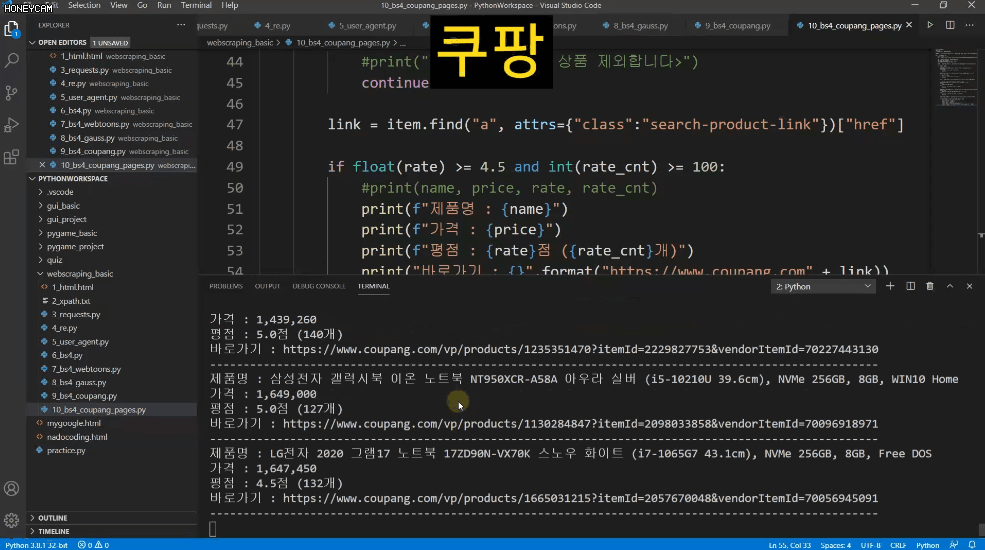
Ví dụ, trong một trung tâm mua sắm như Coupang, chỉ những sản phẩm đáp ứng chính xác yêu cầu của tôi mới được đưa vào thông qua liên kết.
Trong ví dụ
- Trong 1-5 trang đầu
- Có hơn 100 đánh giá
- Nếu xếp hạng trên 4,5 điểm
- Không bao gồm các sản phẩm của Apple
- Không bao gồm các sản phẩm quảng cáo
Chúng ta hãy thực hành cách lấy danh sách nhé.
(Tôi không nói là tôi ghét Apple hay gì cả, chỉ là để luyện tập thôi 😊😊)
Chúng ta cũng hãy thực hành tải hình ảnh nhé.
Tôi là một fan cuồng phim ảnh, nhưng tôi gặp khó khăn trong việc quyết định nên xem phim nào. Vì vậy, tôi đã tải xuống 25 hình ảnh áp phích phim của năm bộ phim được xem nhiều nhất trong năm năm qua và tôi sẽ chọn bất kỳ hình ảnh nào trong số đó. Việc lưu từng hình ảnh riêng lẻ sẽ mất rất nhiều thời gian và công sức, nhưng với công nghệ scraping, tôi có thể lưu tệp chỉ với vài dòng mã, thậm chí còn đặt tên tệp tùy chỉnh.
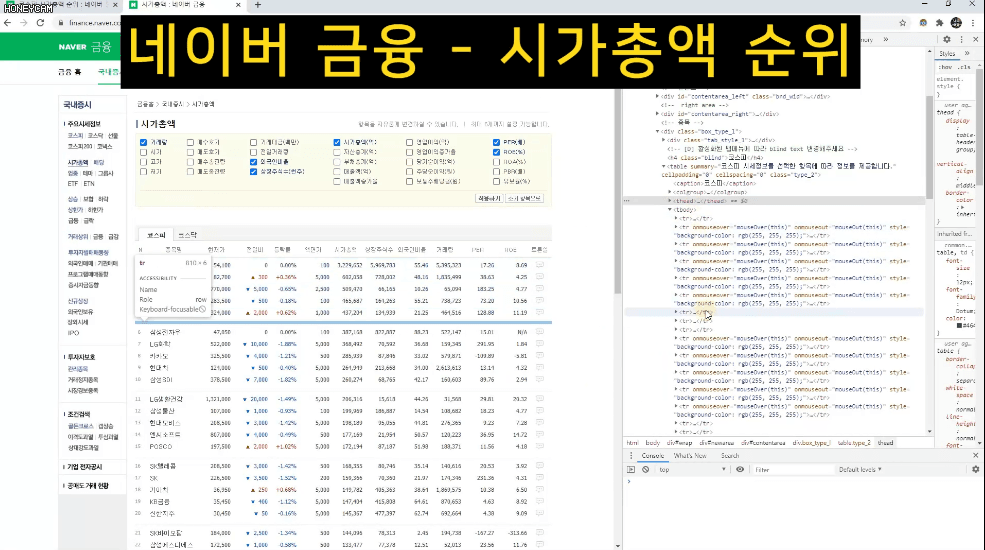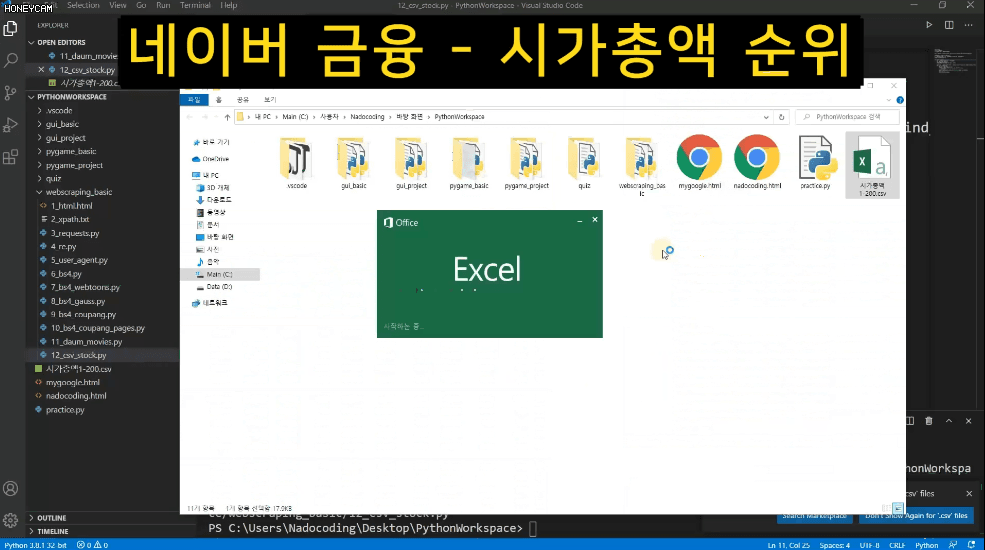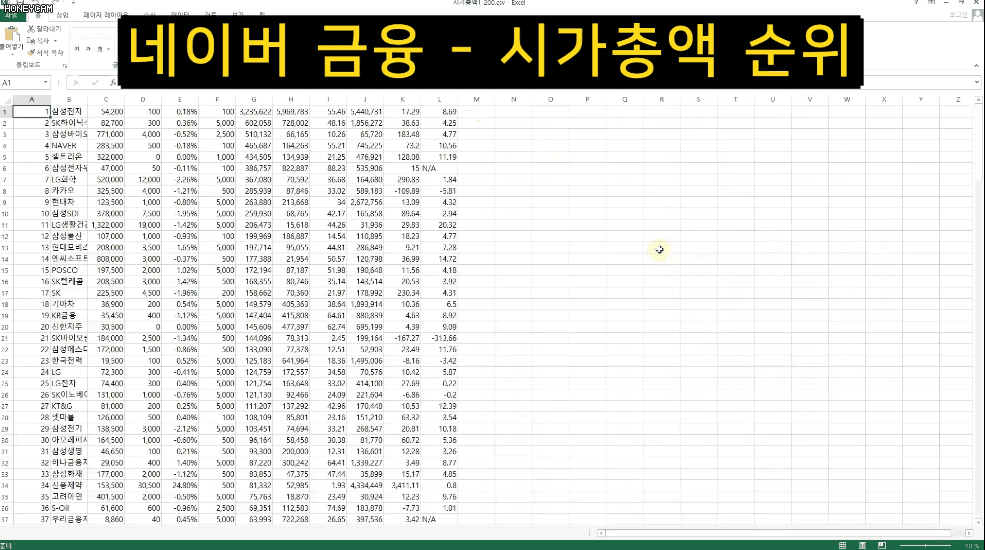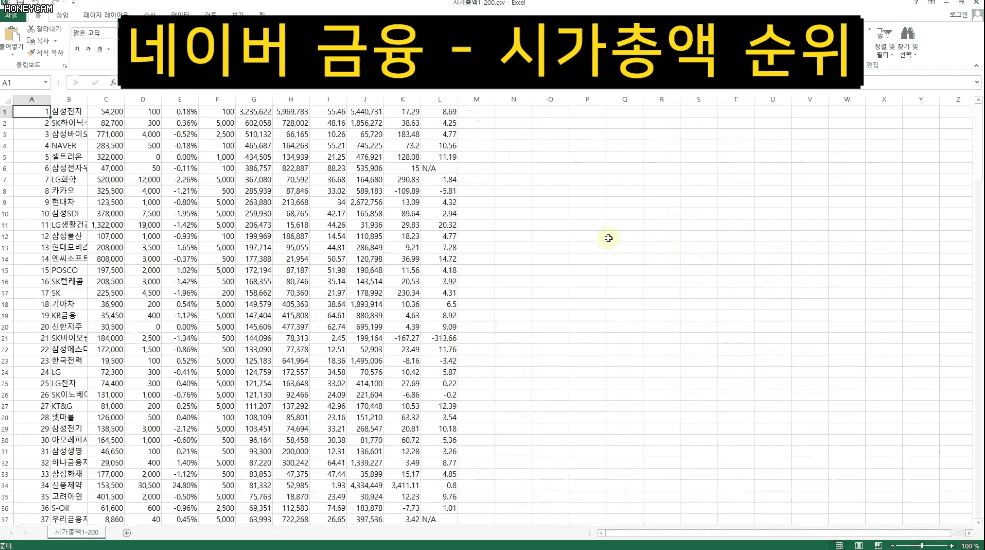
Và đôi khi, sau khi nhập một số dữ liệu, bạn sẽ cần quản lý chúng trong Excel hoặc thực hiện thêm các xử lý khác. Trong những trường hợp đó, bạn chỉ cần tạo tệp CSV và mở trực tiếp trong Excel. Chúng ta sẽ thực hành lấy tất cả thông tin xếp hạng vốn hóa thị trường KOSPI từ Naver Finance.
Tuy nhiên, các trang web này có thể không hoàn toàn hài lòng với việc bot tự động đánh cắp thông tin. Chúng không chỉ có thể sử dụng thông tin mà không được phép, mà việc yêu cầu trang lặp lại còn có thể gây áp lực đáng kể lên máy chủ. Do đó, máy chủ sử dụng nhiều biện pháp phòng thủ khác nhau, chẳng hạn như từ chối truy cập vào các trang hoặc chặn truy cập.
Nhưng như thường lệ, chúng tôi sẽ tìm ra cách.
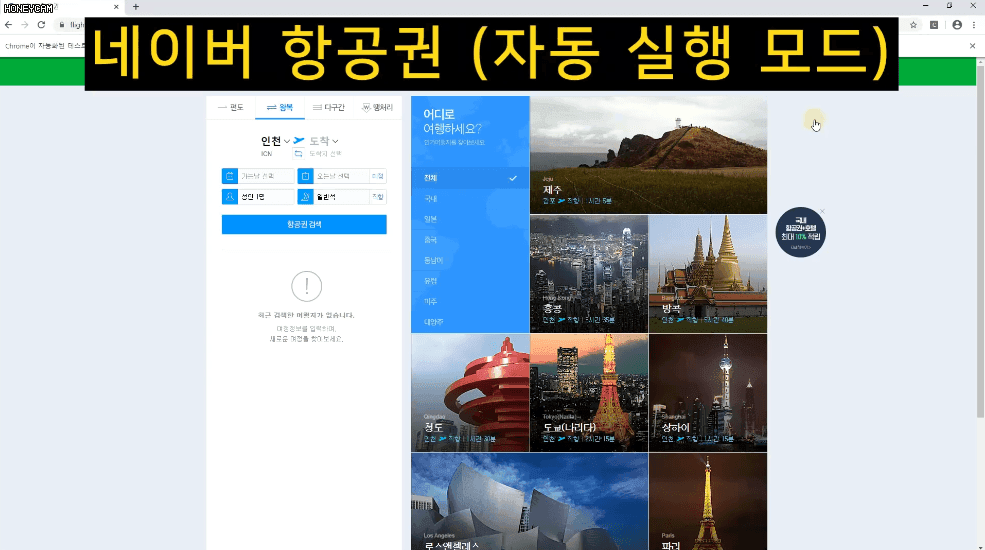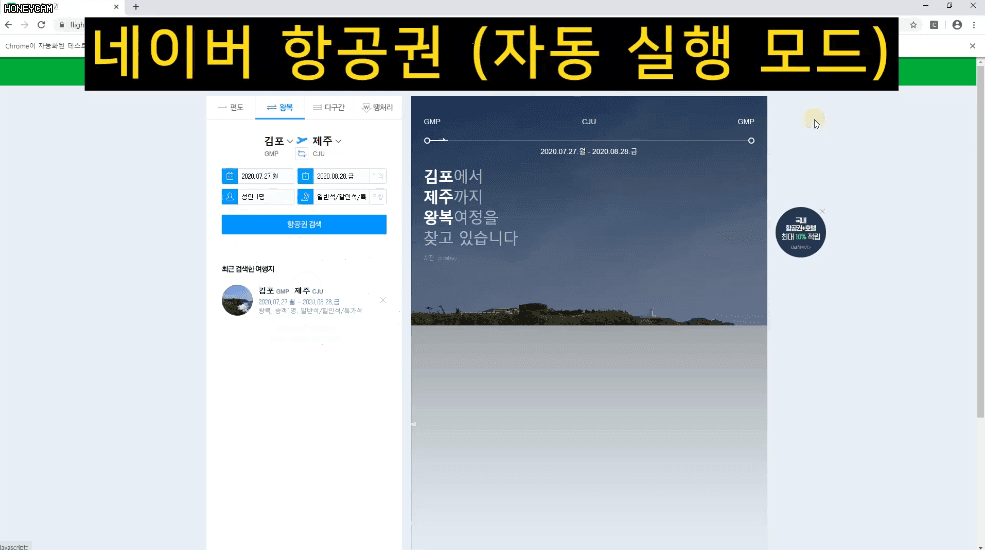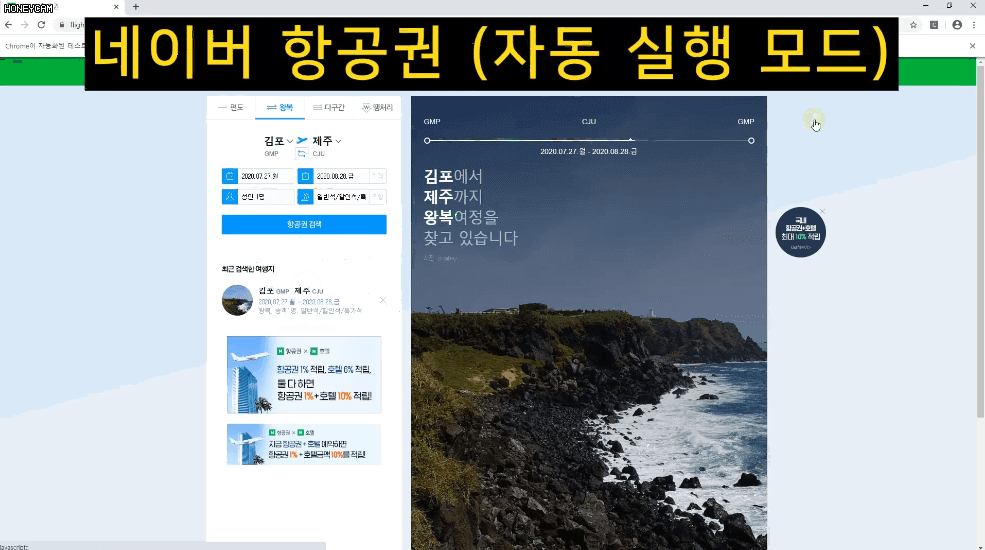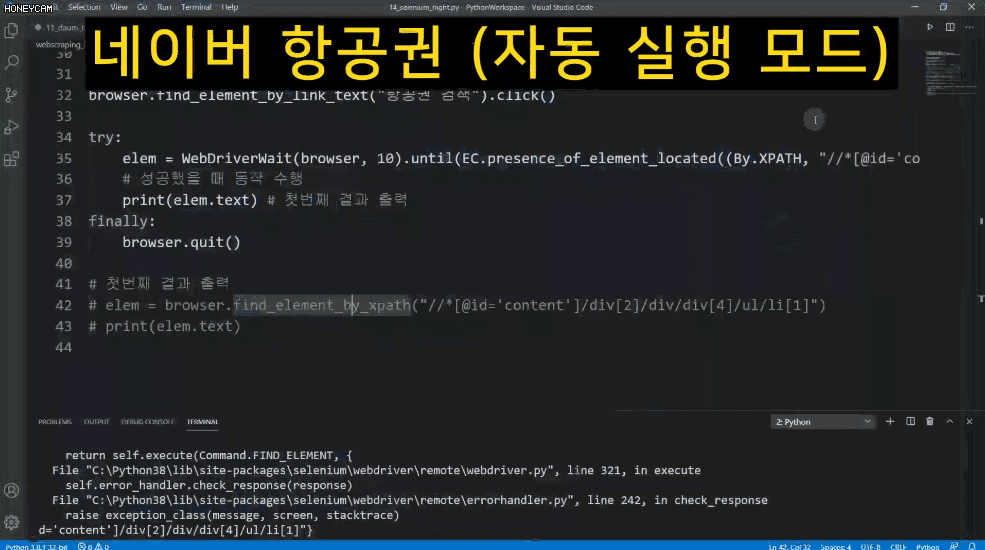
Đôi khi, bạn có thể cần đăng nhập hoặc thực hiện một số thao tác nhất định trên trang web để truy xuất dữ liệu mong muốn. Đối với các trang web di chuyển động, bạn có thể sử dụng Selenium, một nền tảng tự động kiểm thử web, để tự động điều khiển trình duyệt. Khi các phương pháp trước đây không hiệu quả, việc sử dụng Selenium thường sẽ giải quyết được vấn đề.
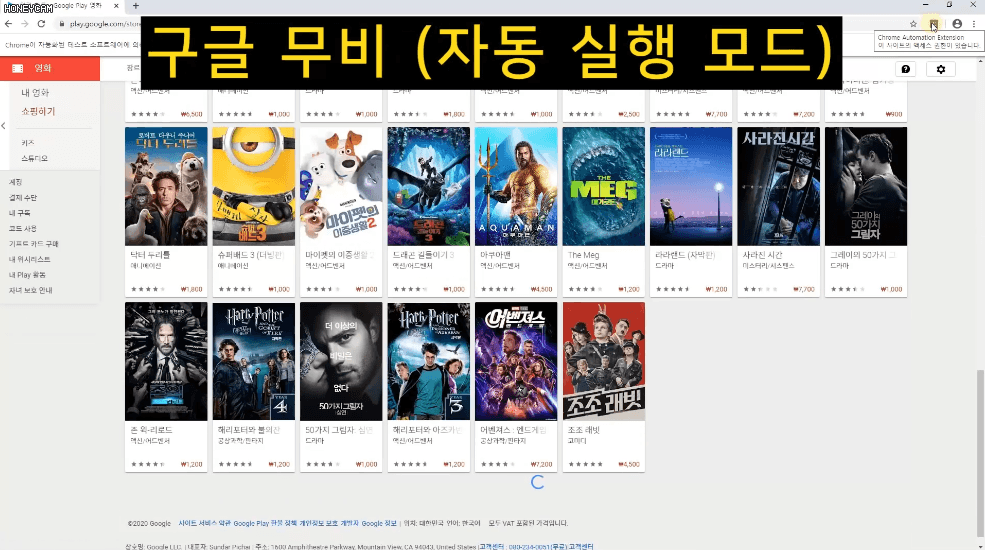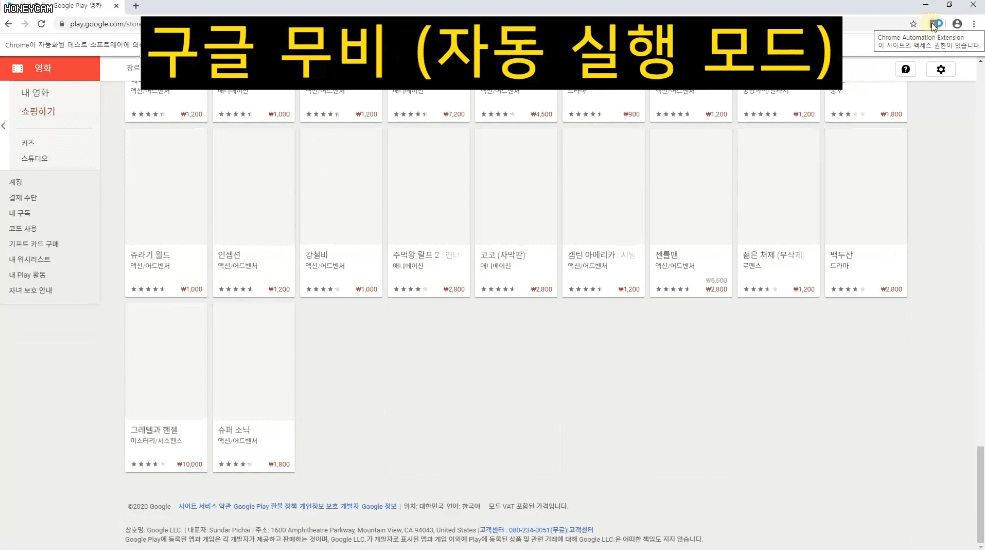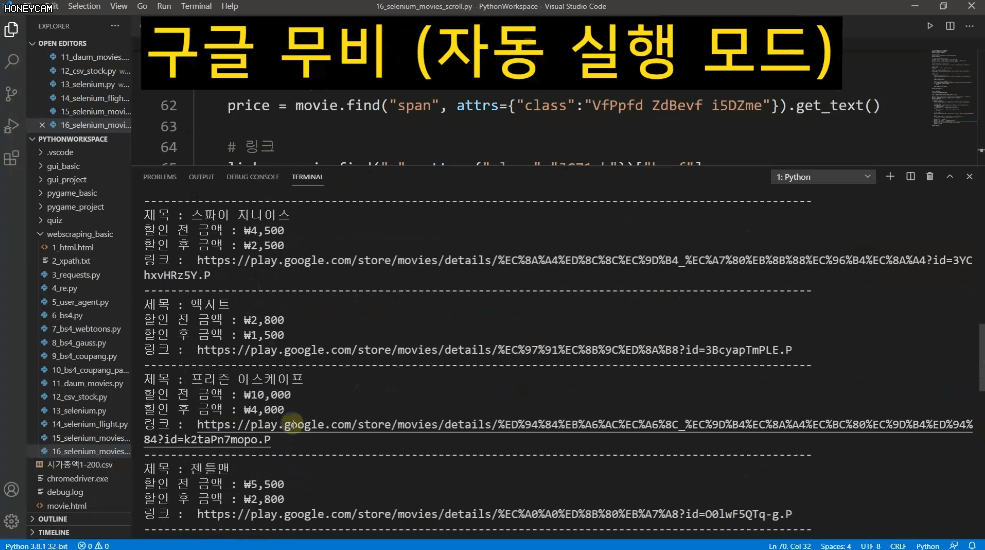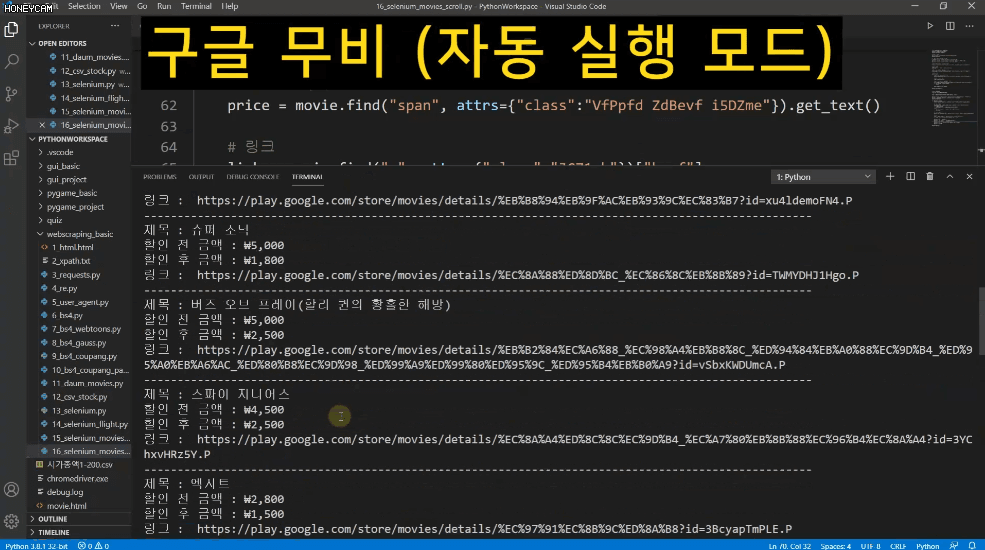
Ví dụ, tôi muốn lấy thông tin về những bộ phim hiện đang được bán trong bảng xếp hạng phim phổ biến trên trang Google Phim, nhưng ở đây, người dùng phải cuộn xuống để lấy danh sách tiếp theo.
Hoặc khi tôi nhập lịch trình mong muốn trên Naver Airline Ticket và nhấp vào nút tìm kiếm chuyến bay, phải mất một thời gian dài để tải danh sách trước khi nó xuất hiện.
Ngay cả khi sử dụng Selenium, vẫn cần một cách tiếp cận tinh tế hơn để giảm thiểu lỗi trong những lĩnh vực này. Tất nhiên, tôi sẽ đề cập đến tất cả những điều này trong bài giảng.
Việc học cách thu thập dữ liệu web đòi hỏi một số kiến thức nền tảng. Vì hiểu biết cơ bản về web là điều cần thiết, chúng ta sẽ tìm hiểu sơ lược về HTML và XPath. Vì chúng ta sẽ sử dụng Chrome (Google Chrome), chúng ta cũng sẽ tìm hiểu cách sử dụng Chrome và các công cụ dành cho nhà phát triển. Biểu thức chính quy có thể cần thiết trong quá trình thu thập dữ liệu, vì vậy chúng ta sẽ chỉ đề cập sơ qua về chúng. Điều này có thể khiến phần giải thích lý thuyết hơi dài dòng và nhàm chán, nhưng sau một thời gian, chúng ta sẽ được thực hành trên nhiều trang web khác nhau, vì vậy hãy kiên nhẫn và theo dõi nhé.

Với quá nhiều nội dung cần học, bạn có thể gặp khó khăn trong việc theo dõi tất cả, vì vậy hãy dành chút thời gian để kết thúc bài học. Không giống như các chủ đề thực hành trước đó, kỹ thuật trích xuất dữ liệu web (web scraping) sử dụng một kỹ thuật nhắm mục tiêu đến các trang web do người khác tạo ra, vì vậy tôi sẽ nhắc lại một số điểm quan trọng cần lưu ý. Nếu bạn đang vội hoặc chỉ muốn nắm bắt ý chính, chỉ riêng phần này cũng đủ để bạn hiểu tổng quan về khóa học.
Tất nhiên, lần này tôi cũng sẽ cho bạn một bài kiểm tra .
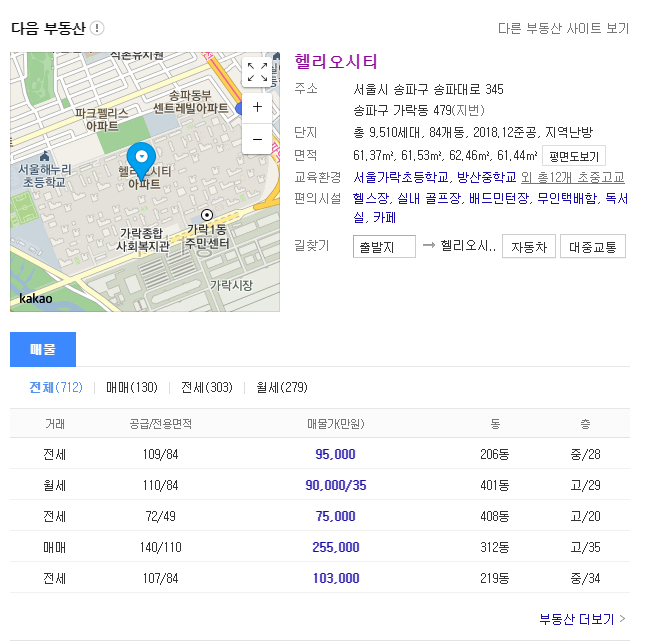
Hãy dành thời gian tự mình thu thập thông tin kết quả tìm kiếm từ các danh sách bất động sản sau đây.
Cuối cùng, chúng ta sẽ cùng thực hiện một dự án . Chủ đề của dự án là "Trợ lý ảo của tôi".
Tôi sẽ tạo một chương trình giúp tôi dễ dàng thức dậy mỗi sáng, xem thời tiết, đọc tin tức chính và tin tức công nghệ thông tin. Nhân tiện, tôi cũng sẽ cố gắng cập nhật các đoạn hội thoại tiếng Anh mới mỗi ngày cho chương trình "1 tiếng Anh mỗi ngày". Chỉ cần một cú nhấp chuột, tất cả thông tin này sẽ có sẵn theo định dạng tôi cần.
Chắc hẳn rất thoải mái phải không? ^^
Nhấp vào liên kết sẽ đưa bạn trực tiếp đến bài viết. Mặc dù chủ đề này không được đề cập, bạn vẫn có thể dễ dàng truy cập thông tin mỗi sáng bằng cách gửi dữ liệu thu thập được ở trên qua email hoặc KakaoTalk.
Nếu bạn đã học những kiến thức cơ bản về Python và muốn nâng cao kỹ năng của mình, hãy học cách thu thập dữ liệu web ngay bây giờ.
Chỉ cần một video này là đủ.
Thêm vào đó, Nadocoding là “miễn phí”.
Được thiết kế bởi freepik
https://www.freepik.com





































![[Làm mới] Bootcamp Học máy Python cho người mới bắt đầu (Dễ dàng! Giải quyết bài toán Kaggle thực tế và tổng hợp) [Phân tích/Khoa học Dữ liệu Part2]Hình thu nhỏ khóa học](https://cdn.inflearn.com/public/courses/327464/cover/55c4db7b-7764-43cc-ac75-d9e8d08098f1/327464-eng.png?w=420)

