






Phân tích thông tin khu thương mại đã trở nên chi tiết hơn nhiều.
Sau khi đổi mới Chương 1 , các Chương 2 đến 4 đã được đổi mới. Tất cả các video và mã nguồn đã được viết lại.
<Trước khi gia hạn>

<Sau khi gia hạn>

Chương 2 29 phút => 167 phút
Chương 3 37 phút => 101 phút
Chương 4 91 phút => 113 phút
Chúng tôi đã bổ sung nội dung và giải thích chi tiết hơn nhiều dựa trên những câu hỏi và phản hồi có giá trị mà chúng tôi nhận được trong năm qua.
Ngoài ra, nó còn cung cấp các file thực hành và file kết quả cũng như liên kết để thực hành trực tiếp trên Google Colaboratory.
<Chương 2 Học thống kê kỹ thuật với thông tin khu thương mại>
Trực quan hóa các giá trị còn thiếu đa dạng hơn thông qua thiếu.
Ngoài ra, chúng tôi xem xét mức sử dụng bộ nhớ thay đổi như thế nào khi xóa các giá trị bị thiếu và thảo luận các cách để giảm mức sử dụng bộ nhớ.
Phân tích các nhà hàng riêng biệt và phân tích các giả thuyết về việc liệu có nhiều học viện tuyển sinh ở Daechi-dong và Mok-dong hay không đã được thêm vào .
Ngoài ra, số liệu thống kê mô tả đã được bổ sung đáng kể .
Khi tổng hợp dữ liệu số và phân loại thông qua mô tả, quy trình tính toán ý nghĩa của từng giá trị và giá trị riêng lẻ đã được thêm vào.
Thông tin về việc thực hiện phân tích tương quan bằng cách tính hệ số tương quan và vẽ đường hồi quy cũng đã được thêm vào.
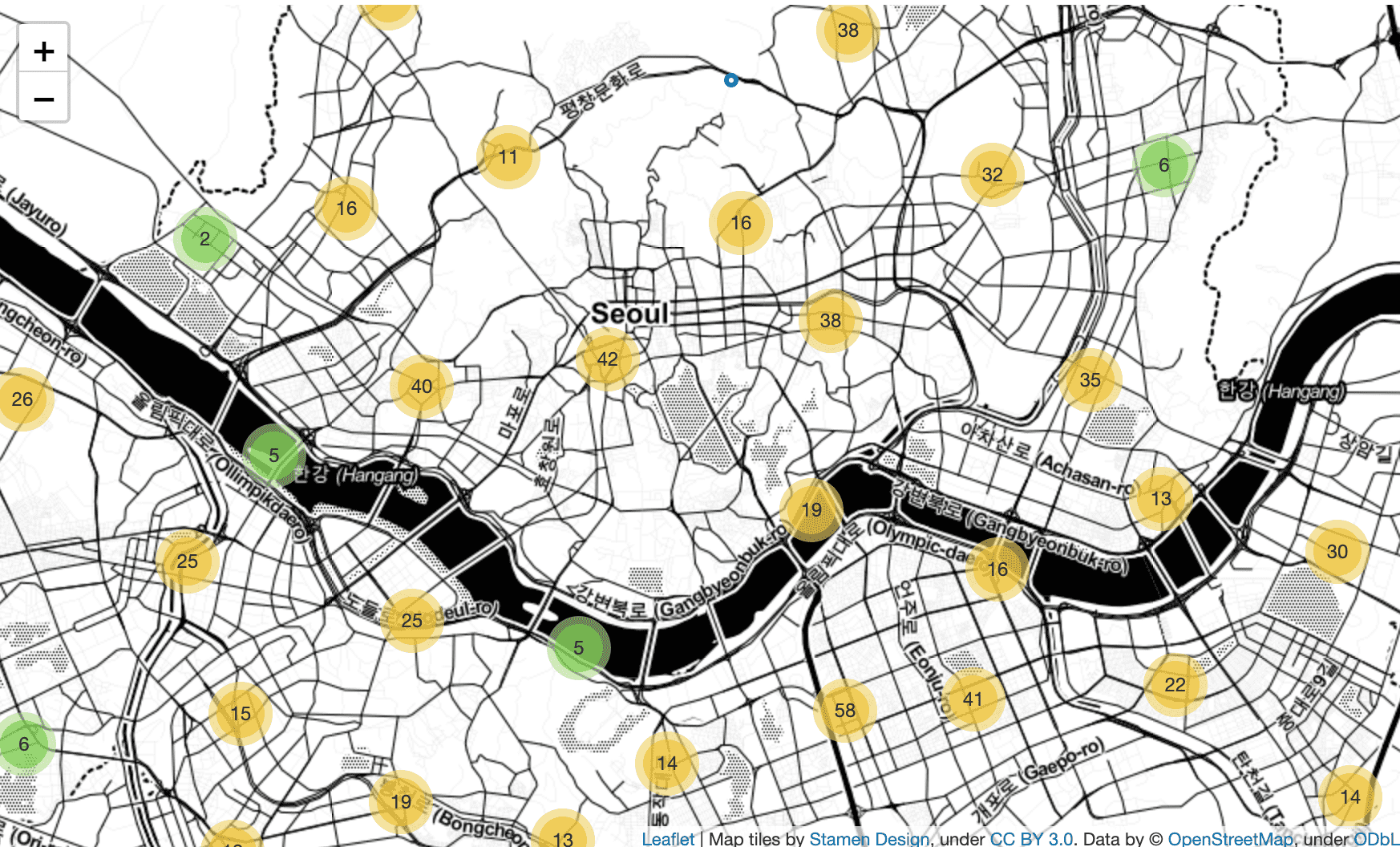
<Chương 3 Phân tích mở cửa nhượng quyền>
Chúng tôi trực quan hóa các biến khác nhau và trình bày chi tiết hơn cách trực quan hóa hai biến số thông qua Jointplot .
Ngoài CircleMarker của Folium, mật độ cửa hàng theo vị trí được thể hiện bằng MarkerCluster và Heatmap .
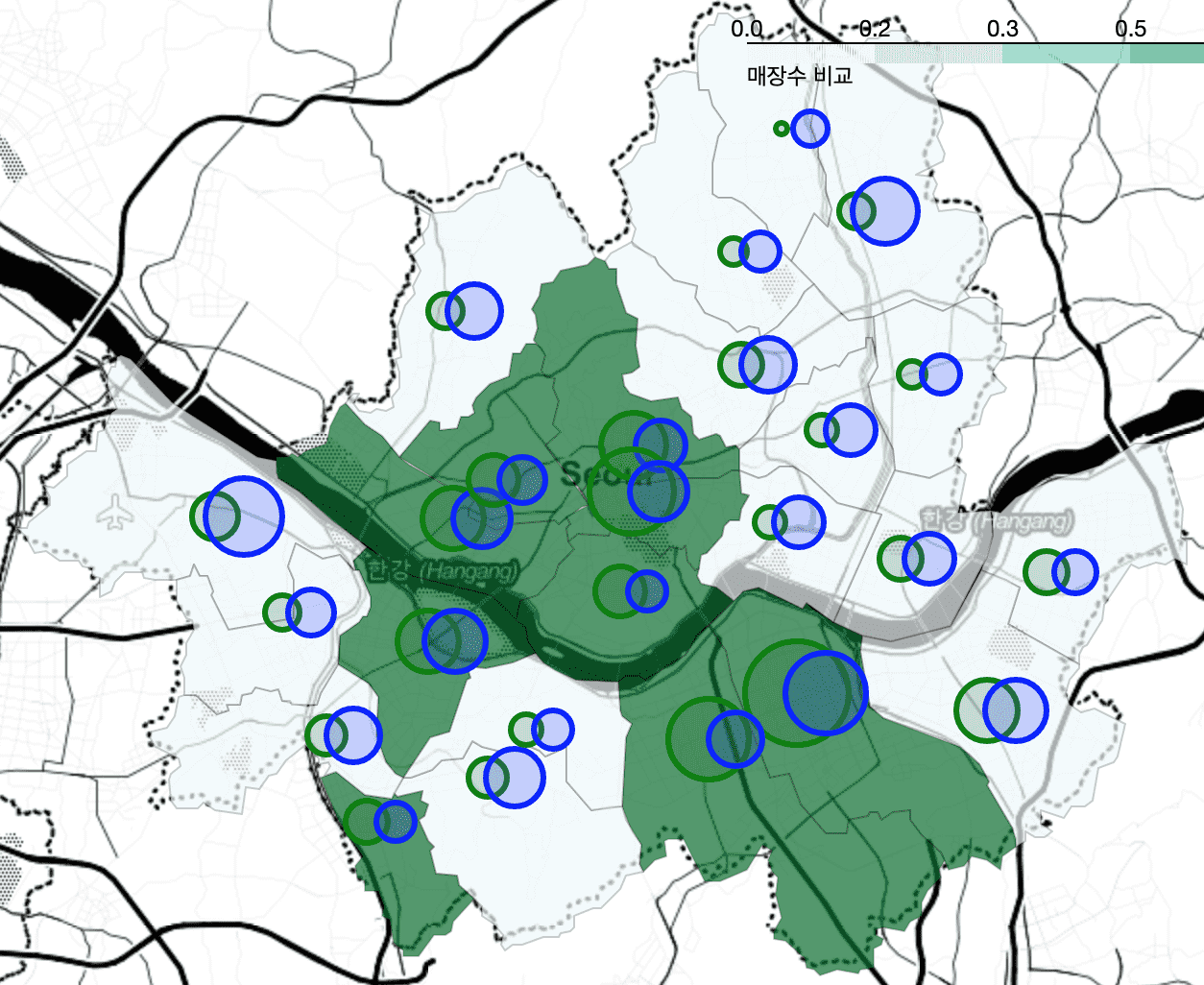
<Chương 4 So sánh vị trí cửa hàng Starbucks và Ediya>
Để vẽ CircleMarkers một cách riêng biệt, chúng tôi đề cập đến quá trình tính toán kinh độ và vĩ độ trung bình thông qua Pivot_table mà không sử dụng câu lệnh for và hợp nhất các kết quả tính toán thông qua merge . Ngoài ra, lời giải thích đã trở nên chi tiết hơn nhiều.
<Chương 5> cũng sẽ sớm được đổi mới!
Tôi nghĩ nó sẽ giúp chúng tôi tạo ra các khóa học tốt hơn nếu bạn để lại nhận xét của mình thông qua các câu hỏi hoặc đánh giá khóa học trong tương lai!
Chúng tôi mong nhận được đánh giá và phản hồi về khóa học của bạn :)