




네이버 view탭 검색 결과 크롤링 2, 3 질문
809
작성한 질문수 2
안녕하세요 강사님. 질문이 있어서 남기게 되었습니다.
첫 번째 질문: 네이버 view탭 검색 결과 크롤링 2를 완료한 이후 아래 코드 실행 후 손흥민을 검색했는데 검색결과가 30개가 아닌 7개가 출력되었습니다. 이러한 이슈 때문인지 네이버 view탭 검색 결과 크롤링 3 강의가 정상적으로 진행되지 않습니다.
import requests
from bs4 import BeautifulSoup # beautiful soup 라이브러리 import
base_url = "https://search.naver.com/search.naver?where=nexearch&sm=top_hty&fbm=0&ie=utf8&query="
keyword = input("검색어를 입력하세요 : ")
url = base_url + keyword
print(url)
headers = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36"
} # dictionary
req = requests.get(url, headers = headers) # GET 방식으로 naver에 요청
html = req.text # 요청을 하여 html을 받아옴
soup = BeautifulSoup(html, "html.parser") # html을 html.parser로 분석(클래스를 통한 객체 생성)
total_area = soup.select(".total_area")
timeline_area = soup.select(".timeline_area")
if total_area:
areas = total_area
elif timeline_area:
areas = timeline_area
else:
print("class 확인 요망")
for area in areas:
title = area.select_one(".api_txt_lines.total_tit")
name = area.select_one(".sub_txt.sub_name")
print(name.text)
print(title.text)
print(title["href"])
print()
print(len(areas))
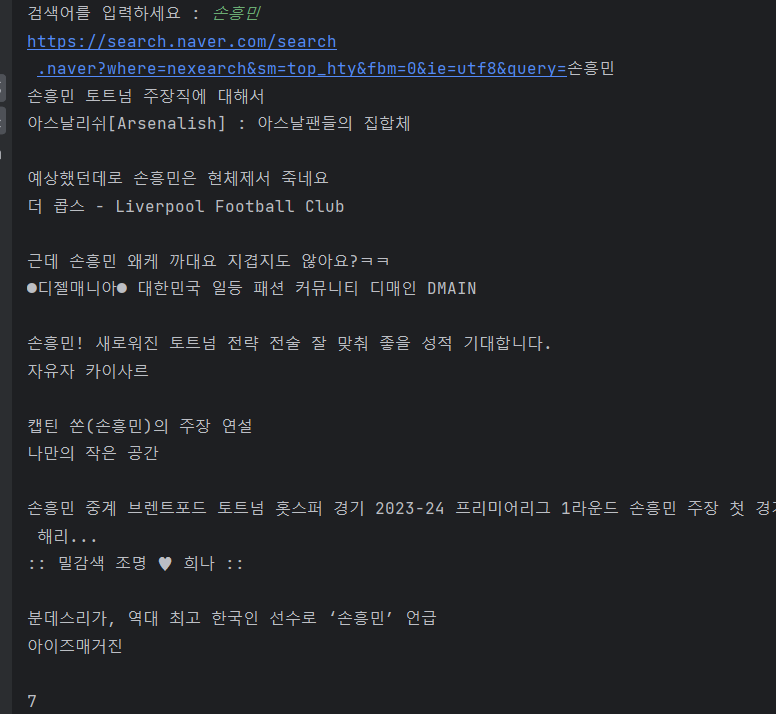
두 번째 질문: 네이버 view탭 검색 결과 크롤링 3을 진행하면서 아래 코드처럼 작성하고 손흥민을 검색했을 때 NoneType 오류가 발생합니다. 첫 번째 질문의 이슈로 인해 그런 것인가요? .total_wrap.api_ani_send 클래스가 브라우저 상에서는 30개가 잘 나오는데 제대로 안 받아와진 것 같은 느낌이 듭니다. 도와주시면 감사하겠습니다 ㅠㅠ
Traceback (most recent call last): File "C:\python_web_crawling\01_4_naver.py", line 30, in <module>
print(title.text)
^^^^^^^^^^
AttributeError: 'NoneType' object has no attribute 'text'
아래는 코드입니다.
import requests
from bs4 import BeautifulSoup # beautiful soup 라이브러리 import
base_url = "https://search.naver.com/search.naver?where=nexearch&sm=top_hty&fbm=0&ie=utf8&query="
keyword = input("검색어를 입력하세요 : ")
url = base_url + keyword
print(url)
headers = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0.0.0 Safari/537.36"
} # dictionary
req = requests.get(url, headers = headers) # GET 방식으로 naver에 요청
html = req.text # 요청을 하여 html을 받아옴
soup = BeautifulSoup(html, "html.parser") # html을 html.parser로 분석(클래스를 통한 객체 생성)
items = soup.select(".total_wrap.api_ani_send")
for area in items:
# ad = area.select_one(".link_ad")
# if ad:
# print("광고입니다.")
# continue
title = area.select_one(".api_txt_lines.total_tit")
name = area.select_one(".sub_txt.sub_name")
print(title.text)
print(name.text)
# print(title["href"])
print()
#print(len(items))답변 1
1
base_url에 문제가 있습니다.
BBangJun님이 사용하신 base_url을 사용해서 손흥민을 검색하면 아래와 같은 url입니다.
https://search.naver.com/search.naver?where=nexearch&sm=top_hty&fbm=0&ie=utf8&query=손흥민
접속해 보면 view탭이 아닌 걸 확인하실 수 있습니다.
멜론 사이트 수집부터 안됩니다
0
79
1
강의 시점이랑 현재랑 네이버 사이트 변화가 많은거 같아서 질문드립니다.
0
70
1
-href 가져오기
0
101
2
수업내용 프로젝트의 완성된 코드는 제공이 안돼나요?
0
164
1
안녕하세요 쿠팡 크롤링 막힌거 같아요 3번돌리니깐 막았어요 해결방법없을까요?
0
3750
1
쿠팡 BeautifullSoup 헤더넣어도 막히네요
0
452
1
네이버 쇼핑 크롤링 1 코드 사용 시, 접속 제한됐을 때의 해결 방법이 궁금합니다.
0
3227
1
추가 강의 업데이트 있나요?
0
251
1
lambda 중에 문의가 있습니다.
0
281
1
텔레그램 sendMessage 시 400에러가 뜹니다.
0
931
2
ftp 로긴 문제입니다. ㅜ
0
429
2
네이버 쇼핑 크롤링 질문입니다.
0
381
1
XPATH 네이버에서 카페 찾는 과정 문의입니다.
1
325
1
셀레니움 By.XPATH 를 이용한 키워드 입력 작성 질문입니다.
0
691
2
쿠팡 이미지 파일 다운받기에서 동일하게 코드 작성 후 요청하였지만 파일 다운로드가 안됩니다.
0
838
2
파이썬에 키워드를 치는게 아닌...
0
285
2
50프로 수강중입니다~
0
231
1
제품 링크를 타고 들어가야 원하는 정보가 나오는 사이트
0
396
2
lst = lst50 + lst100 이거 대신에
0
335
2
증권, 메일 등 서비스 목록을 못가져와요 ㅠㅠ
1
300
1
네이버에 view탭이 업데이트가 됐는지 없어졌네요... ㅠㅠ
1
246
1
선생님이랑 똑같이 적었는데 저는 왜 오류가 날까요?ㅠ
0
359
2
네이버쇼핑 크롤링 문의
0
440
2
asyncio.run() cannot be called from a running event loop 에러 질문 드립니다
0
3934
4