




nn.CrossEntropyLoss() method 질문
578
작성한 질문수 5
- 학습 관련 질문을 남겨주세요. 상세히 작성하면 더 좋아요!
- 먼저 유사한 질문이 있었는지 검색해보세요.
- 서로 예의를 지키며 존중하는 문화를 만들어가요.
- 잠깐! 인프런 서비스 운영 관련 문의는 1:1 문의하기를 이용해주세요.
좋은 강의 항상 감사드립니다.
nn.CrossEntropyLoss() 는 nn.LogSoftmax 와 nn.NLLLoss 연산의 조합이라고 말씀해 주셨고, cross-entropy는 아래와 같은 식인 것으로 알고 있습니다.
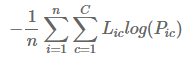
위 식에서 log는 한번만 취해지는 것으로 보입니다. 그런데 CrossEntropyLoss가 LogSoftmax 와 NLLLoss 연산의 조합이라면 Log 함수가 두번 사용 되는 것 같아서 이해가 잘 되지 않습니다.
설명을 해주시면 감사드리겠습니다 :-)
답변 1
0
로그 함수를 사용하는 이유는 다음과 같습니다.
계산 단순성: 우도 함수의 로그를 취하면 많은 작은 수의 곱을 일반적으로 계산 작업이 더 쉬운 로그의 합으로 변환합니다.
수치적 안정성: 확률로 작업할 때 수치적 언더플로 및 정밀도 손실로 이어질 수 있는 매우 작은 숫자를 만나는 것이 일반적입니다. 우도의 로그를 취하면 작은 수의 곱을 일반적으로 수치적으로 처리하기 더 쉬운 로그의 합으로 변환하여 이 문제를 피할 수 있습니다.
해석 가능성: 로그 우도는 우도 함수의 로그가 데이터의 엔트로피에 비례하므로 간단한 해석이 가능합니다. 즉, 로그 우도는 데이터에 포함된 정보의 양을 측정합니다. 이러한 해석은 로그 우도를 모델 선택 및 가설 테스트에 유용한 도구로 만듭니다.
요약하면 우도의 로그를 취하면 계산의 단순성, 수치적 안정성, 볼록 최적화 문제 및 데이터의 정보 내용에 대한 해석 가능한 측정이 제공됩니다. 따라서, 위의 질문에서 log 를 한 번 취했는지, 두 번 취했는지는 중요한 문제가 아닌 것이, 우리가 구하고자 하는 것은 최종 확률 분포가 어떻게 되는가 하는 것이기 때문입니다. 따라서 계산상의 안정성을 취하면서 최종 확률 분포가 바뀌는 것이 아니기 때문에 log 가 포함되던 포함되지 않던 결과에 영향을 미치지 않습니다.
좋은 질문 감사합니다.
[긴급요청] 28강 동영상 전체에 오디오가 잘못들어가있습니다.
0
15
1
17강 강의 마지막 부분에서 헷갈리는 부분이 있습니다.
0
23
0
14강의 예시 데이터를 통한 답을 구하는 과정에서의 문의
0
25
1
강의 자료 열람 요청이 안되네요
0
18
1
예측에 사용하는 경제지표의 활용에 대해
1
32
2
강의 자료를 어디서 확인 할 수 있나요?
1
44
3
실습 코드
0
33
2
보드 관련 질문 드립니다.
1
59
2
MMDetection 버전 이슈
0
58
2
[업로드오류] 강의 내용과 제목 불일치
0
46
2
섹션22 퀴즈 질문
0
58
1
import torch가 안되는 경우는 어떻게 하나요?
0
57
1
소리가 겹쳐서 들려요
0
65
2
20강에서 파인튜닝 때 사용한 데이터가 없어졌습니다. LoRA Trainer 매개변수도 라이브러리 업그레이드로 수정되었습니다.
0
46
1
[개정판] 딥러닝 컴퓨터 비전 완벽 가이드 먼저? 구현하며 배우는 Transformer 먼저?
0
63
1
mini-batch gradient descent 시 backpropagation에 대하여
0
87
2
이미지가 출력되지 않습니다
0
225
2
IMDBDataset 파일 다운로드가 안되는데 어떻게 받을 수 있을까요?
0
299
1
the kernel appears to have died. it will restart automatically.
0
673
1
파이토치 device (gpu / cpu) 관련 질문드립니다.
0
721
1
5분10초 경, 강의자료에 대하여 질문드립니다.
0
326
1
update 공식 관련 질문 (3분31초 경)
0
318
1
종속변수와 독립변수
0
581
1
linspace(100, 200, 10)
0
364
1