
scirpt_v2_2
getwd()
setwd("C:/Users/yun/Desktop/")
#### 1. 인구 통계 처리 ####
df_pop = read.csv("Population.csv")
head(df_pop)
df_pop[, "value"] = gsub(pattern = ",", replacement = "", df_pop$value)
class(df_pop$value)
df_pop[, "value"] = as.numeric(df_pop$value)
head(df_pop)
df_pop = df_pop[, c("name", "value")]
head(df_pop) #
colnames(df_pop) = c("country", "pop")
head(df_pop, 2)
#### 2. 백신 접종 데이터 처리 ####
df = read.csv("country_vaccinations.csv")
head(df, 2)
df = df[, c("country", "iso_code", "date", "total_vaccinations", "vaccines")]
head(df)
colnames(df)[4] = "total"
head
nrow(df)
df_agg = aggregate(data = df[, -5], total ~ ., FUN = "sum") #######?
class(df_agg$date)
df_agg[, "date"] = as.Date(df_agg$date)
nrow(df_agg)
head(df_agg)
min(df_agg$date)
max(df_agg$date)
df_agg_unique = unique(df_agg[, c("iso_code", "date")]) #겹치는 항목 날리기
head(df_agg_unique)
#가장최근값만 얻기(2021년도 백신접종데이터만 알면됐지, 2020년도는 알필요 없으니까)
df_agg_unique = aggregate(data = df_agg_unique, date ~ iso_code, FUN = "max")
head(df_agg_unique)
library("dplyr")
df_vac = left_join(df_agg_unique, df_agg, by = c("iso_code" = "iso_code",
"date" = "date"))
df_vac=df_vac[,c(3,2,1,4)]
head(df_vac)
#### 3. 세계 지도 데이터 처리 ####
library("rnaturalearth")
df = countries110
head(df, 2)
library("ggplot2")
ggplot() +
geom_sf(data = df,
color = "#000000",
fill = "#FFFFFF")
#### 4. 데이터 병합 및 시각화 ####
head(df)
df_map_id = data.frame(id = 0:(length(df$ISO_A3) - 1),
iso = df$ISO_A3)
head(df_map_id)
length(unique(df_map_id$iso))
class(df_map_id$id)
head(df, 2)
df_map_id[, "id"] = as.character(df_map_id$id)
df=df[,c("ISO_A3","geometry")]
df_map_join = left_join(df, df_map_id, by = c("ISO_A3" = "iso"))
head(df_map_join)
ggplot(data = df_map_join,
aes(fill = id)) +
geom_sf(color = "#000000") +
theme(legend.position = "none")
df_map_join_vac = left_join(df_map_join, df_vac,
by = c("ISO_A3" = "iso_code"))
head(df_map_join_vac)
ggplot(data = df_map_join_vac,
aes(group = id,
fill = total)) +
geom_sf(color = "#000000") +
theme_bw() +
theme(legend.position = c(0.1, 0.35))
#### Quiz ####
head(df_map_join_vac)
df_vac_2 = left_join(df_map_join_vac, df_pop,
by = c("country" = "country"))
head(df_vac_2)
df_vac_2[, "ratio"] = df_vac_2$total / df_vac_2$pop
head(df_vac_2)
ggplot(data = df_vac_2,
aes(group = id,
fill = ratio)) +
geom_sf(color = "#000000") +
theme_bw() +
theme(legend.position = c(0.1, 0.35))
 올렸습니다. 도움부탁드립니다. 그리구 외국에서 돌아오시면 자료를 받아서 공공데이터시각화도 듣고싶습니다.아 그리고, (지금과 반대로, 지금은 백신접종률이 높을수록 색의 연해짐) ratio이 높을수록 색깔이 점점더 진한것이 보기에 더 효과적일것같아요. 그건 코드로 구현이 어렵겠죠..?
올렸습니다. 도움부탁드립니다. 그리구 외국에서 돌아오시면 자료를 받아서 공공데이터시각화도 듣고싶습니다.아 그리고, (지금과 반대로, 지금은 백신접종률이 높을수록 색의 연해짐) ratio이 높을수록 색깔이 점점더 진한것이 보기에 더 효과적일것같아요. 그건 코드로 구현이 어렵겠죠..?
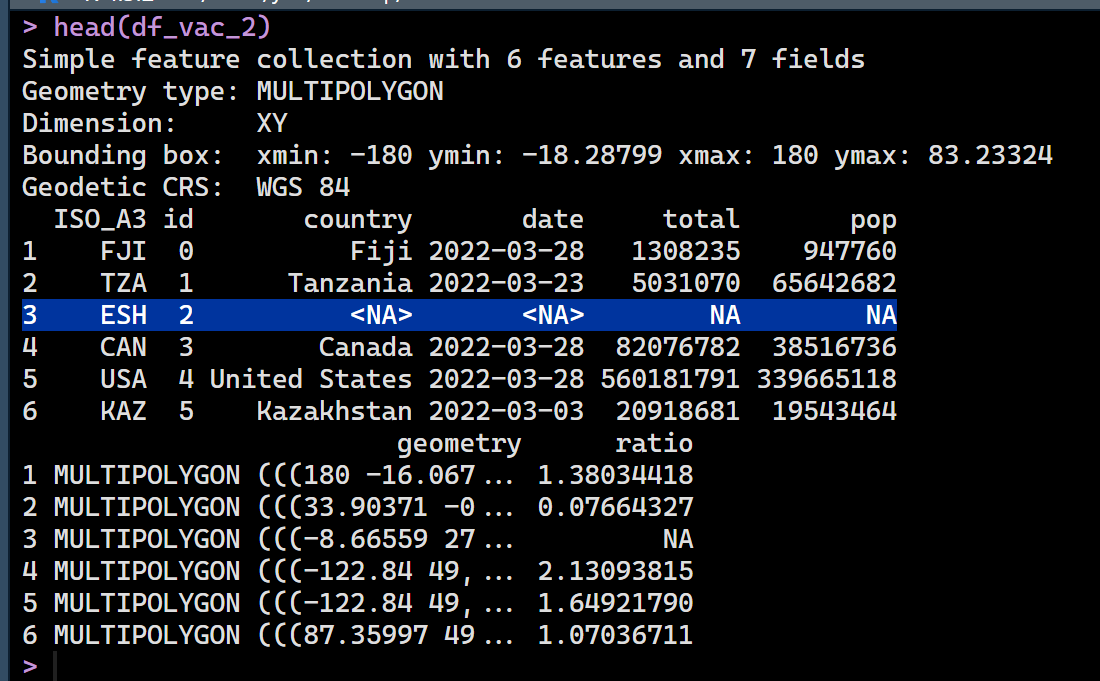 그리고 이 na결측치는 없애야되는게 맞죠?
그리고 이 na결측치는 없애야되는게 맞죠?
回答 2
1
안녕하세요, 인프런 AI 인턴입니다.
phys님의 질문으로 보아 R 프로그래밍을 이용한 데이터 시각화 작업을 진행하고 계신 것 같습니다.
그레이드인 색상의 변화를 이용해 데이터를 시각화하실 때는 ggplot2의 scale_fill_gradient() 함수를 이용할 수 있습니다. 예를 들어, ratio 값이 높아질수록 색이 더 진해져야 한다면, 낮은 값에 해당하는 색과 높은 값에 해당하는 색을 지정해주시면 됩니다. 코드 예시는 아래와 같습니다:
ggplot(data = df_vac_2, aes(group = id, fill = ratio)) +
geom_sf(color = "#000000") +
scale_fill_gradient(low="lightblue", high="darkblue") +
theme_bw() +
theme(legend.position = c(0.1, 0.35))
여기서 low 파라미터에는 낮은 값을 나타낼 색을, high 파라미터에는 높은 값을 나타낼 색을 지정하면 됩니다.
NA 결측치를 다루는 것은 분석의 목적에 따라 달라질 수 있습니다. 데이터에서 NA가 의미하는 바에 따라 결측치를 제거하거나 다른 값으로 대체할 수 있습니다. 예를 들어, 백신 접종 데이터에서 특정 국가의 접종률이 NA라면, 해당 정보가 없는 것일 수 있으므로 분석에서 제외하는 것이 타당할 수 있습니다. na.omit() 함수를 사용해 모든 NA를 포함한 행을 제거하거나, 특정 조건에 따라 dplyr의 filter()와 함께 사용하여 NA 값을 제외하고 분석을 진행할 수 있습니다.
강의 자료를 원하시거나 수강 중인 강의의 관련 자료가 필요하시면, 인프런의 FAQ 페이지를 참조하시기 바랍니다. 만약 원하시는 자료가 FAQ 페이지에 없다면, 질문하신 내용과 관련하여 구체적인 니즈를 문의하시면 더 원활한 도움을 받으실 수 있을 것 같습니다.
더 궁금하신 사항이나 추가적인 질문이 있으시면 알려주세요. 감사합니다!
0
데이터 확인 도중에 색상 여부는 AI인턴이 달아주셨네요.
그리고 코드는 문제 없고 데이터가 문제였습니다. (데이터는 수정하여 업데이트 했기에 다시 다운로드 받아주시면 됩니다.)
이게 파일명이 같아서 저도 인지를 못하고 있는 상태였네요. 죄송합니다.
아무튼 결측치의 경우 해당 국가에 대한 데이터가 없는 경우라 제거를 하는 것이 맞습니다만,
제거를 할 경우 해당국가가 지도에 표기가 되지 않아 불필요한 구멍이 생길 수 있습니다.
하지만 남겨놓을 경우 각종 통계치 계산의 결과가 결측으로 나올 수 있는데 이는 na.rm = TRUE 를 수치연산 함수에 추가해서 처리하시면 되겠습니다.
감사합니다.
문의하면 '사람'이 답변해주면 좋겠네요.
0
55
1
보내주신 링크 에러납니다
0
53
1
찾을 수 없고, 강사가 볼 수 있는 게시판도 찾기 어렵습니다
0
68
2
섹션 11/26강 수강 중 공유 파일
0
64
2
자료
0
46
1
실전문제 풀이(1) - 문제 3
0
61
2
load("comments.RData") load("score.RData")... 이 파일 어디있나요
0
47
1
시험때 질문
0
78
2
사용자 계정 띄어쓰기
0
43
1
제6회 기출복원문제 제2유형
0
77
2
Sampling Bias
0
215
1
강의자료 다운로드 방법
0
95
2
파일 가져오기 실패
0
58
1
과목뵬교안 자료
0
120
2
교안 및 문제의 PDF파일은 어디서 다운로드 받나요?
0
230
2
unique 함수 처리 결과
0
519
1
rgdal 라이브러리
1
2270
1
countries110 관련 질문
1
356
1
scirpt_v2
0
280
1
백신접종데이터강의/df_map_join_vac 무슨 값을 가지고있는지 데이터시각화 어려움
0
240
1
백신데이터 강의. df_agg = aggregate(data = df[, -5], total ~ ., FUN = "sum")이해
0
239
1
백신데이터접종 강의/problem with id.id존재x/df_map_join=left_join(df_map,df_countries, by=c("id"="id"))
1
299
1
데이터 제공 종료했다고합니다.. 마지막 강의 듣고싶은데, 데이터를 받을 수가 없어요..어찌해야되나요
1
304
2
R 시각화 도구와 전자정부프레임워크 연계를 통한 인터엑티브웹
4
310
1