
Disjoint Set 질문있습니다
453
1 asked
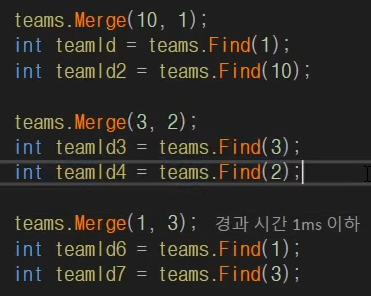
위 코드의 전체적인 구조를 보면
2
3__ 1
____10
이고
여기서 만약 Find(10)을 실행한다면
 이 코드에 의해
이 코드에 의해
2
3 1 10
이렇게 구조가 바뀔 텐데
_rank[2]의 값이 3에서 바뀌지 않는데
_rank 수정 코드도 필요하지 않나요?
Answer 1
4
도움이 될 진 모르지만 저도 이 질문 보고 거의 일주일 넘게 답을 찾아 헤매서.. 지나가다 궁금해 하시는 분 계실까봐 댓글 답니다.
위키에 이렇게 적혀있네요.
While the rank of a node is clearly related to its height, storing ranks is more efficient than storing heights. The height of a node can change during a
Findoperation, so storing ranks avoids the extra effort of keeping the height correct.
https://en.wikipedia.org/wiki/Disjoint-set_data_structure#Union_by_rank
해석하면
노드의 순위는 그 높이와 분명히 관련이 있지만, 순위를 저장하는 것이 높이를 저장하는 것보다 더 효율적이다. 찾기 작업 중에 노드의 높이가 변경될 수 있으므로 순위를 저장하면 높이를 정확하게 유지할 필요가 없습니다.
그래서 곰곰히 생각해 본 결과 find 연산 시 최적화를 위해 경로 압축 방법을 사용하고, union 연산 시 최적화를 위해 union by rank 방법을 사용하기 때문에 서로 다른 범위?라고 생각하는 게 전 제일 마음이 편했습니다..
한 번 매겨진 랭크는 증가만 할 뿐 딱히 감소하는 건 아닌 것 같네요. 랭크가 높을수록 union 연산을 많이 했다는 증거니, 아무래도 많은 쪽에 붙이는 게 확률적으로 이득이라 by rank나 by size 도 그런 비슷한 원리에서 나온 방법들 같다고 혼자 결론지었습니다..
저도 정확히 알고 싶은데.. 아직도 너무나 궁금합니다..ㅠㅠㅠ 혹시 정확히 알고 계신 분이 있으시다면 언제라도 좋으니 시원하게 알려주시면 감사하겠습니다.
(- -)(_ _)
헤더파일에 관한 질문
0
460
1
이진 탐색 트리 삭제 질문
0
741
1
해당 문제 유형을 수학적으로 표현 가능할까요?
0
537
1
vs2022 미로 줄간격
0
1632
2
pos 구조체 초기화 문제
0
512
0
맵이 이상하게 나오는데 무슨 문제인가요?
0
532
1
자동완성 기능 질문
1
549
2
push_back emplace_back 질문있습니다.
0
412
1
Container, Predicate 질문입니다.
0
412
1
_size - 2 질문
0
435
1
우선순위 큐 구현 연습 intellisense 질문
0
420
1
int32 관련 질문
0
290
1
c++에서 처음 보는 문법
0
407
1
학습에 크게 지장이 있는건 아니지만 단순 궁금해서 질문드립니다
0
338
1
힙 정렬과 병합 정렬
0
441
1
resize 질문
0
273
1
처음 보는 for문 문법
0
411
1
환경 설정.. 궁금점
0
420
1
이 비교 연산자를 넣어주는 이유가 있나요?
0
302
1
소멸자 관련 질문
0
265
1
&의 차이
0
296
1
프레임 관리 질문입니다.
0
347
1
연산자 오버로딩 관련 질문입니다.
1
218
1
안녕하세요 goormide 학습자입니다.
0
884
4