
100%
0원
- 신청 기간
-
2023.12.01 20:29 ~ 12.19 23:59 (한국 표준시)
- 기간
-
약 5개월 (2023.12.27 ~ 2024.06.11)
- 장소
- 온라인으로 진행하는 모임입니다
처음 기획부터 끝까지 ‘데이터 사이언티스트’ 필수 역량 하나에 맞춘 유일한 과정 마침내 탄생! 데이터분석툴로 대시보드 만드는 방법만 더 이상 배우지마세요!

🤍 Point 1 🤍
현업 데이터 사이언티스트 & 모두의연구소 AI 연구원 Special Unit✨
데이터 사이언티스트 필수 역량에 맞춰 완성한 교육 프로그램!
🤍 Point 2 🤍
기업이 원하는 실전형 비즈니스 프로젝트 경험✨
데이터 4대 인기 분야 핵심 기업별 연계 프로젝트!
🤍 Point 3 🤍
3년 동안 1,000명이 선택한 아이펠✨
주입식 부트캠프가 아닌 자기주도형 '커뮤니티 교육!
데이터 사이언티스트 "직무 본질"에 집중한 교육,
왜 없을까?🤔
바로 "필수 역량"을 제대로 이해하고 이지 않기 때문에!

데이터에 대한 니즈는 같아도
데이터 사이언티스트의 니즈는 다르니까

🤍 Point 1 🤍
마침내 한곳에 모이다



🤍 Point 2 🤍
마침내 답을 찾다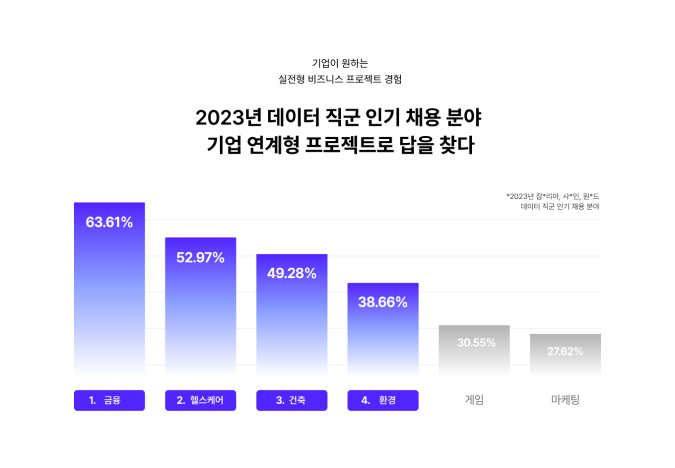

🤍Point 3 🤍
마침내 완성하다


1,000명이 선택한
AI학교 아이펠


모두의연구소 입니다.

[모두의연구소 : 2024 과학기술정보통신부 장관 표창]
[모두의연구소 : 2024 디지털인재 리더스 클럽 선정]
[모두의연구소: K-디지털 트레이닝 훈련기관 중 유일한 대통령 표창 수상]
모두의연구소는 기존 주입식 부트캠프 교육을 탈피해 스스로 답을 찾는 커뮤니티형(Learning By Doing)액티브 러닝 기반, 교육의 진정성을 담은 새로운 SW/AI 과정을 제공합니다
프로그램
1주차
| 온보딩 | * 모두의연구소와 아이펠의 교육 철학 이해 * 모두의연구소가 지향하는 커뮤니티형 교육이란 무엇인가 * 모두의연구소 김승일 소장님과 함께 진행합니다 * 아이펠 교육 방식의 이해 * 게임형 퀘스트 유형 설명 및 실습하기 * 과정에서 목표로 하는 그루의 성장 이미지에 대해 공유하기 |
| 2주차 | |
| 데이터 사이언티스트로 가는 첫걸음 |
데이터 사이언티스트의 역할과 직무에 대한 이해 및 리눅스, Git, 파이썬 기본기 등 데이터 사이언티스트가 되기 위한 기초 소양 갖추기 * Git 이해 및 실습 * 터미널로 배우는 리눅스 운영 체제: 명령어 실습, 운영 체제, 커널, 셸 |
| 3주차 | |
| SQL을 사용하여 데이터베이스 다루기(수집) |
데이터 수집부터 해석-처리까지 (데이터 수집 및 데이터 해석, SQL과 파이썬을 활용한 데이터 처리 실습) * 데이터베이스와 테이블 구조의 개념 이해 및 실무 데이터 해석 실습 * 데이터, 데이터베이스, 테이블, 스키마 개념 이해 * SQL 기본 문법(join, groupby, window)의 원리 이해 및 사용 실습 * pandasql 라이브러리, mySQL 실습 * SELECT, FROM, WHERE, 비교, 논리, 산술 연산 * LIKE, Wildcard, Alias, ORDER BY, IF, CASE WHEN, THEN, CAST * 데이터 조건, 별칭, 정렬, 조건 제거, 조건문, 타입변환 * COUNT, SUM, AVG, MAX, MIN, GROUP BY, HAVING, 집계, 그룹화, 조건 * PK, FK, JOIN, UNION, Subquery * 기본키, 외래키, 다중테이블, 데이터 붙이기, 서브쿼리 * 데이터 크롤링의 이해 및 실습 * Python, 데이터 크롤링, 웹의 구조와 통신 * 인터넷, 프로토콜, API(Web, HTTP, REST API), 크롤링(urllib, BeautifulSoup, Requests) * 날씨 API 가져오기 코드 * 네이버 환율 정보 크롤링 실습(BeautifulSoup, Requests, pandas) |
| 4주차 | |
| 비정제데이터 체험하기 |
통계적 기법을 활용한 비정제 데이터의 정제 및 BigQuery 플랫폼 기반 프로젝트 수행 * 통계적 기법을 활용한 데이터 탐색 및 정제 * Feature Engineering * 수치형 데이터 결측치, 중복데이터, 이상치 (z-score, IQR), 정규화(standarization, min-max) * 범주형 데이터, 원핫인코딩, 구간화(Binning) * Encoding, Scaling, Feature Selection 기법 실습 * 데이터 시각화 * 히스토그램을 활용하여 데이터 분포 다루기 * 박스 플롯, 바이올린 플롯, 산점도, 상관행렬 히트맵 |
| 5~6주차 | |
| 적절한 데이터 분석을 위한 기초 통계 |
데이터사이언스를 위한 기초 통계 개념의 이해 및 데이터 통계적 기법을 활용한 데이터 탐색(EDA)의 수행 * 데이터 분석에서 통계의 역할과 기초 개념 이해 * 통계학의 개념 이해하기, 모집단과 표본, 통계분석의 기초 * 추론 통계, 가설 검정 * 데이터로 모집단의 성질 추정(추론 통계~신뢰) * 가설 검정: 가설 검정과 p 값, 다양한 가설 검정(t 검정-분산 분석-카이제곱 검정) * 상관관계와 회귀: 두 양적 변수의 관계 분석 * 통계 모형화: 선형회귀에서 일반화 선형 모형으로 * 인과관계와 상관관계 * 베이즈 통계 * 통계분석과 관련된 다른 방법들 익히기: 주성분 분석부터 기계 학습까지 * 통계 모형의 이해: 통계 모형, 기계학습 모형, 수리 모형 |
| 7~8주차 | |
| 머신러닝을 활용한 다양한 데이터 다루기&데이터톤 | 데이터 핸들링, 시각화부터 머신러닝, CV/NLP의 원리 이해 및 프로젝트 까지. 한큐에 끝내는 머신러닝 기반의 데이터 다루기 실습 * 데이터 EDA, 전처리 및 시각화 실습 * numpy, pandas, matplotlib 등 라이브러리를 활용하여 데이터 EDA, 전처리 및 시각화 * 지도학습(분류 및 회귀)와 비지도학습 머신러닝 프로젝트 수행 * scikit-learn 라이브러리를 활용하여 지도학습(분류 및 회귀)와 비지도학습 머신러닝 프로젝트를 수행 * 지도학습 알고리즘의 이해 * 로지스틱 회귀(Logistic Regression), 의사결정 나무(Decision Trees), 랜덤포레스트(Random Forests), 그라디언트 부스팅(Gradient Boosting)의 원리 이해 및 설명 * 비지도학습 알고리즘의 이해 * 군집화(Clustering)와 차원 축소(Dimensionality Reduction)를 위한 K-평균(K-Means), 주성분 분석(PCA)의 원리를 이해 및 설명 [데이터톤] * 주어진 데이터를 활용하여 팀 프로젝트 완성하기 * Task에 알맞은 EDA와 전처리 실습하기 * 데이터를 해석하는 데 적합한 모델 탐색과 선정 근거 마련하기 * 모델 성능 평가를 위한 지표 설정과 추론 결과 분석하기 * 모델 성능 향상을 위한 근거 분석과 논리적인 방법론 선택하기 * 아이디어를 뽐내고 함께 응원과 피드백 받기 |
| 9주차 | |
| 금융 시계열 체험하기 |
기업 금융 데이터를 활용한 데이터 분석 실습 * 시계열 데이터 이해와 전처리 * 시계열 데이터의 추세, 계절성, 정상성을 이해하고, 직접 눈으로 확인하기 위한 스킬 함양 * 로그 변환, 차분 등을 통해 데이터를 전처리하는 방법 이해 및 실습 * 데이터 시각화와 패턴 분석 * Matplotlib를 사용한 데이터 시각화와 시계열 데이터의 패턴을 분석하는 스킬 함양 * ACF와 PACF를 활용하여 데이터의 자기상관성의 이해 * 시계열 데이터 분류와 전처리 (tsfresh 라이브러리) * Robot execution failures 데이터셋을 활용하여 시계열 데이터를 분류하는 방법의 이해 * 데이터를 정상화하고 추세와 계절성을 제거하는 과정 실습 * ARIMA 모델과 시계열 분석 (ADF 테스트, 결측치 처리) * ARIMA 모델의 이해 및 시계열 데이터의 안정성을 검정(ADF 테스트) * 결측치 처리 방법의 습득 및 모델 성능 평가 실습 * 추세 데이터 라벨링과 시계열 분류 (피처 엔지니어링, 분류 모델) * 추세 데이터 라벨링과 피처 엔지니어링을 통한 데이터를 가공하고 분류 모델 구축 * 다양한 분류 알고리즘을 활용하여 데이터를 분류하고 모델 성능을 평가 |
| 10~11주차 | |
| 딥러닝의 기초부터 다양한 프로젝트 실습 | * 딥러닝의 개념 이해 * 인공 신경망의 개념과 역사 이해 * 퍼셉트론, 다층퍼셉트론, 역전파 알고리즘, 기울기 소실, 과적합 상태 이해 * 텐서와 연산 * 텐서 개념, 타입, 타입 변환, 텐서 연산 등과 관련된 코드 연습 문제 실습 * 딥러닝 구조와 모델 이해 * Tensorflow, Keras 프레임워크 이해 및 코드 실습 * sequential, functional, subclassing API 코드 간단 실습 * 레이어 개념의 이해(dense, activation, flatten layer) * 모델 상세 구조에 따라 functional API 또는 subclassing 방식의 모델 구현 * 딥러닝 모델 학습 * 손실함수, 옵티마이저(SGD, Adam), 지표, 딥러닝 모델 학습 * 경사하강법, 옵티마이저, 학습률, 지표, mae, accuracy, 모델학습플로우, 간단 코드실습 * 모델 저장과 콜백 * mnist 딥러닝 모델 실습, 모델 저장 로드, 콜백, earlystopping, tensorboard * 모델 학습 기술 이해 * 미니배치, 스케일링(표준화,정규화), 가중치 초기화, 하이퍼파라미터 튜닝, 활성화함수 등 모델 학습 기술, 과소, 과대적합, 케라스 IMDB 데이터 다루기 * Convolutional Neural Network 이해 * Channel Convolution, Pooling, CNN을 활용한 네트워크 구조의 이해 * Object Detection, Segmentation 등 세부 task의 이해 * Transfer Learning을 활용한 효율적인 fine-tuning |
| 12~13주차 | |
| NLP 프로젝트 톺아보기 |
자연어 데이터 처리의 개념과 원리를 이해하고, 초거대 언어 모델(LLM)까지 살펴보기 * 문자열 인코딩/디코딩 및 정규 표현식 활용의 이해. |
| 14주차 | |
| 추천 시스템 체험하기 |
딥러닝 기반 추천시스템 원리 이해 및 실습하기 * 추천 시스템의 기본 개념 및 종류 이해 * 코사인 유사도와 콘텐츠 기반 필터링, 협업 필터링 (사용자 행동 양식 데이터), 잠재 요인 분석 (LFA) 학습 및 적용 * 비슷한 스타일의 아티스트로 추천 및 데이터 처리 * 비슷한 스타일의 아티스트로 추천 방법의 학습 및 실제 데이터를 다루기 위한 pandas와 데이터 처리 기술 습득 * Implicit 데이터와 협업 필터링, MF 모델, CSR Matrix를 활용한 추천 시스템 구축 * 다음 아이템 예측 및 세션 기반 추천 * 유저의 다음 클릭 또는 구매를 예측하는 추천 시스템의 구현 * 세션 기반 추천을 이해하고 E-Commerce 데이터를 다루며, GRU4REC와 성능 평가 지표의 활용 실습 * 딥러닝 기반 추천 시스템 * 딥러닝을 활용하여 추천 시스템을 개발하는 개념의 이해 * 딥러닝 프레임워크 기반의 추천 시스템을 위한 다양한 신경망 모델 구현 실습 |
| 15~16주차 | |
| 데이터 분석 실무 알아보기 | 데이터 사이언티스트 실무에 바로 적응하기 위한 마지막 준비! * 개발 환경 구축 및 협업 * Jupyter Notebook을 벗어난 코드의 버전 관리& 모듈화를 위한 새로운 개발 환경 구축 실습 * 로컬 환경에서 딥러닝 프로젝트를 개발하고 관리하는 방법 실습 * VSCode와 Docker를 활용하여 효과적으로 개발하고, 깃허브 collaborator 설정을 통한 협업 관리 실습 * 하이퍼파라미터 튜닝 및 모델 개발 * model.fit() 이외의 방법을 사용하여 세부적인 모델 컨트롤과 디버깅의 수행 * 커스텀 데이터와 트레이너를 구현하고, 모듈화를 통해 코드의 가독성과 재사용성 제고 * TensorFlow의 tf.data와 tf.keras.model을 상속하여 딥러닝 모델 개발 * 캐글 Yogapose 이미지 및 EfficientNetB0를 사용하여 MoveNet annotation 작업 수행 * MLOps 및 모델 배포 * MLOps의 개념과 중요성을 이해하고, 모델의 지속적인 훈련 및 배포 관리 * KerasTuner를 활용하여 하이퍼파라미터 튜닝 수행 * 모델 배포를 위한 TensorFlow Serving API와 tflite 파일 생성 실습. |
| 17~23주차 | |
| 최종 프로젝트 | 개인 아이디어 성장과 기업 주제 기반의 프로젝트 진행 * Project Planning과 PoC * 아이디어를 구현하기 위한 합리적인 프로젝트 계획하기 * 계획의 구현 가능성과 문제점을 파악하고, 주어진 환경 자원에 맞춰 고도화하기 * Project Managing * 팀장/팀원으로서 기간 내에 계획된 프로젝트를 완수하기 위해 시간 관리, 자원 배분 등 매니징 능력 키우기 * Project 실행 및 문제 해결 역량 기르기 * 프로젝트 수행 중에 발생하는 다양한 문제를 해결하기 위한 현실적인 실행 단계 도출 능력 기르기 |
자주 묻는 질문
취소 및 환불 규정
모임/부트캠프의 신청 취소/환불 기간은 지식공유자가 설정한 신청기간과 동일합니다.
모임/부트캠프의 신청 정보 수정 및 취소/환불은 ‘구매내역’에서 할 수 있습니다.
유료 모임/부트캠프의 경우, 24시간이내 설문 내용 미제출시 신청 및 결제내역이 자동취소됩니다.
※ 인프런은 통신판매 중개자이며, 해당 모임/부트캠프의 주최자가 아닙니다.
신청기간이종료됐어요