




해결이 안되네요
678
코딩초보
작성한 질문수 6
1
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager # 크롬 드라이버 자동 업데이트
from selenium.webdriver.common.keys import Keys
import time
import pyautogui
import pyperclip
# 브라우져 꺼짐 방비
chrome_options = Options()
chrome_options.add_experimental_option("detach", True)
# 불필요한 에러 메시지 없애기
chrome_options.add_experimental_option("excludeSwitches", ["enable-logging"] )
service = Service(executable_path=ChromeDriverManager().install())
driver = webdriver.Chrome(service=service, options=chrome_options)
# 웹페이지 주소로 이동
driver.implicitly_wait(5) # 웹 페이지가 로딩될 때까지 5초 기다림
# driver.maximize_window() # 브라우저크기 최대화
driver.get("https://map.naver.com/v5")
search = driver.find_element(By.CSS_SELECTOR,"input.input_search")
search.click()
time.sleep(1)
search.send_keys("제주 게스트하우스")
time.sleep(1)
search.send_keys(Keys.ENTER)
time.sleep(1)
# iframe 안으로 들어가기
driver.switch_to.frame("searchIframe")
# iframe 나올 때
# driver.switch_to_default_content()
# 무한스크롤 하기
## iframe 안쪽을 한번 클릭하기
driver.find_element(By.CSS_SELECTOR,"#_pcmap_list_scroll_container").click()
## 로딩된 데이터 갯수 확인
lis = driver.find_elements(By.CSS_SELECTOR,"li.Fh8nG.D5NxL")
before_len = len(lis)
while True :
# 맨 아래로 스크롤을 내린다.
driver.find_element(By.CSS_SELECTOR,"body").send_keys(Keys.END)
# 페이지 로딩 시간을 준다
time.sleep(1.5)
# 스크롤 후 로딩된 데이터 개수 확인
lis = driver.find_elements(By.CSS_SELECTOR,"li.Fh8nG.D5NxL")
after_len = len(lis)
# 로딩된 데이터 개수가 같다면 반복 멈춤
if before_len == after_len:
break
before_len = after_len
# 데이터 수집
## lis에 모든 가계의 정보가 담겨있음
for li in lis:
# 별점 있는 것만 선택
stars = driver.find_elements(By.CSS_SELECTOR,"span.XGoTG.cN3MU> em")
if len(stars)>0:
# 가계이름
store_name = li.find_element(By.CSS_SELECTOR,"span.place_bluelink.moQ_p").text
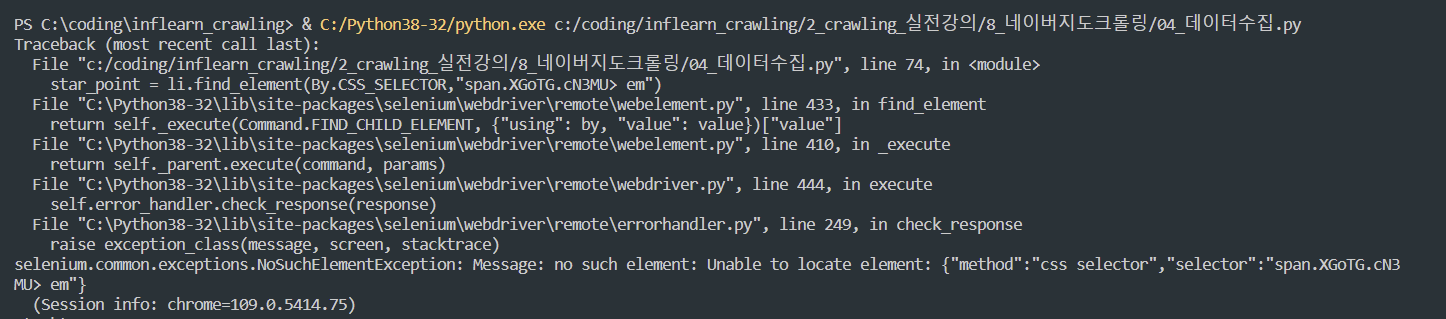
star_point = li.find_element(By.CSS_SELECTOR,"span.XGoTG.cN3MU> em")위에서 store_name까지는 출력이 잘 되는데...star_point를 추가하고 출력하면 아래와 같은 에러가 발생합니다. 아무리 해봐도 해결이 안되네요..
답변 2
셀레니움 환경설정 오류
0
75
2
네이버 로그인 관련
0
340
2
안녕하세요 셀레니움에 대해서 질문
0
103
1
크롤링 연습사이트 문의
0
120
2
선택자 질문
0
89
2
'특정 요소가 나타날 때까지 스크롤' 부분 에러
0
89
2
자동 로그인 질문
0
107
2
44강 제목, 링크
0
112
1
원하는 값이 없을 때
0
104
2
크롤링한 링크가 엑셀로 들어가면 작동이 안되요
0
247
2
셀레니움 PDF자료는 받을 수 있나요
0
108
2
글목록 추출하기
0
109
2
메일 자동화 로그인 중복방지문자해결 오류 및 명시적 대기 질문
0
97
2
강의 노트가 어디에 있는건가요?
0
82
2
강의 커리큘럼 질문
0
111
1
조건문 else 사용하지 않는 이유
0
82
2
셀레니움으로 접근할 수 없는 경우
0
106
2
웹페이지 변경
0
78
2
자바스크립트로 태그 선택 시 질문입니다.
1
72
2
수료증은 어떻게 받나요?
0
128
2
class명을 활용하여 선택자를 만들지 않는 경우..?
0
65
2
드라이버가 안 열려요
0
88
2
이거 해결방법 아시는 분?
0
124
2
네이버 지식인 크롤링..
0
214
2