




네이버 금융 크롤링 질문
574
작성한 질문수 6
안녕하세요. 네이버 금융 크롤링 강의 중 질문이 있어서, 글 남깁니다.
우선 강의를 보면 아래와 같이, 코딩되어있습니다.
soup.select() 코드 중 "onmouseover%" 이 부분 통해서 필요한 정보를 가지고 오고 있습니다.
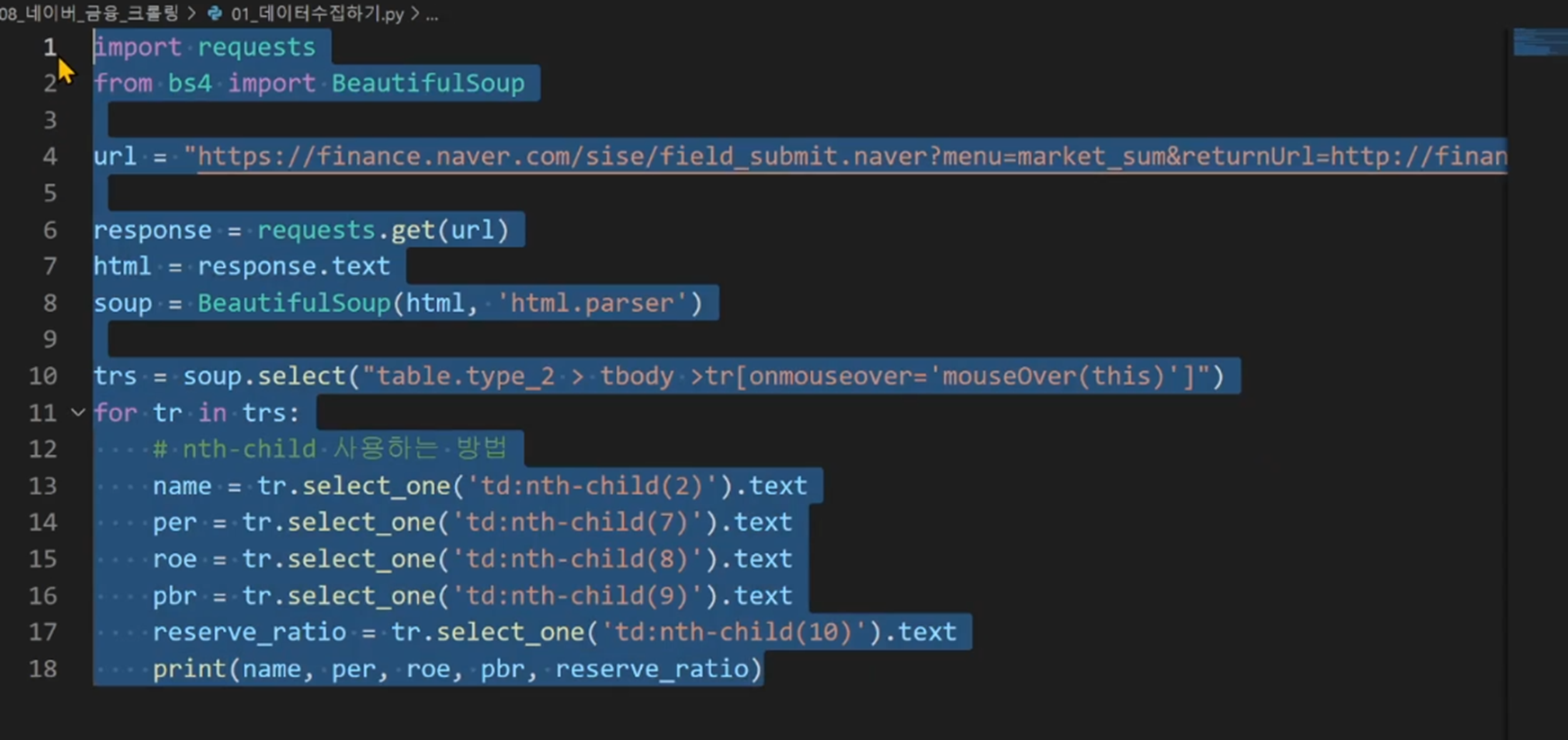
다만, 제가 실습할때는 참고할 수 있는 값들이 좀 달랐습니다.
(아래 캡쳐 화면 참고 부탁드리겠습니다.)
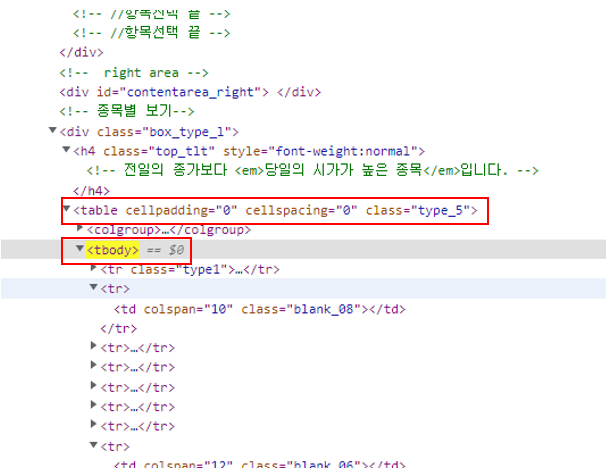
제가 작성한 코드는 가장 아래 코드 참고 부탁드립니다.
우선, 아래와 같이 정보를 가져옵니다.
trs = soup.select("table.type_5 > tbody")-> 이 경우 trs값은 [] 빈 리스트로 찍히고 있는데, 제가 혹시 잘못 가져온걸까요?
그 이후, 빈칸의 경우 td[colspan]값으로 확인해서, 아래 코드로 해당 정보는 지우도록 하였습니다.
td_cols = tr.select("td[colspan]")
for td_col in td_cols:
td_col.decompose()
import requests
from bs4 import BeautifulSoup
url = "https://finance.naver.com/sise/field_submit.naver?menu=lastsearch2&returnUrl=http://finance.naver.com/sise/lastsearch2.naver&fieldIds=per&fieldIds=roe&fieldIds=pbr&fieldIds=reserve_ratio"
response = requests.get(url)
html = response.text
soup = BeautifulSoup(html, "html.parser")
## 변경 코드 ##
trs = soup.select("table.type_5 > tbody")
#trs = soup.select("table.type_5")
print("================================")
print(trs)
print("================================")
for tr in trs:
print("Sdsd")
"""td_cols = tr.select("td[colspan]")
for td_col in td_cols:
td_col.decompose() """
# nth-child 사용하는 방법
name = tr.select_one('td:nth-child(2)').text
per = tr.select_one('td:nth-child(7)').text
roe = tr.select_one('td:nth-child(8)').text
pbr = tr.select_one('td:nth-child(9)').text
reserve_ratio = tr.select_one('td:nth-child(10)').text
print(name, per, roe, pbr, reserve_ratio)
위 말씀드린 과정을 통해서 코드 수행 시 정상적으로 동작하지 않는데, 관련해서 답변 주시면 감사하겠습니다!!
답변 1
0
페이지 URL이 강의와 다른 것 같은 데
확인해 보세요 :)
아래는 정상 동작하는 코드입니다.
import requests
from bs4 import BeautifulSoup
# 적용하기 버튼을 누르면 Network 탭에 첫번째로 request 가 뜬다
URL = "https://finance.naver.com/sise/field_submit.naver?menu=market_sum&returnUrl=http://finance.naver.com/sise/sise_market_sum.naver?&fieldIds=per&fieldIds=roe&fieldIds=pbr&fieldIds=reserve_ratio"
response = requests.get(URL)
html = response.text
soup = BeautifulSoup(html, 'html.parser')
# selector 사용법 중에 특정 속성값으로 추출하는 방법
trs = soup.select("table.type_2 > tbody > tr[onmouseover='mouseOver(this)']")
for tr in trs:
# nth-child 사용하는 방법
name = tr.select_one('td:nth-child(2)').text
per = tr.select_one('td:nth-child(7)').text
roe = tr.select_one('td:nth-child(8)').text
pbr = tr.select_one('td:nth-child(9)').text
reserve_ratio = tr.select_one('td:nth-child(10)').text
print(name, per, roe, pbr, reserve_ratio)파이썬크롤링수업중 예제사이트 연결이 안됩니다.
0
26
3
셀레니움 환경설정 오류
0
83
2
네이버 로그인 관련
0
392
2
안녕하세요 셀레니움에 대해서 질문
0
107
1
크롤링 연습사이트 문의
0
128
2
선택자 질문
0
93
2
'특정 요소가 나타날 때까지 스크롤' 부분 에러
0
91
2
자동 로그인 질문
0
108
2
44강 제목, 링크
0
116
1
원하는 값이 없을 때
0
108
2
크롤링한 링크가 엑셀로 들어가면 작동이 안되요
0
254
2
셀레니움 PDF자료는 받을 수 있나요
0
108
2
글목록 추출하기
0
113
2
메일 자동화 로그인 중복방지문자해결 오류 및 명시적 대기 질문
0
101
2
강의 노트가 어디에 있는건가요?
0
83
2
강의 커리큘럼 질문
0
112
1
조건문 else 사용하지 않는 이유
0
88
2
셀레니움으로 접근할 수 없는 경우
0
113
2
웹페이지 변경
0
86
2
자바스크립트로 태그 선택 시 질문입니다.
1
73
2
수료증은 어떻게 받나요?
0
131
2
class명을 활용하여 선택자를 만들지 않는 경우..?
0
68
2
드라이버가 안 열려요
0
91
2
이거 해결방법 아시는 분?
0
124
2