




[리뉴얼] 파이썬입문과 크롤링기초 부트캠프 [파이썬, 웹, 데이터 이해 기본까지] (업데이트)
프로젝트: 크롤링 + 엑셀 보고서까지 자동으로 만들며 익히는 프로그래밍3 (업데이트)
Gmarket 크롤링 실습문제
509
작성한 질문수 3
안녕하세요,
강의를 잘 따라오면서 열심히 공부하고 있는 수강생입니다.
gmarket 베스트 상품 크롤링 실습을 따라하면서 아래와 같은 오류가 나서 질문드립니다.
크롤링한 데이터 다시 크롤링하기 강의 中
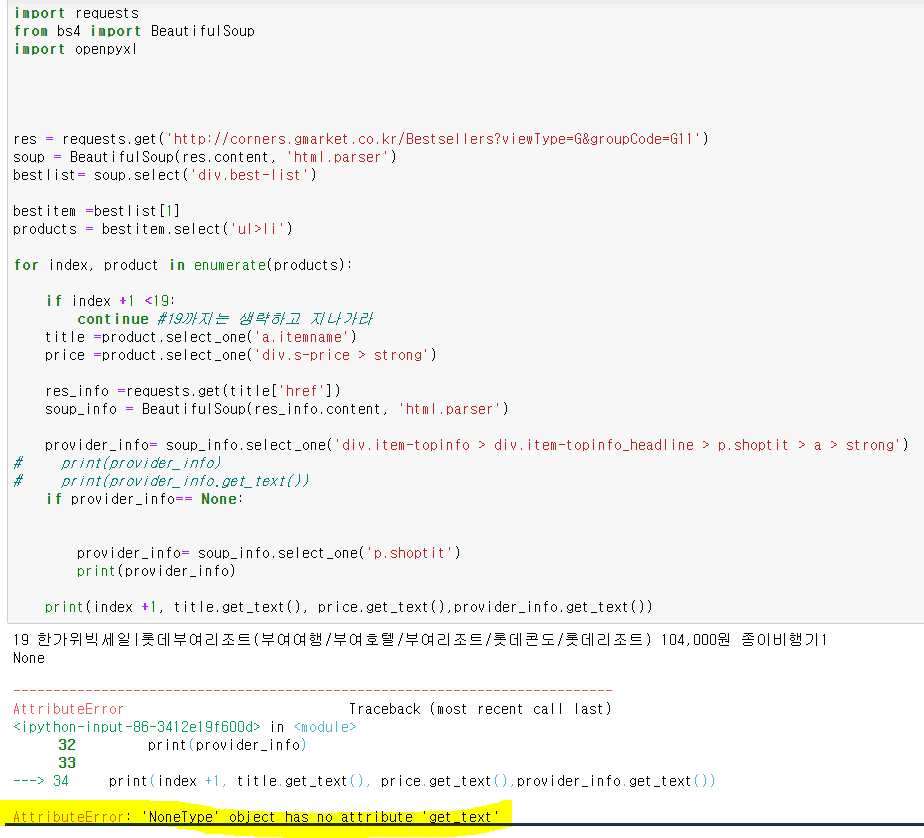
2020.09.23일 기준 20번째 title,price,provider_info를 불러올 때 None값이 나타납니다. 코드의 오류일까요 g마켓의 html구조의 문제일까요
답변부탁드립니다.
답변 1
0
안녕하세요.
공유드린 자료의 코드를 기반으로, 크롤링 예제를 보여드리고 있는데요.
해당 영상에 첨부드린 crawling_crawling.ipynb 코드와 지금 공유해주신 코드와 달라보여요.
첨부해드리고 영상에서 설명드린 코드는 정상적으로 동작해서요. 혹시 제가 착각하는 것이라면, 새로운 질문으로 올려주시면 되겠지만, 카테고리도 달라보이고 (즉, 다른 링크로 크롤링을 하신 듯 하고), css selector 도 강의에서 설명드린 css selector 와 달라보입니다. 확인부탁드려요. 여기까지 들으셨다면, 성공하신 것 같아요. 감사합니다.
import requests
from bs4 import BeautifulSoup
res = requests.get('http://corners.gmarket.co.kr/Bestsellers?viewType=G&groupCode=G06')
soup = BeautifulSoup(res.content, 'html.parser')
bestlists = soup.select('div.best-list')
bestitems = bestlists[1]
products = bestitems.select('ul > li')
for index, product in enumerate(products):
title = product.select_one('a.itemname')
price = product.select_one('div.s-price > strong')
print (title.get_text(), price.get_text(), title['href'])
import requests
from bs4 import BeautifulSoup
import re # 2020.07.25 업데이트 (지마켓 일부 상품 태그 변경, 공지사항 참조부탁드림)
link_re = re.compile('^http://') # 2020.07.25 업데이트 (지마켓 일부 상품 태그 변경, 공지사항 참조부탁드림)
res = requests.get('http://corners.gmarket.co.kr/Bestsellers?viewType=G&groupCode=G06')
soup = BeautifulSoup(res.content, 'html.parser')
bestlists = soup.select('div.best-list')
bestitems = bestlists[1]
products = bestitems.select('ul > li')
for index, product in enumerate(products):
title = product.select_one('a.itemname')
price = product.select_one('div.s-price > strong')
if link_re.match(title['href']): # 2020.07.25 업데이트 (지마켓 일부 상품 태그 변경, 공지사항 참조부탁드림)
res_info = requests.get(title['href'])
soup_info = BeautifulSoup(res_info.content, 'html.parser')
provider_info = soup_info.select_one('div.item-topinfo > div.item-topinfo_headline > p > a > strong')
print (title.get_text(), price.get_text(), title['href'], provider_info.get_text())
33강 9:51 excercise55.
0
35
1
섹션2 - 32강 연습문제 48번 질문
0
41
0
주피터 노트북 사용법 강의 관련
0
45
1
exercise 20. 데이터 구조(리스트)
0
40
0
65강 소리
0
50
1
섹션 5 CSS selector사용해서 클로링하기2의 커리큘럼 일정 부재?
0
71
2
크롤링, 영상을 따라해도 제미나에게 물어봐도 안되요
0
67
1
정규표현식 및 여러 코드 꼭 외워야 하나요?
0
75
1
리스트 함수형도 정수 데이터 받을 수 있나요?
0
73
1
크롤링 관련 질문
0
86
1
문제 답이 없는 버전은 없나요?
0
98
1
requests, BeautifulSoup 임포트 부분에 대해 문의드립니다.
0
108
1
업데이트 강의
0
138
2
선생님 강의중에서 sqlite3 강의를 제공한 강의가 있나요?
0
168
2
연습용 예제 파일
0
99
1
lxml 관련 오류
0
131
1
SAVE Request 창 띄우는 법
0
115
1
포스트맨 사용법이 바뀌어서 강의를 따라가지 못하겠습니다. 2
0
101
1
포스트맨 사용법이 바뀌어서 강의를 따라가지 못하겠습니다.
0
133
1
예제 2, 4, 6에 대한 풀이 방식 질문.
0
115
1
문제 파일
0
100
1
pdf 파일 내 코드 복붙시 공백
0
328
1
데이터 저장 강좌 문의 건
0
116
1
" " 와 ' '의 차이를 알고 싶습니다
0
288
1