




response.css 질문드립니다.
379
작성한 질문수 23
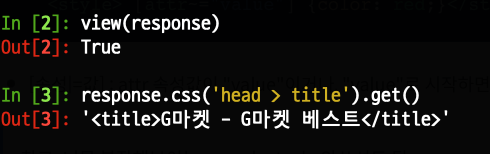
response.css('head > title').get() 명령어를 입력하면
title 밑 meta 부분까지 가져와지는데 왜 그런건가요?

답변 1
1
안녕하세요. 답변도우미입니다.
제 PC에서 금일 해봤는데요. 다음과 같이 정상적으로 title 부분만 가져와지긴 하더라고요. 굉장히 이해하기 어려운 현상이긴 한데요. 터미널 환경이 애매해서, head > title 자체의 인코딩이 다르게 넣어졌지 않았을까 유추도 해봤는데요. 그렇다고 하기에는 앞부분에서는 딱 <title> 부터 나와서 희한하긴 합니다. 가져오는 데이터의 </title> 의 / 이 부분이 인식이 안되서 (역시 인코딩 이슈), 그럴수도 있나 싶기도 한데요. 이것은 HTML 을 parsing 하는 parser 이슈일 수는 있는데, 제 PC 에서는 정상동작을 하니, parser 이슈라고 보기는 어려울 것 같거든요. 아니면 진짜 / 을 인식을 못해서일 수 있는데, 이것이 혹시 터미널을 타는 것이 아닐까 조심스럽게 유추를 해봅니다.
그래서 터미널 환경을 바꿔보시는 것도 한번 시도해보시면 어떠실까요? 예를 들어, 프로그램 -> Anaconda -> Anaconda prompt 터미널을 오픈하신 후에, 해보시는 것도 좋을 것은 같은데요. 사실 이외에는 딱히 유추가 안되네요. 이것도 안되시면, 다른 PC 가 있다면 한번 해보시면 어떠실까요? 또 response.css 를 쉘에서 진행하는 것은 간단한 문법 이해를 위한 부분이라서, 이후에는 scrapy project 로 진행해서, 해당 project 에서 이슈가 없으면 큰 문제는 없습니다.
감사합니다.
[REST API] data의 교환방식 질문
1
679
1
headless chrome 오류 문의
0
1498
1
Selenium 처리 속도 관련 문의드립니다.
0
1964
1
동적 웹사이트에서 element가 선택되지 않는 문제에 관해 질문드립니다
0
696
1
webdriver manager
0
453
1
__init__() got an unexpected keyword argument 'service' 에러 질문드립니다.
1
11726
1
Jupiter NoteBook 파일과 PDF 파일은 어디서 다운로드 받을 수 있나요?
0
458
1
scrapy option질문
1
251
1
scrapy 크롤링 수행시 ffi.callback() 에러가 발생합니다
0
407
1
selenium으로 여러페이지 수집시 질문
0
390
1
연습6 모범 코드: 로그인 시나리오 해보기
0
283
1
셀레니움 문법 업그레이드 , find_element_by_tag_name 오류
3
2842
1
셀레니움 버전 변경으로 인한 코드 변경
0
1293
1
headless error
0
451
1
질문있습니다!
0
470
1
안녕하세요 선생님! 질문있습니다.
0
240
1
selenium&scrapy문의
0
290
1
아래분(phantele47)과 동일한 문제가 발생해서 문의드립니다.
0
926
6
ip 차단을 피하려면 어떻게 해야 하나요?
0
3404
2
start_urls = ['']가 제공해주신 것과 다르게 작동합니다.
1
302
2
json, data = json.loads(response.body_as_unicode()) 부분에 문제가 있는 것 같습니다.
0
616
3
웹크롤링이 상대방 서버에 부담이 될 때는 어떻게 하나요~?
0
694
1
scrapy 윈도우버전의 설명은 따로 없나요??
0
338
1
json 으로 저장이 안되네요
0
2144
1