




선형회귀 예측값 데이터 크기 관련 질문 드립니다!
원본 데이터는 (41,1908)의 shape을 가지고 있고,
train_test_split(X,y, test_size=0.2)함수를 통해서
X_train(32,1907)
X_test(9,1907)
y_train(32,1)
y_test(9,1)의 값을 가지고
lr = LinearRegression()
lr.fit(X_train, y_train_)
y_preds = lr.predict(X_train) 을 수행했습니다.
여기서 문제점이 생겼는데 LinearRegression 모델을 사용해서 전체 row 항목들에 대한 (41,1)의 형태를 가지는 target값 예측을 수행하고싶은데 위와 같은 코드를 수행하면 y_preds는 (9,1)의 형태로 반환 되더군요..
fit으로 학습을 통해 예측된 (41,1) 형태의 새로운 target값을 반환하려면 어떤식으로 코드를 짜야할까요 ..?
답변 1
1
안녕하십니까,
X_test가 (9,1907)이기 때문에 y_preds가 (9, 1) 이 되는 건 당연해 보입니다.
그러니까 y_preds = model.predict(X_test)를 하게 되면 9건의 피처 데이터인 X_test를 예측해보라고 했으니까, 9건의 preds 데이터를 반환하게 됩니다.
y_preds가 (41, 1) 이 되려면 X_test도 (41, 1907)이 되어야 합니다.
감사합니다.
0
답변 주신 내용이 무슨 말씀이신지는 아주 잘 이해 했습니다.
다만 .. 원본 데이터의 행의 갯수가 41개인 dataset에서 train, test로 dataset을 분할하면 X_test가 41이 될 수 없지 않나요?
이런 경우에는 X_test의 형태를 (41,1907)로 만들수 있는 방법이 있을까요?
0
음, 정확히 뭘 하고 싶으신건지 알면 더 도움을 드릴 수 있을 것 같은데...
왜 이런 말씀을 드리냐면,
1. 피처가 아주많은 즉 1907개나 되지만(이미지 데이터 인가요?) 전체 데이터가 41개 밖에 안되면 거의 학습 성능이 안나올것 같은데 어떤 모델을 학습 시키고 싶으신건지....
2. 전체 데이터를 41개에서 더 증가시키면 테스트 데이터도 (41, 1907)이 될 수 있는데 어떤 의미로 (41, 1907)을 만드는 방법을 찾으시는 건지, Synthetic으로 합성할 방법을 물어보시는 건지,
현재 답변은 전체 데이터를 더 수집하면 된다는 답변 정도입니다.
0
조금 더 상세히 설명을 드리자면
위에서 언급한 features는 특정 화학 물질을 구성할 수 있는 분자량, 녹는점, 밀도 등등 여러가지 데이터를 생성해주는 프로그램을 통해서 얻은 descriptor입니다.
불법 의약품을 검출해내기 위해서 41개 의약품에 대해 분석 실험을 수행했습니다.
분석실험을 수행하였을 때 41개의 화학물질은 각각 Retention time이라는 고유의 값을 가지게 됩니다. 머신러닝 모델링을 통해서 직접 실험한 데이터의 Experimenta Retention time과 Multilinear regression 모델링을 통해 예측한 Predict Retention time 을 비교해서 나타내려고 합니다.
그러기 위해서는 두 Retentime의 shape가 같아야 하는데, predict retention time을 얻기 위한 학습을 진행하기 위해서는 training dataset와 test dataset으로 나누어서 학습을 시켜야 하는것으로 알고있는데, 그러면 최종적으 예측 결과값을 41개 화학 물질에 대해서 얻을 수 있는 방법이 있을까요?
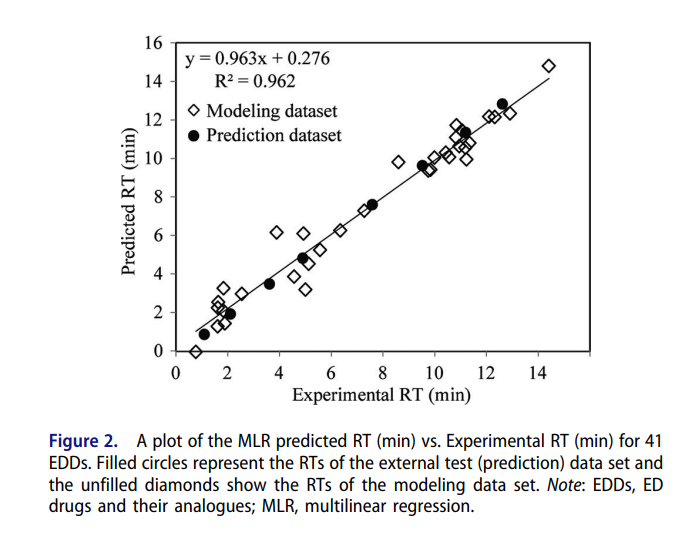
최종적으로 시각화를 통해 표현하고 싶은 형태는 위와 같은 형태입니다.
0
제가 정확히 이해했는지 모르겠지만 위의 그림도 검은색 원으로 표시된 Predicted 데이터가 41개가 아닙니다. 8개 정도 입니다. 아마 그림은 41개중 학습 33개, 테스트 8개 정도로 데이터를 나누어서 수행한 것으로 보입니다. 아니면 다시 글 올려 주십시요.
0
저도 처음에는 선생님이 말씀하신것 처럼 이해를 했었는데
matplotlib으로 시각화 자료를 만들려면 X축과 Y축에 들어갈 데이터의 크기(shape)가 같아야 한다고 오류 문구가 뜨더라구요.
그래서 X축과 Y축에 각각 41개의 list를 넣고 시각화 자료를 생성해야 하며,
위의 그래프는 실제값과 예측값이 완전히 일치하면 기울기가 1인 직선상에 표기가 되고, 실제값과 예측값이 다르면 다를수록 직선에서 멀어진 위치 벡터 값을 갖는 형태로 표현된 그래프인가 생각을 다시하게 됐었네요 ..
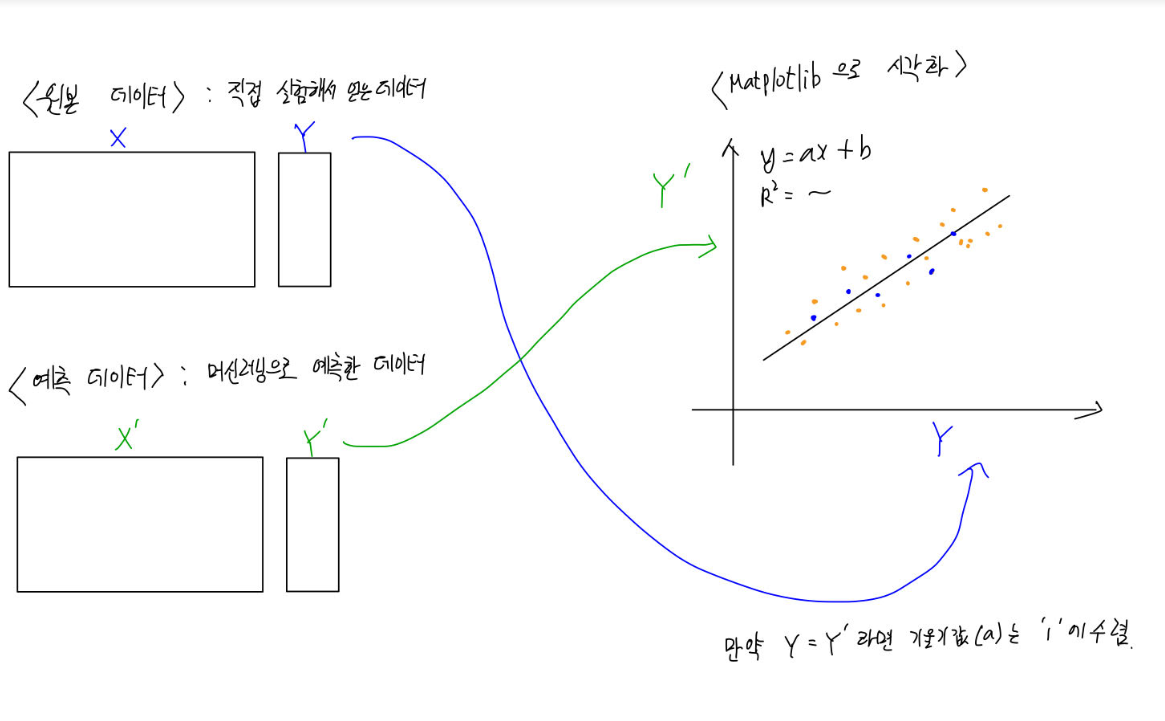
이런식으로 시각화를 시켜야 하는거라고 생각을 했었습니다.
41개 학습중 test_size를 0.2로 설정하면 학습 33개, 테스트 8개로 나누어지는데
이 데이터를 가지고 오류 없이 위와 같은 시각화 자료를 만들려면 어떻게 해야할까요?
0
결국은 시각화가 문제였군요.
정확하진 않지만, 제 생각엔 올려 주신 그림은 학습데이터 33개를 가지고 예측한 결과를 다이아몬드로, 테스트 데이터 8개를 가지고 예측한 결과를 검은색 동그라미로 표시한것 같습니다.
보통은 학습 데이터로 학습된 모델을 다시 학습 데이터로 예측하지는 않습니다. 그런데 그림은 그렇게 한것 같군요. 아래와 같이 코드를 사용해보시지요.
train_test_split(X,y, test_size=0.2)함수를 통해서
X_train(33,1907)
X_test(9,1907)
y_train(32,1)
y_test(9,1)의 값을 가지고
lr = LinearRegression()
lr.fit(X_train, y_train_)
y_preds_train = lr.predict(X_train)
y_preds_test = lr.predict(X_test)
해서 학습 데이터로 예측한 결과 32개와 테스트 데이터로 예측한 결과 9개를 가지고 시각화를 수행하시면 될 것 같습니다.
그러니까 다이아몬드를 그릴때는 X축값은 y_train, Y축값은 y_preds_train 그리고 검은 원을 그릴때는 X축값은 y_test, Y축값은 y_preds_test로 그린 도표가 아닐까 싶습니다.
0
정말 감사합니다 선생님!
덕분에 시각화는 기존 논문과 같은 형태로 만들 수 있게 됐네요
제가 기존에 생각했던 방식으로 y와 y' 값이 일치하는걸 시각화 한게 아니라,
두 개의 서로 다른 그래프를 하나의 그래프상에 겹쳐서 표현한 거였군요 ...
선생님 답변을 보니 문득 저도 궁금증이 생기는데 학습 데이터로 학습된 모델을 다시 학습 데이터로 예측을 하면 생기는 문제점이 있는건가요?
0
해결이 되었다니 다행입니다.
추가적으로.......
y_train 및 y_preds_train의 경우에는 별도의 학습 없이 똑같은 데이터를 썼으니까 직선형태의 산점도가 그려지고
=> 직선 형태의 선분은 아마 0.963x + 0.276 을 그린 것이고 학습 모델이지만 y_train과 y_preds_train도 약간의 오차가 있는 형태의 산점도로 그려집니다.
y_test, y_preds_test의 경우에는 학습시켜서 나온 예상 값으로 그래프를 그리니까 오차가 생기는거구요.
=> y_test, ypreds_test는 조금 더 오차가 큰 형태로 나와야 하는데, 그래프를 보니 오히려 더 학습 데이터 보다 적은 오차가 나와서 조금 의아하군요.
일반적으로 학습 데이터로 학습된 모델을 다시 학습 데이터로 예측을 하지 않습니다. 동일한 문제와 정답을 이미 학습 한 상태에서 동일한 문제를 다시 예측한 평가 결과로는 모델 성능을 평가하지 않습니다.
0
말씀을 듣고보니 예측값 데이터가 그래프로 그려진게 의아하긴 하네요..
마지막 답변도 무슨 말씀 하시는지 잘 이해했습니다 ㅎㅎ 다른식으로 표현하는 방법이 없을지 좀 더 고민을 해봐야겠네요
도움주셔서 정말 감사드립니다!
모델 서빙과 관련된 강좌가 출시되는지 질문드립니다.
0
56
2
안녕하세요 열심히 수강중인 학생입니다
0
93
2
정수 인덱싱
0
86
2
넘파이 오류
0
115
2
11강 numpy의 axis 축 질문 드립니다.
0
109
2
Kaggle 에서 Santander customer satisfaction data 를 다운로드 되지가 않습니다.
0
98
2
Feature importances 를 보여주는 barplot 이 그래프로 안보여져요.
0
81
2
타이타닉 csv 파일이 주피터 화면에 보이지 않습니다.
0
83
2
타이타닉 csv 파일이 주피터 화면에 보이지 않습니다.
0
75
2
5강 강의 오류가 있어요.
0
90
1
실무에서 LTV 관련 모델 선택 질문입니다!
0
81
2
14강 강의 듣는중에 궁금한게 있어서 질문합니다~
0
79
3
파이썬 다운그레이 후 사이킷런 재설치
0
131
2
좋은 강의 감사합니다.
0
82
2
scoring 함수 음수값
0
75
2
6번 강의에 사이킷런, 파이썬, 아나콘다 각각 버전 일치 안 시키고 진행해도 강의 따라가 지나요?
0
108
2
분류 평가 정확도 예측
0
90
2
안녕하세요. 강의 들으면서 업무에 적용하고 싶은 수강생입니다.
0
114
1
카카오톡 채널 있나요
0
119
1
혹시 강의에서 사용하시는 ppt 받을 수 있는건가요
0
195
2
pca 스케일링 관련하여 질문드립니다.
0
109
2
주피터 대신 구글 코랩
0
184
2
강의에서 사용하는 pdf or ppt자료는 따로 없는 건가요?
0
156
2
실루엣 스코어..
0
93
2