




(오류) 섹션5 - 작업유형 1 오류 입니다
177
작성한 질문수 6
답변 2
0
안녕하세요. 지적감사드립니다.
제가 작성한 스크립트를 보니 오타가 맞습니다. df를 두 번 입력했네요.
두 번 입력된 df를 한 번으로 바꾸면 말씀해주신대로 cabin이 맞습니다.
스크립트는 수정해서 올려두었습니다. 그럼 즐거운 하루되세요!
0
안녕하세요. 위에 주신코드를 그대로 입력해보니 저도 그런값이 나옵니다.
확인해보니 제가 드린 코드와 괄호의 위치가 다릅니다.
괄호를 스크립트대로 하면 이상없이 결과값이 나옵니다.
괄호부분을 잘 확인하셔서 다시 한 번 실행을 해보시면 될 것 같습니다.
감사합니다.
원본 : Cabin_ratio <- (sum(is.na(df$Cabin))+sum(df$Cabin=='', na.rm = T))/nrow(df
위의코드 : Cabin_ratio <- sum(is.na(df$Cabin)+sum(df$Cabin=='', na.rm = T))/nrow(df)
0
안녕하세요.
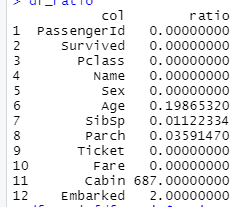
저도 질문자와 같이 cabin의 칼럼에서 가장 높은 수치가 나옵니다.
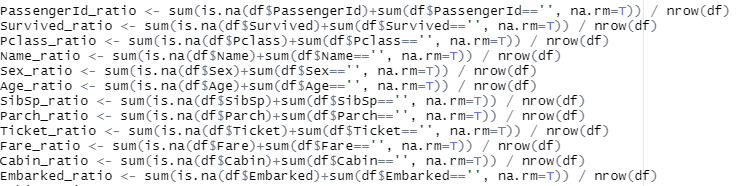
살펴보니 강사님의 스크립트는
Cabin_ratio <- (sum(is.na(df$Cabin))+sum(df$df$Cabin=='', na.rm = T))/nrow(df)
Embarked_ratio <- (sum(is.na(df$Embarked))+sum(df$df$Embarked=='', na.rm = T))/nrow(df)
처음에는 저 두 칼럼만 저렇게 한 이유에 대해 곰곰히 생각해보았는데요.
문자열이라서 그런가 싶었는데, Ticket 칼럼에서는 그렇지 않는 것을 보니
오타인 것 같습니다.
스크립트가 수정되어야 할 것 같네요.
따라서 결론은 Age 칼럼이 아닌 빈값이 많은 (687개)
Cabin 칼럼이 정답이 될 것 같습니다.
확인 부탁 드립니다.
> my = function(x, y){
+ (x + y) / nrow(df)}
>
>
> PassengerId = my(sum(df$PassengerId == '', na.rm = T) , sum(is.na(df$PassengerId)))
> Survived = my(sum(df$Survived == '', na.rm = T) , sum(is.na(df$Survived)))
> Pclass = my(sum(df$Pclass == '', na.rm = T) , sum(is.na(df$Pclass)))
> Name = my(sum(df$Name == '', na.rm = T) , sum(is.na(df$Name)))
> Sex = my(sum(df$Sex == '', na.rm = T) , sum(is.na(df$Sex)))
> Age = my(sum(df$Age == '', na.rm = T) , sum(is.na(df$Age)))
> SibSp = my(sum(df$SibSp == '', na.rm = T) , sum(is.na(df$SibSp)))
> Parch = my(sum(df$Parch == '', na.rm = T) , sum(is.na(df$Parch)))
> Ticket = my(sum(df$Ticket == '', na.rm = T) , sum(is.na(df$Ticket)))
> Fare = my(sum(df$Fare == '', na.rm = T) , sum(is.na(df$Fare)))
> Cabin = my(sum(df$Cabin == '', na.rm = T) , sum(is.na(df$Cabin)))
> Embarked = my(sum(df$Embarked == '', na.rm = T) , sum(is.na(df$Embarked)))
>
> df_ratio = data.frame(col = colnames(df),
+ ratio = c(PassengerId, Survived, Pclass, Name, Sex, Age, SibSp,
+ Parch, Ticket, Fare, Cabin, Embarked))
>
> df_ratio %>% arrange(desc(df_ratio$ratio))
col ratio
1 Cabin 0.771043771
2 Age 0.198653199
3 Parch 0.035914703
4 SibSp 0.011223345
5 Embarked 0.002244669
6 PassengerId 0.000000000
7 Survived 0.000000000
8 Pclass 0.000000000
9 Name 0.000000000
10 Sex 0.000000000
11 Ticket 0.000000000
12 Fare 0.000000000
마지막 질문이될것같습니다 선생님!!
0
306
1
5회 2유형
0
358
1
작업형제2유형 질문입니다.
0
430
1
rmse질문입니다.
0
351
1
제5회 빅데이터분석기사 실기 응시 가이드 질문입니다.
0
460
2
제4회 실기시험 리뷰 작업형2문제
0
435
2
출제예상문제풀이 1번 문제 질문입니다
0
298
1
제4회 실기시험 리뷰 작업형1에서 3번문제 질문입니다.
0
203
1
제4회 실기시험 리뷰 작업형1질문 1번문제
0
282
1
회귀모델구축 질문입니다.
0
290
2
작업형 2유형 질문
0
259
1
작업형 제2유형 질문입니다.
0
187
1
작업형제2유형 질문입니다.
0
242
2
제4회 작업형2 실기 질문입니다.
0
293
2
제4회 작업형2 실기시험 질문입니다.
0
336
2
3회 작업형 1유형 전처리 문제
0
277
1
예상문제 작업2유형 샘플파일이 읽혀지지 않는 문제
0
310
3
실기4 유형2 질문
0
211
1
실기 3회 유형2 세부사항 문의
0
248
2
섹션 4 예상문제
0
204
1
열공중입니다 도와주세요 감사합니다!!
0
182
1
학습 질문있습니다!
0
243
1
덕분에 합격했습니다만..
0
186
1
덕분에 합격했습니다.
1
176
1