




lmplot 연도 표시 문제
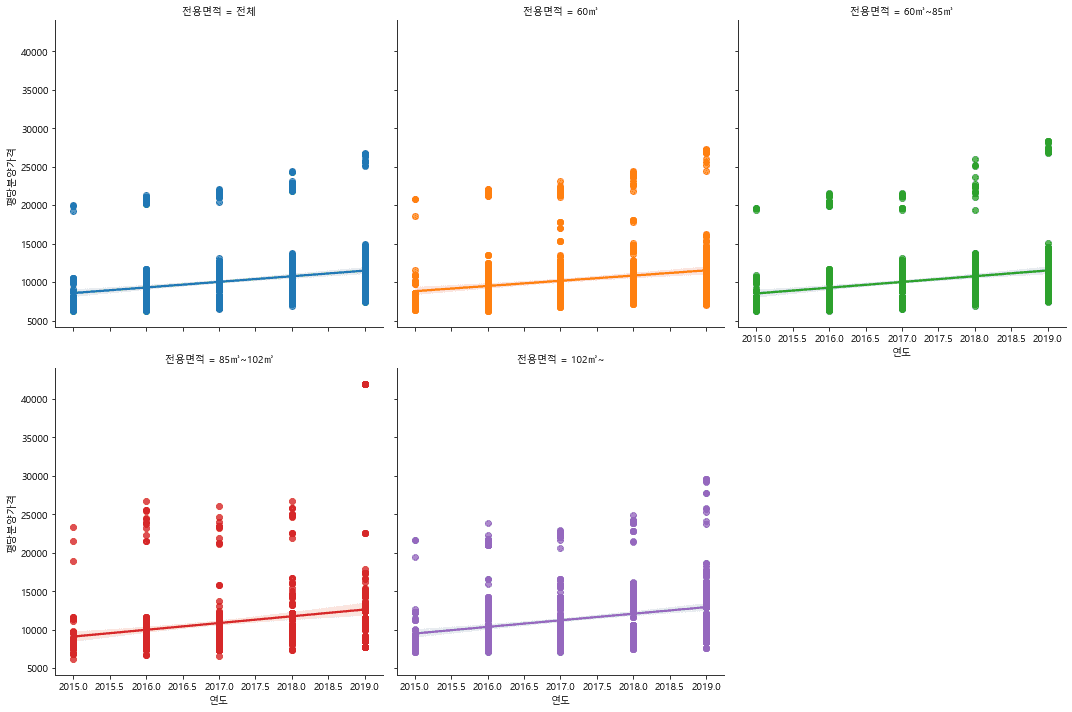
안녕하세요? lmplot에서 아래와 같이 연도가 강의에서 보다 여러 개의 나뉘어 나옵니다. 이 문제를 해결했으면 합니다. 감사합니다.
답변 5
1
답변 감사합니다. 그런데 아직 해결이 되지 않아 다시 질문 합니다. 아래 info결과에 의하면 연도는 int64입니다. 학습을 위한 소스코드에도 lmplot 결과가 같습니다. 이 문제를 해결할 수 있는 코드를 주시면 좋겠습니다. 감사합니다.
<class 'pandas.core.frame.DataFrame'> RangeIndex: 4335 entries, 0 to 4334 Data columns (total 6 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 지역명 4335 non-null object 1 연도 4335 non-null int64 2 월 4335 non-null int64 3 분양가격 3957 non-null float64 4 평당분양가격 3957 non-null float64 5 전용면적 4335 non-null object dtypes: float64(2), int64(2), object(2) memory usage: 203.3+ KB
0
안녕하세요.
영상을 제작했던 버전과 다른 버전의 seaborn 을 설치해서 사용해 봤는데요.
이전과 다르게 올려주신 것처럼 int 형식임에도 소숫점으로 연도가 표기되는것을 확인할 수 있었어요.
버전이 변경되면서 내부 옵션이 변경된 것 같은데요.
lmplot 의 내부는 scatterplot, regplot 으로 되어 있어요.
scatterplot 은 수치vs수치데이터를 표현하는 것을 기본으로 하고요. regplot은 수치vs수치 데이터에 대한 회귀선을 그려줍니다.
lmplot은 regplot의 서브플롯을 그려주는 역할을 하게 됩니다.
그래서 lmplot을 그릴 때 기본 가정은 x, y축이 모두 수치데이터입니다.
하지만 여기에서 "연도"는 숫자로 되어 있지만 "범주형(카테고리)" 형태에 가깝습니다.
그래서 이렇게 범주형 데이터의 scatterplot을 그릴 때는 해당 실습 아래에 있는 swarmplot을 사용합니다.
여기에서 x 축 값에 소숫점이 들어가는 이유는 버전이 변경되면서 x축에 표기되는 값이 변경되었는데요.
소스코드 내부를 보면 x_bins 와 x_estimator 라는 옵션이 있습니다.
x_estimator 옵션을 보면 np.mean으로 label 값을 표현할 때 평균값을 구해서 표현을 하게 되어 있어요.
그런데 평균을 구하다보면 소숫점이 발생하기 때문에 x축에 소숫점이 표현이 된 것이고요.
여기에서 소숫점을 제외하고 그리고자 한다면 가장 간단한 방법은 x_jitter 옵션을 사용하시는 겁니다.
lmplot을 그리게 되면 x 축 값이 같기 때문에 하나의 point 에 여러 점이 찍히게 되는데 그러면 여기에 중복이 되어 점이 찍히기 때문에 점의 갯수가 많은지 적은지 확인이 어렵습니다. 그래서 이걸 조금 흩어지게 그리면 빈도수를 함께 표현할 수 있는게 x_jitter 입니다.
해당 값을 조정해 보시면 몰려있는 값을 흩어지게 표현해서 빈도수를 좀 더 자세히 표현해 보실 수 있습니다.

0
안녕하세요.
강의에서 보면 연도가 int 형식으로 나오는데 올려주신 스크린샷은 float 형식으로 나오고 있어요.
해당 내용에 대한 질문이 맞다면 연도의 데이터 타입을 변경해 주시면 아래와 같은 형태로 보실 수 있어요.
df_last["연도"].astype(int) <= 이렇게 연도를 변경하실 수 있는데 int가 float 형태로 보여질 때는 보통 결측치가 있는 경우가 많아요.
결측치는 np.nan 으로 type(np.nan) 을 출력해 보면 float 으로 타입이 나옵니다.
그래서 다른 데이터에서 실습을 하실 때도 소숫점이 없어서 int 타입으로 변경하고자 하는데 변경이 안 된다면 결측치가 섰여있을 수 있어요.
결측치가 없다면 위와 같이 df_last["연도"].astype(int) 로 타입 변경시에 소숫점이 없게 표기가 됩니다.

패키지 설치 에러 ydata-profiling
0
134
2
자세한 설명 부탁드려요 ㅜ
0
200
2
seaborn 라이브러리 호출하였으나 그래프가 안 그려져요
0
311
2
value_counts와 count 차이
0
392
2
안녕하세요 데이터 최신과 관련해서 문의드립니다.
0
220
3
scatterplot질문
0
133
1
강의 화면이 안나옵니다
0
174
2
4분12초 2013년부터 데이터가 없으면 어떻게하나요?..
0
194
2
에러 메시지
1
311
2
그래프 색이 동일하게 나옵니다.
0
329
2
시각화 라이브러리 비교
0
403
2
주피터 노트북 설치
0
399
1
2. 상가 기술통계 아웃풋 자료에서 오류가 납니다
0
235
1
14. distplot g = sns.FacetGrid(df_last, row="지역명", height=1.7, aspect=4) g.map(sns.distplot, "평당분양가격", hist=False, rug=True); 오류
0
185
1
group by agg function failed 에러
0
697
2
빈도수가 1000개 이상인 데이터를 따로 담을 때 코드 질문 있습니다.
0
296
2
주피터 노트북 실행 했는데 앞에 *가 생기고 결과가 나오지 않아요
0
373
3
get_string함수에서 문자 'nan'
0
205
1
seaborn X축 시작 지점 조정 질의의 건
0
229
1
14강 distplot 질의
0
300
1
nbextension 설치 및 셋팅 후 적용이 안되는 이슈
0
488
1
corr = df.corr() 입력시 오류
1
384
1
keyword grid_b is not recognized
0
342
1
%ls data 매직커맨드 사용시 한글 깨짐
0
306
1