




선생님, 질문 드립니다.
263
작성한 질문수 1
선생님, 안녕하세요.
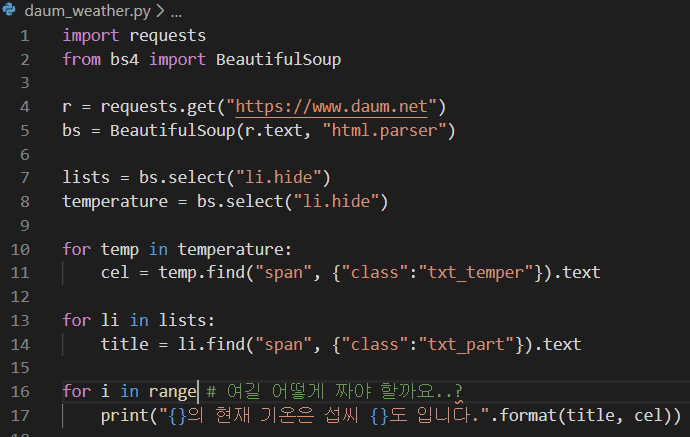
아래 질문에서 아이디어를 얻어 다음에서 날씨를 프린트하는 코드를 어찌어찌 짜보았습니다.
마지막 결과에서 각 지역별 기온을 쭉 프린트하고 싶은데, 어떻게 해야할지 막막해서 질문 드립니다.
for문을 써서 title이나 cel만큼 반복하게 하면 될까요?
답변 1
1
일단 파싱을 하고자 하는 데이터가 하나의 셋트 개념이라면 (여기서는 온도와 지역) 위처럼 따로 cel, title 을 구하게 되면 질문하신것 처럼 각각의 데이터에 접근을 해야하는 문제가 발생합니다. li.hide 를 불필요하게 2번 구할 필요도 없습니다. ^^
import requests
from bs4 import BeautifulSoup
r = requests.get("https://www.daum.net")
bs = BeautifulSoup(r.text, "html.parser")
lists = bs.select("li.hide")
temperature = bs.select("li.hide")
cel_list = []
title_list = []
for temp in temperature:
cel_list.append(temp.find("span", {"class": "txt_temper"}).text)
for li in lists:
title_list.append(li.find("span", {"class": "txt_part"}).text)
if len(cel_list) == len(title_list):
for i, j in zip(cel_list, title_list):
print(i, j)일단 위의 코드가 질문하신 내용에 충실한 답변입니다. cel 과 title 변수대신 cel_list, title_list 라는 리스트형 변수에 값을 모두 추가해서 해당 리스트만큼 반복문으로 도는 내용입니다. zip() 함수는 2개의 리스트를 한개로 압축하여 동일하게 반복시킬 수 있는 기능이 있습니다.
그러나 위의 방식보다는 li.hide 를 한번만 접근해서 반복문을 1회만 사용해서 구하는게 더 좋아 보입니다. (물론 크롤링에 정답은 없습니다.)
import requests
from bs4 import BeautifulSoup
r = requests.get("https://www.daum.net")
bs = BeautifulSoup(r.text, "html.parser")
lists = bs.select("ul.list_weather > li.hide")
for data in lists:
title = data.select_one("span.txt_part").text
cel = data.select_one("span.txt_temper").text
print(title, cel)위의 코드도 한번 확인해보시기 바랍니다. ^^
한글 변수의 한글 상태를 만드는 법?
0
65
1
38강 = 연산자 더하고 빼기
0
74
2
주석처리
0
129
1
함수의 파라미터값 msg
0
171
1
강의자료 이미지 안나옴
0
253
3
강의자료 질문 두번째
0
178
3
강의자료 관련 질문
0
124
1
파이썬 예외 처리 try / except 파일 처리 코드가 실행이 안됩니다.
0
252
1
소수 너무 어려워요
0
254
1
imagefont 함수 사용
0
245
1
pylint
0
365
1
add 함수 문의 ㅠㅠ
0
291
1
형식 문의드립니다.
0
221
1
변수 명을 왜 src, tar로 하셨는지 궁금합니다.
0
621
1
숫자야구 코드를 짜 봤는데 뭔가 이상합니다.
0
264
1
zsh: command not found: pylint
0
282
1
텔레그램 봇 만들기 코드 실행이 안됩니다 박사님..ㅠ
0
557
1
질문드립니다.
1
383
2
list.reverse() 출력에 대해서 질문있습니다.
1
441
1
데코레이터 함수 및 동작시간 질문입니다.~
1
339
2
opencv 사용하면서 궁금한점 (해상도)
1
790
1
질문드립니다.
1
306
1
아래 오류가 뜨면서 vscode가 컴파일이 되지 않는데.. 혹시 왜이럴까요?
1
452
1
크롤링안되는 현상 문의 드립니다.
1
435
1