




정리하면서 질문입니다.
373
작성한 질문수 22
강의 잘보고 있습니다.
Index 부분이 중요하다고 하셨는데 조금 헷갈리네요;;
1)
SELECT *
FROM sys.indexes
WHERE object_id = object_id('accounts');
의 결과 중 index_id 가 (0 = HEAP) (1 = CLUSTERED) (2 <= NONCLUSTERED) 인것같고
CLUSTERED INDEX를 사용하면 (0 = HEAP)대신 (1 = CLUSTERED) NON CLUSTERED INDEX라면
(1 = CLUSTERED)대신 (0 = HEAP)가 사용되는 것 같습니다.
2) DBCC IND('GameDB', 'accounts', N);
N에 index_id를 넣어주게 되는데 CLUSTERED INDEX를 사용하여 index_id가 1부터 시작하게 되었을때도 0을 넣었을때 실행이 됩니다. 반대로 NON CLUSTERED INDEX일때 1을 넣어도 실행이 되는데 그냥 조회용인가요? 결과에 의미가 있나요?
3) DBCC IND('GameDB', 'accounts', 0); 실행시
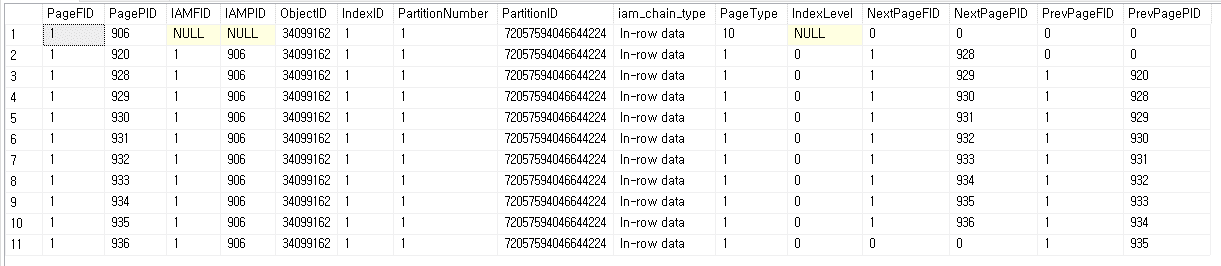
첫 행의 의미는 어떤건가요?
4) NON CLUSTERED ± CLUESTERED INDEX
Page Type의
[ 1은 Data Type이니까 RID를 통해 Heap Table에서 직접 값을 가져오기 ]
[ 2는 Index Type으로 키를.. 값이.. Leaf에 실제 값들이 있고 그 값들의 키의 범위를 루트가 가지고 있다고 보면 될까요? => CLUSTERED에 실제 값이 있고 그 키를 가진 NONCLUSTERED페이지 ]
(CLUSTERED가 있다면 모든 NONCLUSTERED는 CLUSTERED를 참조)
5) 그냥 CLUSTERED INDEX는 값들이 키순으로 정렬되어 사용되구요
6) 실제로 사용할때 한 데이터에서 INDEX를 많이 생성해서 사용하나요? 아니면 목적에 맞는 INDEX만 생성해서 사용하게되나요?
인덱스에 클러스터드에 구조까지 이해하려니까 좀 어려웠지만 일단 생각해보고 이해한거 정리하고 하면서 질문드려봅니다ㅜ
답변 1
3
제가 보기엔 질문들이 너무 세세하고 디테일에 집중되어 있습니다.
DBCC 같은 것은 MSSQL에서 지원하는 특수 명령어라 딱히 중요하지 않고,
그럼에도 정말 궁금하시다면 구글링을 해보거나 MSDN 문서를 참고하시면 됩니다.
Clustered vs NonClustered의 차이는
실제 데이터가 그 순서로 정렬되어 저장되어 있는지 (사전처럼)
아니면 따로 색인을 외부에서 만들어서 관리하는지 (책 뒷 색인처럼)이고
사실 이 부분은 자료구조 B* Tree를 공부해야 정확히 이해할 수 있기 때문에
자료구조 기초가 없다면 그냥 '빠르게 찾을 수 있게 된다'라고 이해하고 간략하게 넘어가는게 좋습니다.
실제 Index가 걸려 있는 칼럼을 조건으로 찾을 때, 아주 빠르게 찾을 수 있다는 것이 중요합니다.
실전에서는 우리가 어떻게 데이터를 찾을 것인지 필요 사양에 따라 Index를 설계하게 됩니다.
인덱스를 마냥 많이 건다고 좋은게 아니라 그렇게 되면 데이터가 추가/삭제될 때
인덱스를 유지하기 위한 부가적인 연산/수정이 많이 일어나게 됩니다.
따라서 사양상 '꼭' 필요한 애들 위주로만 걸어줘야 합니다.
DBA라는 전문 직군이 따로 있을 정도로 DB는 복잡하고 케바케로 다른 경우가 많아
컨텐츠 개발자 혹은 서버 개발자 입장에서는 그냥 러프하게만 이해하면 됩니다.
최신 하드웨어에서 SQL Express 설치에러 해결법
0
125
1
인벤토리 테이플 데이터가 엄청 많아지면
0
117
2
DISTINCT의 행 개수와 COUNT(DISTICNT )의 결과가 왜 차이나는지 궁금합니다.
0
122
1
conect시 신뢰할 수 없는 기관에서 인증서 발급 오류 뜨시는분들
0
344
1
PRIMARY KEY와 CLUSTERED INDEX의 차이
0
349
1
락과 트랜잭션 격리수준 차이는 뭔가여?
0
549
1
외래 키 질문이 있습니다.
0
399
1
게임 프로젝트와 연동하는 강의 내용은 포함되어 있지 않는 건가요?
0
580
1
윈도우 함수는 SELECT에서만 사용가능한가요?
0
462
1
데이터 베이스가 만들어지지 않을 때
9
821
3
sql 강의 관련 질문
0
696
1
강의내용 외의 질문이 있습니다
0
596
1
sinter
0
370
1
테이블 여러개랑 조인
0
383
1
서버 컴퓨터 스펙에 따라서 성능 차이가 심한가요?
0
804
1
Non-Clustered 에서 clustered index 추가시
0
449
1
UNIQUE INDEX와 PRIMARY KEY의 기능적차이
0
598
1
Part5: 데이터베이스_ SSMS 입문 테이블작성 오류에관하여
2
916
2
인덱스의 저장 방식에 대해서 질문이 있습니다!
1
557
1
MSSQL vs AWS
0
368
1
join 관련 질문입니다.
0
295
2
Inner Join 질문
0
312
1
데이터베이스 원리는 CAP이론을 비유하여 설명하신 건지 궁금합니다.
1
407
0
CLUSTERED INDEX
1
308
1