




넷플릭스 크롤링
761
작성한 질문수 7
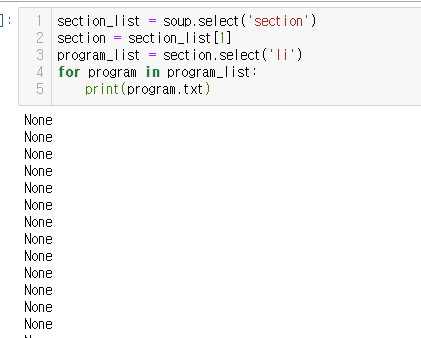
넷플릭스 크롤링 시스템 만들 때 섹션별로 영화 제목 따내는 거는 아무 오류 없었는데 섹션리스트 중에서 첫번째 섹션에서 프li태그 이용해서 프로그램 이미지랑 제목 html로 따낼 때
section_list = soup.select('section')
section = section_list[1]
program_list = section.select('li')
for program in program_list:
print(program.txt)
이렇게 했더니 결과가 None으로 여러개가 계속 나와요 뭐가 문제일까요??
답변 2
1
너무 늦은 시간인데 빠른 답변 감사합니다!! 고3인데 학교에서 한 활동 중 웹 크롤링으로 한 활동이 있었는데 기억이 잘 안나서 공부를 어떻게 다시해야될지 찾고있었는데 이 강의를 발견하고 나서 너무 든든하고 이해도 잘하고 있습니다!! 끝까지 완강하고 후기 더 남기겠습니다. 질문 생기면 또 할게요!!
0
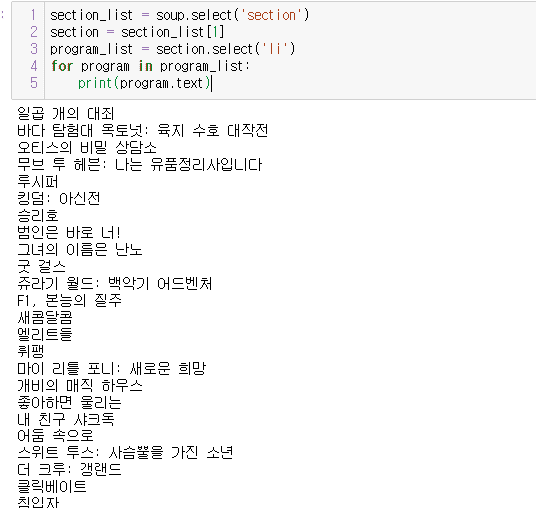
안녕하세요.
마지막 print 명령어에서
program.txt 로 되어있는 부분을
program.text
으로 변경하시면 될 것 같네요.
[기존]
[변경후 : txt → text ]
수업노트가 어디에 있나요?
0
13
1
[긴급요청] 28강 동영상 전체에 오디오가 잘못들어가있습니다.
0
11
1
실제 계좌 잔고 및 테스트중에
1
27
4
Replit UI 변경으로 인한 실습 진행 문의
1
13
1
29강 5:00
0
19
2
설치 및 설정 가이드 노션 자료는 없나요 ?
0
18
2
실기시험 제출관련
0
145
2
6.20 작업형 2 과적합
0
154
3
install까지 설치 하였는데 start 가안됩니다.
1
26
1
8분54초 테이블 내용 문의
0
22
1
코딩팡 장업형2 베이스 라인 인코딩 종류 질문
0
47
2
multi_tool_agent.py 에서 arxiv tool 에러
0
18
1
로지스틱회귀, 회귀
0
47
2
가상 환경과 차이 도커 질문
0
24
1
자료 다운로드 위치 확인 부탁드립니다.
0
15
1
회귀 문제를 풀때 질문입니다.
0
54
1
불균형 처리 후 성능이 더 낮아졌다면,
0
61
2
실기 체험 제2유형 에러 문의
0
61
1
LIGHTGBM 으로 하면 pred값이 소수점 6자리까지 나오는게 맞나요
0
49
2
안녕하세요
1
37
3
3번문제 등분산 가정
0
46
2
크롤링 페이지 접속 에러
0
532
1
넷플릭스 크롤링 데이터 엑셀파일저장
0
650
1
유튜브 크롤링 방법
0
395
1