




Ridge, Lasso vs. 데이터 표준화, Stepwise 관련 질문
강사님, 좋은 강의 그리고 좋은 답변 항상 감사드립니다.
규제가 들어가는 선형회귀 방법과 통계적 접근 방법에서의 회귀분석 간의 차이를 이해해 보고자 질문을 드리고 있습니다.
1. Ridge & 데이터 표준화 관련 질문
Ridge 는 결국 회귀계수가 상대적으로 큰 변수의 민감도를 줄임으로써 해당 변수의 값이 좀 많이 달라지는 new sample 들의 추정치에 대한 overfit risk 를 줄이는 방법으로 이해가 되는데요,
종속변수와 의 상관성을 가지는 변수 중에서도 특히 value 의 scale 이 다른 변수에 비해서 월등히 작은 독립변수의 경우 .. 예를들어 NOX 의 경우 Price 와 상관관계가 있으면서도 scale 이 다른 독립변수에 비해 월등히 작다 보니 회귀 계수가 반대급부적으로 커지다 보니 Ridge 에 의해 패널티를 받아 버리는 상황이 생기는 것이 아닐까.. 생각도 드는데요, 이런 경우에는 처음부터 Ridge 를 적용하기 보다는 회귀분석을 하기 전에 데이터 표준화나 Min-Max scaling 등을 통해서 사전처리를 한 다음에 그럼에도 불구하고 회귀 계수가 아주 큰 경우라면 Ridge 를 적용해 보는 순서로 분석하는 것이 필요하지 않을지.. 문의드립니다.
(Scale 이 큰 변수가 억울하게(?) 페널티를 받는 상황이 생기지 않을까.. 생각이 들어서 입니다.^^;;)
그리고 scale 이 모두 동일한 상태인 경우일지라도, 기여도가 dominant 하게 큰 인자의 기여도를 강제적으로 낮추는 best fit 모델을 찾아내는 방법이 Ridge 라면 , 물리적으로 기여도가 높은 인자에 대한 페널티가 주어짐으로 인해 모델 성능 (R2 나 MSE 기준 ) 이 저하될 가능성이 있는 것은 아닐지.. 도 문의드립니다.
2. Lasso vs. Stepwize 비교 질문
Lasso 을 적용하면 결국 불필요한 변수의 회귀계수를 0으로 만들어 해당 변수를 제외시키는 결과를 얻게 되는데요, 통계적 회귀분석 방법 중 p-value 등을 기준으로 변수를 포함했다 제외했다 해 가면서 adjusted R2 value 등을 극대화하면서도 유의성이 떨어지는 변수들을 오차항에 모두 pooling 시키는 stepwise 방법이 결국 Lasso 와 유사한 방법이라고 이해하면 될지.. 문의 드립니다.
답변 3
1
안녕하십니까
잘 보고 계시다니 저도 기쁩니다.
1. 네, Nox와 scaling 부분에 대해서 말씀하신 부분이 일정 부분 맞습니다.
Nox의 경우 상대적으로 값이 커서 회귀 계수가 커지는 경향이 있습니다.
원래는 MinMaxScaling이나 StandardScaling을 먼저 적용한 후에 Ridge를 적용하려 했으나, scaling을 적용한 후에 학습 모델이 오히려 성능이 약간 떨어지는 현상이 발생했습니다. 우리가 선형 회귀(ridge, lasso를 포함한)를 학습시킬 때는 일반적으로 feature들을 동일한 scaling으로 변환 후에 모델을 학습 시키라는 것이 정설입니다만,,, 실제로 사이킷런으로 선형회귀를 테스트 해보면 scaling 적용 전/후가 큰 차이가 없거나, 오히려 성능이 조금 저하되는 경우가 있습니다. 물론 이는 데이터 세트의 특성에 따른 것이라고 생각됩니다.
때문에 해당 모델에서는 scaling을 맞추지 않았습니다. 그리고 알파값에 따른 회귀 계수 값도 그렇게 명확하게 구분되지 않아서 scaling을 적용하지 않고 실습 코드를 만들었습니다.
2. 제가 stepwise regression을 몰라서 검색을 해보았습니다. 근데 stepwise regression은 lasso와 기본적으로 큰 차이가 있는데, lasso는 모델을 학습할 때 회귀 계수의 복잡도등을 감안하여 특정 feature의 회귀계수를 아예 0으로 만들어 지도록 비용함수 기반에서 모델의 회귀계수 parameter가 학습이 되는 것입니다. 즉 학습과정에서 회귀 계수 parameter를 0으로 만들어서 해당 feature를 제외합니다.
하지만 stepwise는 일단 모델을 학습 시킨 후 feature 들을 제거하거나 추가해가면서 모델 성능이 나아지는지를 확인하면서 최종 feature 들을 선택합니다.
가령 stepwise backward elimination은 모든 feature 들로 일단 모델을 학습한 뒤에 하나씩 feature 들을 제거해 나가면서 성능이 향상되는지를 판별하여 최종 feature들을 선택합니다(사실 이 방식은 Feature selection에 더 유사한 방식입니다).
때문에 학습 과정에서 feature의 회귀 계수를 0으로 만드는 lasso와는 근본적인 차이가 있습니다.
감사합니다.
0
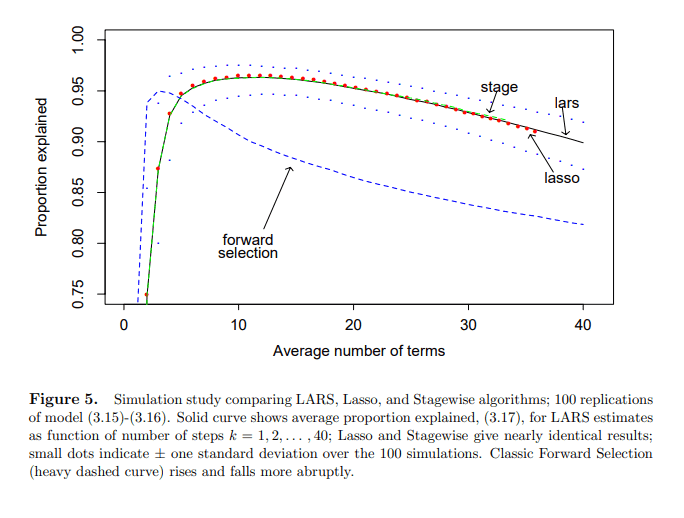
추가적으로 study 를 하다보니 Lasso 와 Stepwize 를 비교하는 내용이 일부 포함된 논문이 있어서 공유드립니다. (Stagewize 는 단어의 어감상 stepwize 와 동의어로 판단했습니다.)
sklearn 의 load_diabetes 데이터셋을 처음 사용한 논문인 듯 한데... 상세히 이해한 것은 아니지만 대략적으로 보면... 알고리즘은 상이하지면 결과는 상당히 유사하다고 합니다. (forward selection 의 경우는 차이가 나지만 Stepwize 는 거의 유사함)
참고해 주세요~~
https://web.stanford.edu/~hastie/Papers/LARS/LeastAngle_2002.pdf
모델 서빙과 관련된 강좌가 출시되는지 질문드립니다.
0
57
2
안녕하세요 열심히 수강중인 학생입니다
0
96
2
정수 인덱싱
0
88
2
넘파이 오류
0
118
2
11강 numpy의 axis 축 질문 드립니다.
0
110
2
Kaggle 에서 Santander customer satisfaction data 를 다운로드 되지가 않습니다.
0
99
2
Feature importances 를 보여주는 barplot 이 그래프로 안보여져요.
0
84
2
타이타닉 csv 파일이 주피터 화면에 보이지 않습니다.
0
84
2
타이타닉 csv 파일이 주피터 화면에 보이지 않습니다.
0
76
2
5강 강의 오류가 있어요.
0
90
1
실무에서 LTV 관련 모델 선택 질문입니다!
0
82
2
14강 강의 듣는중에 궁금한게 있어서 질문합니다~
0
83
3
파이썬 다운그레이 후 사이킷런 재설치
0
131
2
좋은 강의 감사합니다.
0
90
2
scoring 함수 음수값
0
81
2
6번 강의에 사이킷런, 파이썬, 아나콘다 각각 버전 일치 안 시키고 진행해도 강의 따라가 지나요?
0
109
2
분류 평가 정확도 예측
0
95
2
안녕하세요. 강의 들으면서 업무에 적용하고 싶은 수강생입니다.
0
114
1
카카오톡 채널 있나요
0
121
1
혹시 강의에서 사용하시는 ppt 받을 수 있는건가요
0
197
2
pca 스케일링 관련하여 질문드립니다.
0
119
2
주피터 대신 구글 코랩
0
187
2
강의에서 사용하는 pdf or ppt자료는 따로 없는 건가요?
0
157
2
실루엣 스코어..
0
99
2