




SCRAPY에서 ITEM 항목이 변하는 경우, 어떻게 하면 자동으로 반영 되는지 문의드립니다.
176
작성한 질문수 4
- 학습 관련 질문을 남겨주세요. 상세히 작성하면 더 좋아요!
- 먼저 유사한 질문이 있었는지 검색해보세요.
- 서로 예의를 지키며 존중하는 문화를 만들어가요.
- 잠깐! 인프런 서비스 운영 관련 문의는 1:1 문의하기를 이용해주세요.
안녕하세요, SCRAPY에서 ITEM 항목이 변하는 경우, 어떻게 하면 자동으로 반영 되는지 문의드립니다.
예를 들어서
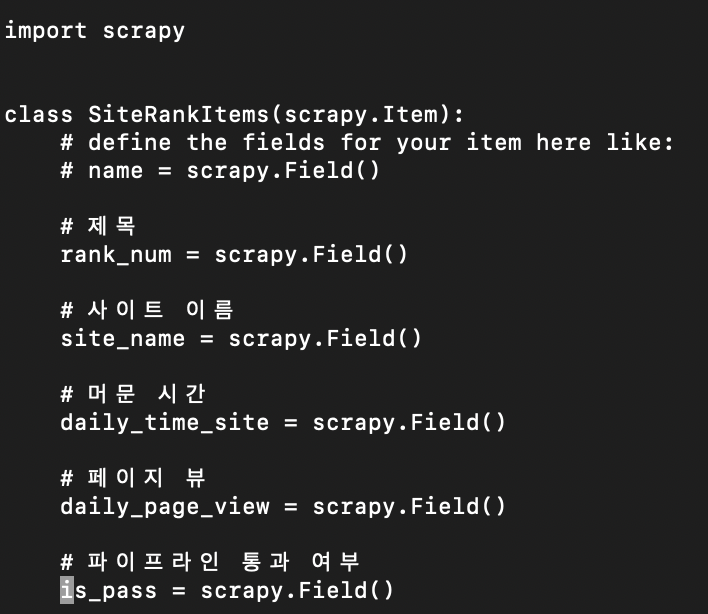
아이템을 위와 같이 정의하고 아래와 같이 스파이더를 코딩할 때
item['rank_num'], item['site_name'] ....에서 rank_num 이나 site_name이 변하는 경우, 변할때 마다 일일이 다 변경해줘야 되는지요
아니면 화면에서 위와 같은 항목이 변경될때 자동으로 반영되게 하는 방법은 없는지 문의드립니다.
감사드리며
1 |
# -*- coding: utf-8 -*- |
답변 1
0
코딩을 잘 따라 한 것 같은데 오류가 발생하는 것 같습니다
0
641
1
scrapy를 jupyter 환경에서 할 수 있나요
0
372
1
[실전 크롤링: scrapy 크롤링 팁] 질문있습니다.
0
326
1
[실전 크롤링: 지마켓 크롤링하며, scrapy 실전 활용법 익히기1] 5분50초쯤 질문
0
232
1
[강력/최신 크롤링 기술: Scrapy 로 지마켓 크롤링하기1] 관련 질문
0
285
1
xml을 parsing할때 <을 < 로 인식합니다.
0
340
1
pipelines.py에서 process_item내에서 print문이 작동을 하지 않네요 ㅠ
0
295
3
PhantomJS 문의
0
305
1
selenium 문의
0
337
1
브라우저 제어해서 크롤링하기 - 처음강의 마지막부분 문의
0
3013
1
on error 해결 방법 질문
0
365
1
[팁] 윈도우 cmd 커맨드
0
355
1
[팁]Chrome User Agent 아는법
0
334
1
실전 크롤링: 브라우저를 제어해서 트위터 사이트 로그인 하기 질문
0
258
1
동영상 강의 만드실 때 사용한 툴을 알려주실 수 있을까요?
0
249
1
CSS Selector 에서 질문이 있습니다.
0
446
2
pip install scrapy 오류
0
496
1
셀레니움 실행불가
0
1593
1
실전 크롤링: XPATH와 Selenium 활용해서 페이스북 로그인 하기 에서 질문이 있습니다.
0
231
1
언제 get_text()를 사용하고 또 언제 .text를 사용하나요?
0
300
1
강의교안자료 받을수있을까요?
0
271
1
[강의 9:27관련 질문] price, title 열 위치
0
162
1
div에 있는 클래스가 2개이면 어떻게 하나요?
0
371
1
css 셀렉터에 대해 질문이 있습니다.
0
154
1